Linux 常用工具命令
索引
- grep 搜索字符
- find 查找文件
- ls 显示文件
- wc 统计字数
- uptime 机器启动时间+负载
- ulimit 用户资源
- scp 远程文件拷贝
- rsync 文件同步
- dos2unix 和 unix2doc 转换换行符
- curl HTTP协议测试
- sed
- awk
linux 常用工具命令
基础命令
grep 搜索字符
grep 命令用于在文件中执行关键词搜索,并显示匹配的效果。部分常用选项
| 参数 | 作用 |
|---|---|
| -c | 仅显示找到的行数 |
| -i | 忽略大小写 |
| -n | 显示行号 |
| -v | 反向选择,仅列出没有关键词的行,v是invert的缩写。 |
| -r | 递归搜索文件目录 |
| -A n | 打印匹配行的后面n行,A是after |
| -B n | 打印匹配行的前面n行,B是before |
| -C n | 打印匹配行的前后n行,相当于 -A n -B n |
在auth.log文件中查找login关键字
grep login auth.log
在多个.log文件中搜索
grep login *.log
递归目录下所有文件,在.log文件中搜索
grep -r login *.log
不包含login的行
grep -v login auth.log
查找并显示行号
grep -n login auth.log
对login忽略大小写进行搜索
grep -i login auth.log
打印出包含login的行,打印出行号,并显示前后3行,并忽略大小写
grep -C 3 -i -n login auth.log
find 查找文件
通过文件名查找文件的所在位置,文件名查找支持模糊匹配
find [指定查找目录] [查找规则] [查找完后执行的action]
常用的查找规则:
文件名 -name 、-iname
find . -name syslog在当前目录下(包含子目录)查找syslog文件find . -iname syslog忽略文件名称大小写find /etc -name *.conf查找/etc目录下.conf结尾的文件
深度 -maxdepth、-mindepth
find /etc -maxdepth 3 -name *.conf最大子目录深度为3find /etc -maxdepth 2 -mindepth 2 -name *.conf只在第二层中查找
文件大小 -size
find /mnt -size 20K查找/mnt目录下大小近似20K的文件find /mnt -size -20K小于20K的文件find /mnt -size +20K大于20K的文件
文件类型 -type,f为文件,d为目录,l为链接文件
find /mnt -type f查找/mnt目录下的文件find /mnt -type d查找目录
文件时间 -atime最后访问时间(单位天),-mtime文件内容最后修改时间(单位天),-ctime 文件权限、拥有者、所属组、及文件内容最后变化的时间(单位天)。同理 -amin -mmin -cmin单位是分钟
find /etc -mtime -2查找/etc目录2天内修改过的文件find /tmp -mmin +60查找/tmp目录最后修改时间超过60分钟的文件
其他属性
find /tmp -empty查找/tmp目录下的空文件和空目录find /tmp -type d -empty/tmp目录下的空目录find /etc -type f -executable在/etc目录下搜索具有可执行权限的文件find /etc -type f -perm 755在/etc目录下搜索权限为0755的文件find /home -type f -user root在/home目录下查找属主为root用户的文件find /home -type f -group guest在/home目录下查找属组为guest的文件
常用的执行action
-
-ls按照ls -l格式显示搜索到的文件find /tmp -type f -ls # 使用 ls -l 格式显示/tmp下面的文件 -
-print没有其他action时,默认值,显示搜索到的文件 -
-delete删除搜索到的文件或目录,目录要为空目录才能被删除,空目录会被递归删除(直到被搜索的目录被删除)find /tmp/xxx -type d -empty -delete # 删除/tmp/xxx目录下的空目录(如果到最后/tmp/xxx也为空,则也会被删除) -
-exec执行子命令,使用{}代替搜索到的文件名字,命令需要;结尾,;应该加上\进行转义。find /etc/redis -name *.conf -exec cp {} /tmp/redis \; # 将/etc/redis下的.conf文件全部拷贝到/tmp/redis目录下。
更多用法参考:https://blog.51cto.com/alick/1775266
ls 显示文件
-l按行显示详情-h人性化的显示文件大小-t按修改时间排序,需要结合-l使用-r反序-R递归遍历子目录-n显示用户id和组id(gid)-f不排序显示,目录下文件较多时,效果很好。
按时间排序显示,最近修改的文件在前面
ls -lt
按时间逆序显示,最老的文件在前面
ls -lrt
wc 统计字数
wc命令用于计算字数。 利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
-l仅显示文件行数-c仅显示字节数-w仅显示单词数
默认用法
wc /etc/passwd
34 50 1817 /etc/passwd # 34是行数,50是单词数,1817是字节数
统计/var/log/message行数
wc -l /var/log/message
uptime 机器启动时间+负载
查看机器的启动时间、登录用户、平均负载等情况,通常用于在线上应急或者技术攻关中,确定操作系统的重启时间。
$ uptime
16:18:06 up 9 days, 6:35, 10 users, load average: 2.01, 2.01, 2.00
解释:
16:18:06是当前系统时间。up 9 days, 6:35是距离开机9天,6小时,35分钟。10 users在线用户数量。load average: 2.01, 2.01, 2.00最近1分钟,5分钟,15分钟的系统负载情况。
系统的平均负载是指在特定的时间间隔内队列中运行的平均进程数。如果一个进程满足以条件,它就会位于运行队列中。
- 它没有在等待I/O操作的结果。
- 它没有主动进入等待状态(也就是没有调用’wait'相关的系统API )
- 没有被停止(例如:等待终止)。
如果每个CPU内核的当前活动进程数不大于3的话,那么系统的性能还算可以支持。
如果每个CPU内核的任务数大于5,那么这台机器的性能有严重问题。
如果你的linux主机是1个双核CPU的话,当Load Average 为6的时候说明机器已经被充分使用了。
负载说明(现针对单核情况,不是单核时则乘以核数):
load<1:没有等待load==1:系统已无额外的资源跑更多的进程了load>1:进程都堵着等待资源
注意:
load < 0.7时:系统很闲,要考虑多部署一些服务0.7 < load < 1时:系统状态不错load == 1时:系统马上要处理不多来了,赶紧找一下原因load > 5时:系统已经非常繁忙了
不同load值说明的问题
1分钟 load >5,5分钟 load <3,15分钟 load <1:短期内繁忙,中长期空闲,初步判断是一个抖动或者是拥塞前兆1分钟 load >5,5分钟 load >3,15分钟 load <1:短期内繁忙,中期内紧张,很可能是一个拥塞的开始1分钟 load >5,5分钟 load >5,15分钟 load >5:短中长期都繁忙,系统正在拥塞1分钟 load <1,5分钟Load>3,15分钟 load >5:短期内空闲,中长期繁忙,不用紧张,系统拥塞正在好转
补充:
查看cpu信息:cat /proc/cpuinfo
直接获取cpu核数:grep 'model name' /proc/cpuinfo | wc -l
ulimit 用户资源
Linux系统对每个登录的用户都限制其最大进程数和打开的最大文件句柄数。为了提高性能,可以根据硬件资源的具体情况设置各个用户的最大进程数和打开的最大文件句柄数。可以用ulimit -a来显示当前的各种系统对用户使用资源的限制:
root@debian:~# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 15096
max locked memory (kbytes, -l) 65536
max memory size (kbytes, -m) unlimited
open files (-n) 65535
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 15096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
设置用户的最大进程数
ulimit -u 1024
设置用户可以打开的最大文件句柄数
ulimit -n 65530
scp 远程文件拷贝
secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。
scp命令是Linux系统中功能强大的文件传输命令,可以实现从本地到远程,以及从远程到本地的双向文件传输,用起来非常方便,常用来在线上定位问题时将线卜的一些文件下载到本地进行详查,或者将本地的修改上传到服务器上
常用方式:
下载172.16.1.15的/home/test.txt到本地目录下
scp root@172.16.1.15:/home/test.txt .
上传文件到远程/tmp下
scp test.txt root@172.15.1.15:/tmp/
下载整个test目录到本地
scp -r root@172.15.1.15:/tmp/test .
上传整个test目录到远程
scp -r test root@172.15.1.15:/tmp/
如果ssh端口不是默认的22,使用-P指定端口
scp -P 1022 test.txt root@172.15.1.15:/tmp/
rsync 文件同步
可以方便的同步目录,注意所有的目录都需要/结尾
将AAA目录下的所有文件同步到BBB目录下
rsync -av AAA/ BBB/
测试,而不是实际执行,使用-n
rsync -avn AAA/ BBB/
注意目录结尾加/和不加/的区别,如下:
$ rsync -avn AAA/dir1 BBB/ # 将dir1目录同步到BBB目录下,dir1目录将被拷贝到BBB目录下
sending incremental file list
dir1/
dir1/dir11/
dir1/dir11/file111.txt
sent 122 bytes received 27 bytes 298.00 bytes/sec
total size is 12 speedup is 0.08 (DRY RUN)
$ rsync -avn AAA/dir1/ BBB/ # 将dir1目录下的所有文件同步到BBB目录下
sending incremental file list
./
dir11/
dir11/file111.txt
sent 113 bytes received 26 bytes 278.00 bytes/sec
total size is 12 speedup is 0.09 (DRY RUN)
dos2unix 和 unix2doc 转换换行符
用于转换Windows和UNIX的换行符,通常在Windows系统上开发的脚本和配置,UNIX系统下都需要转换。
使用方式:
dos2unix test.sh将windows系统换行符\r\n转换为unix系统换行符\nunix2doc test.sh将unix系统换行符\n转换为windows系统换行符\r\n。
curl HTTP协议测试
由于当前的线上服务较多地使用了RESTful风格的API,所以集成测试就需要进行HTTP调用,查看返回的结果是否符合预期,curl命令当然是首选的测试方法。
-
-i打印响应头信息。 -
-v打印更多的调试信息。 -
-X设置请求方法,默认为GET。curl localhost:8000/v1/test # 使用GET方法请求localhost的8000端口的 /v1/test curl -X POST localhost:8000/v1/test # 使用POST方法 -
--header设置头部字段;使用--header 'key: value'格式,比如:--header 'Content-Type: application/json'设置数据为json格式。 -
-d--dataPOST数据内容;使用-d 'key=value'格式。 -
--data-rawPOST原始数据内容。例如:$ curl -X POST 'http://localhost:8000/v1/test' \ --header 'Content-Type: application/json' \ --data-raw '{"aa": "中文测试", "bb": "bb", "cc": ["cc1", "cc2"], "ee": "ee"}' -
--formPOST表单格式;使用--form 'key=value'格式;后面跟文件的话,使用--form 'file=@本地文件路径'。例如:$ curl -X POST 'http://127.0.0.1:8000/v1/test' \ --form 'aa=中文测试' \ --form 'bb=bb1' \ --form 'cc=cc1' \ --form 'cc=cc2' \ --form 'ee=ee' \ --form 'file=@/root/20200401175738.png' -
-sw '%{http_code}'打印http响应码,-s是--silent,-w是--write-out FORMAT,例如curl -sw '%{http_code}' http://www.baidu.com
sed
简单模式
sed -n '2,5 p' file.txt
一个简单的sed命令包含三个主要部分:参数,范围,操作。要操作的文件,可以直接挂在命令行的后面。
上面的命令,-n就是参数,2,5就是范围,p就是操作。
第一部分,参数
-n忽略执行过程的输出,只输出我们执行的结果。-i直接修改原文件,-iSUFFIX先备份原文件,再直接修改文件。sed -i 's/c++/python/' sed-test.txt对sed-test.txt文件,直接在原文件中将c++替换为python。sed 's/c++/python/' sed-test.txt将替换后的结果打印在终端上,而不是修改文件。sed -i.bak 's/c++/python/' sed-test.txt先将sed-test.txt文件备份为sed-test.txt.bak,再对sed-test.txt文件进行替换操作。
第二部分,范围
范围就是表示对选择指定的内容,然后进行后面的操作。没有选择范围就是对整个文件操作。
n,m表示选择从第n行到第m行的内容。比如2,5表示选择2,3,4,5行内容。n,+m表示选择从第n行到第n+m行的内容。比如2,+5表示选择2,3,4,5,6,7行内容。n,$表示选择从第n行到最后一行的内容。n~m表示从n行开始每次间隔m行。比如1~2表示奇数行;2~2表示偶数行;3~3表示从第3行开始,每隔3行的内容,即为3,6,9,12,...的行内容。
范围还可以使用正则匹配
/void/,+3选择出现void字样的行,以及后面的三行。2/^void/,/mem/选择以void开头的行,和出现mem字样行之间的数据。
举例子:范围和操作之间可以有空格,也可以没有空格
sed -n '5p' sed-test.txt # 打印第5行的内容
sed -n '2,5 p' sed-test.txt # 打印第2到5行的内容
sed -n '1~2 p' sed-test.txt # 打印奇数行内容
sed -n '2~2 p' sed-test.txt # 打印偶数行内容
sed -n '2,+3p' sed-test.txt # 打印第2行以及后面3行的内容,也就是2,3,4,5行
sed -n '2,$ p' sed-test.txt # 打印第2行到最后的内容
sed -n '/void/,+3p' sed-test.cpp # 打印包含void字样的行以及后面的3行
sed -n '/^void/,/return/p' # 打印以void开头的行和包含return的行之间的内容
第三部分,操作
-
p打印内容。比如下面2个命令效果是一样的:cat file sed -n 'p' file -
d对匹配的内容进行删除。这个时候就要去掉-n参数了,想想为什么。sed '2,5 d' sed-test.txt # 显示除了第2行到第5行之外的其他行内容。假如文件有7行,会显示1,6,7行内容。 sed -n '2,5 d' sed-test.txt # 如果加上-n,则什么都不会显示。 -
w对匹配内容写入到其他地方。比如将第2到5行的之间的内容存储到(不是追加到)/tmp/xxx.txt文件中,可以这么写:sed -n '2,5w/tmp/xxx.txt' sed-test.txt sed -n '2,5 w /tmp/xxx.txt' sed-test.txt # 也可以加空格
其他的还有a i c等操作,但基本上不会使用,这里不介绍了。
替换模式
以上是sed命令的常用匹配模式,但它还有一个强大的替换模式,意思就是查找替换其中的某些值,并输出结果。使用替换模式很少使用-n参数。
sed '/^sys/S/a/b/g' file
拆分一下上面的命令:
/^sys/第一部分,范围。S第二部分,命令。a第三部分,匹配。b第四部分,替换字符。g第五部分,flag。
替换模式的参数有点多,但第一部分和第五部分都是可以省略的。替换后会将整个文本输出出来。
前半部分用来匹配一些范围,而后半部分执行替换的动作。
第一部分,范围
这个范围和上面的范围语法是一样的。下面直接看一些例子。
-
选择包含void的行以及后面的3行,并将里面的void全部替换为int。
sed '/void/,+3 s/void/int/g' sed-test2.cpp -
选择以void开头的行和包含CLIENT_TYPE_FLAG_BOTH的行之前的内容,并将里面的Imuser全部替换为User。
sed '/^void/,/CLIENT_TYPE_FLAG_BOTH/s/Imuser/User/g' sed-test2.cpp
第二部分,命令
s也就是substitute的意思。
第三部分,匹配
查找部分会找到要被替换的字符串。这部分可以接受纯粹的字符串,也可以接受正则表达式。看下面的例子。
a查找范围行中的字符串a。[a,b,c]从范围行里查找字符串a或者b或者c。
比如:
sed 's/a/b/g' file # 将整个文件中的字符串a替换为字符串b
sed 's/[a,b,c]/<&>/g' file # 将整个文件中的字符串a替换为字符串<a>,b替换为<b>,c替换为<c>,下面会解释
第四部分,替换
是时候把找出的字符串给替换掉了。本部分的内容将替换查找匹配部分找到的内容。
可惜的是,这部分不能使用正则。常用的就是精确替换。比如把a替换成b。
但也有高级功能。和java或者python的正则api类似,sed的替换同样有Matched Pattern的含义,同样可以得到Group,不深究。常用的替位符,就是&。
&号,再重复一遍。当它用在替换字符串中的时候,代表的是原始的查找匹配数据。
[&] 表明将查找到的数据使用[]包围起来。“&” 表明将查找的数据使用””包围起来。
下面这条命令,将会把文件中的每一行,使用双引号包围起来。
sed 's/.*/"&"/' file
第五部分,flag参数
这些参数可以单个使用,也可以使用多个,仅介绍最常用的。
g默认只匹配行中第一次出现的内容,加上g,就可以全文替换了。常用。p当使用了-n参数,p将仅输出匹配行内容。w和上面的w模式类似,但是它仅仅输出有变化的行。i这个参数比较重要,表示忽略大小写。e表示将输出的每一行,执行一个命令。不建议使用,可以使用xargs配合完成这种功能。
举例:
sed -n 's/a/b/gipw output.txt' file # 全局将a(忽略大小写)替换为b,并输出到output.txt文件
提示:^M就是\r
awk
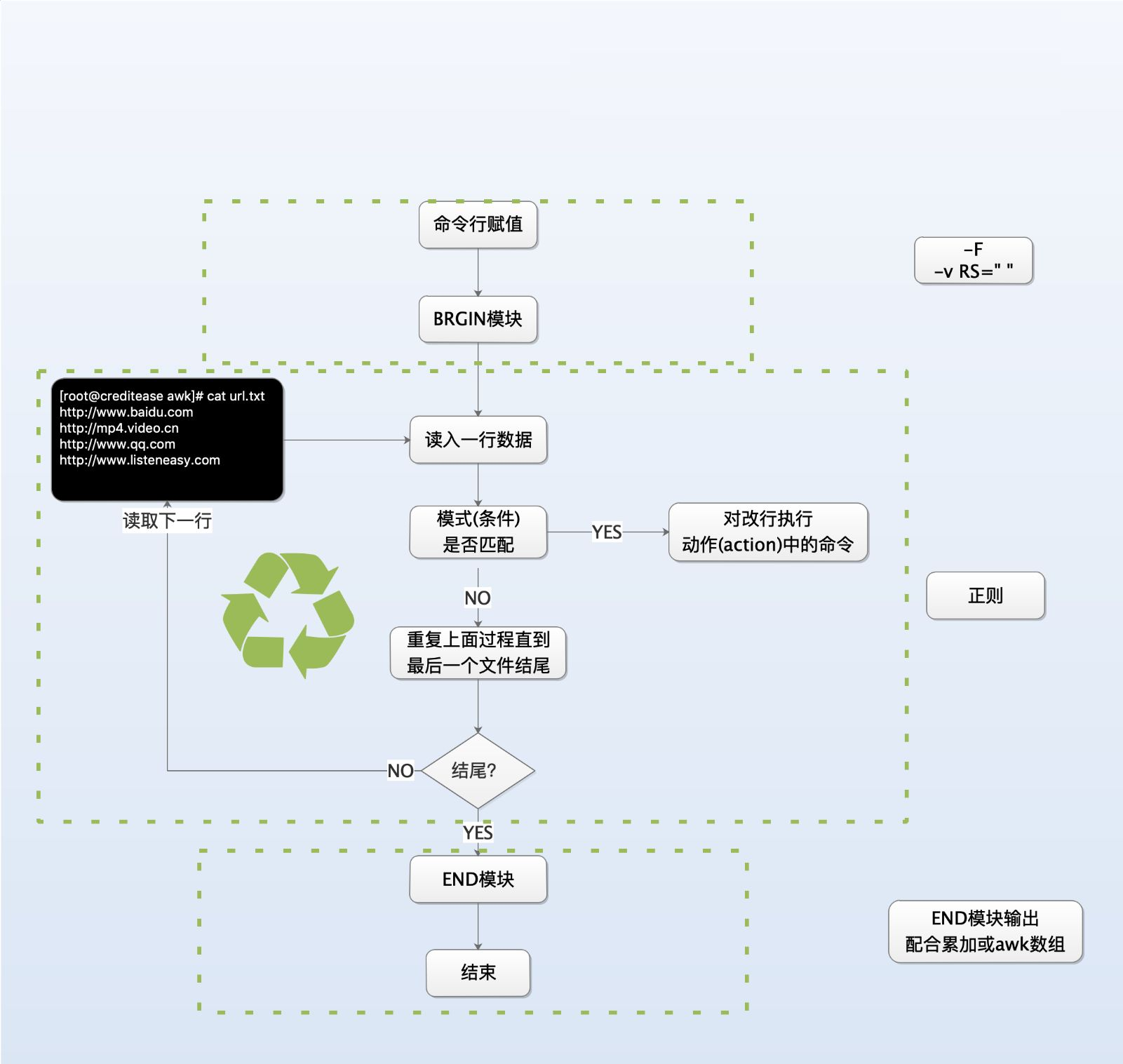
awk同sed命令类型,只不过sed擅长取行,awk命令擅长取列。
原理:一般是遍历一个文件中的每一行,然后分别对文件的每一行进行处理。
用法:
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
打印某几列
$ echo 'I love you' | awk '{print $3 $2 $1}'
youloveI
我们将字符串 I love you 通过管道传递给awk命令,相当于awk处理一个文件,该文件的内容就是I love you,默认通过空格作为分隔符(不管列之间有多少个空格都将当作一个空格处理)I love you就分割成三列了。
假如分割符号为.,可以这样用
$ echo '192.168.1.1' | awk -F "." '{print $2}'
168
条件过滤
我们知道awk的用法是这样的,那么pattern部分怎么用呢?
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
$ cat score.txt
tom 60 60 60
kitty 90 95 87
jack 72 84 99
$ awk '$2>=90{print $0}' score.txt
kitty 90 95 87
$2>=90 表示如果当前行的第2列的值大于90则处理当前行,否则不处理。说白了pattern部分是用来从文件中筛选出需要处理的行进行处理的,这部分是空的代表全部处理。
pattern部分可以是任何条件表达式的判断结果,例如>,<,==,>=,<=,!=同时还可以使用+,-,*,/运算与条件表达式相结合的复合表达式,逻辑 &&,||,!同样也可以使用进来。另外pattern部分还可以使用 /正则/ 选择需要处理的行。
判断语句
判断语句是写在pattern{ 命令 }命令中的,他具备条件过滤一样的作用,同时他也可以让输出更丰富。
$ awk '{if($2>=90 )print $0}' score.txt
kitty 90 95 87
$ awk '{if($2>=90 )print $1,"优秀"; else print $1,"良好"}' score.txt
tom 良好
kitty 优秀
jack 良好
$ awk '{if($2>=90 )print $0,"优秀"; else print $1,"良好"}' score.txt
tom 良好
kitty 90 95 87 优秀
jack 良好
BEGIN定义表头
awk [可选的命令行选项] 'BEGIN{命令 } pattern{ 命令 } END{ 命令 }' 文件名
使用方法如下:
$ awk 'BEGIN{print "姓名 语文 数学 英语"}{printf "%-8s%-5d%-5d%-5d\n",$1,$2,$3,$4}' score.txt
姓名 语文数学英语
tom 60 60 60
kitty 90 95 87
jack 72 84 99
这里要注意,我为了输出格式好看,做了左对齐的操作(%-8s左对齐,宽8位),printf用法和c++类似。
不仅可以用来定义表头,还可以做一些变量初始化的工作,例如
$ awk 'BEGIN{OFMT="%.2f";print 1.2567,12E-2}'
1.26 0.12
这里OFMT是个内置变量,初始化数字输出格式,保留小数点后两位。
END 添加结尾符
和BEGIN用法类似
$ echo ok | awk '{print $1}END{print "end"}'
ok
end
数据计算
$ awk 'BEGIN{print "姓名 语文 数学 英语 总成绩"; \
sum1=0;sum2=0;sum3=0;sumall=0} \
{printf "%5s%5d%5d%5d%5d\n",$1,$2,$3,$4,$2+$3+$4;\
sum1+=$2;sum2+=$3;sum3+=$4;sumall+=$2+$3+$4}\
END{printf "%5s%5d%5d%5d%5d\n","总成绩",sum1,sum2,sum3,sumall}'\
score.txt
姓名 语文 数学 英语 总成绩
tom 60 60 60 180
kitty 90 95 87 272
jack 72 84 99 255
总成绩 222 239 246 707
因为命令太长,末尾用\符号换行。
-
BEGIN体里输出表头,并给四个变量初始化0
-
pattern体里输出每一行,并累加运算
-
END体里输出总统计结果
当然了,一个正常人在用linux命令的时候是不会输入那么多格式化符号来对齐的,所以新命令又来了
column -t。# 使用column 对齐 $ awk 'BEGIN{print "姓名 语文 数学 英语"} {printf "%s %s %s %s\n", $1, $2, $3, $4}' score.txt | column -t 姓名 语文 数学 英语 tom 60 60 60 kitty 90 95 87 jack 72 84 99
范例:网络状态统计
运行netstat -ant输出如下:
$ netstat -ant
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:27017 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:2601 0.0.0.0:* LISTEN
tcp 0 0 172.17.0.1:3306 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:6380 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:21 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:2200 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN
tcp 0 0 172.16.115.174:2200 172.16.115.1:2514 ESTABLISHED
tcp 0 0 172.16.115.174:2200 172.16.115.221:50193 ESTABLISHED
tcp 0 0 172.16.115.174:2200 172.16.115.1:2499 ESTABLISHED
tcp 0 0 172.16.115.174:2200 172.16.115.1:2487 ESTABLISHED
tcp 0 36 172.16.115.174:2200 172.16.115.221:54700 ESTABLISHED
tcp 0 0 172.16.115.174:2200 172.16.115.1:2489 ESTABLISHED
tcp6 0 0 :::2200 :::* LISTEN
tcp6 0 0 ::1:5432 :::* LISTEN
其中,第6列,标明了网络连接所处于的网络状态。我们先给出awk命令,看一下统计结果。
$ netstat -ant |
awk ' \
BEGIN{print "State","Count" } \
/^tcp/ \
{ rt[$6]++ } \
END{ for(i in rt){print i,rt[i]} }'
输出结果为:
State Count
LISTEN 10
ESTABLISHED 6
假如我们只关心3306端口的链接:
netstat -ant |
awk ' \
BEGIN{print "State","Count" } \
/^tcp/ \
{ if($4=="0.0.0.0:3306" ) rt[$6]++ } \
END{ for(i in rt){print i,rt[i]} }'
查看*:2200的链接
netstat -ant | awk ' \
BEGIN{print "State","Count" } \
/^tcp.*:2200 / \
{ rt[$6]++ } \
END{ for(i in rt){print i,rt[i]} }'
下面这张图会配合以上命令详细说明,希望你能了解awk的精髓。

- BEGIN 开头部分,可选的。用来设置一些参数,输出一些表头,定义一些变量等。上面的命令仅打印了一行信息而已。
- END 结尾部分,可选的。用来计算一些汇总逻辑,或者输出这些内容。上面的命令,使用简单的for循环,输出了数组rt中的内容。
- Pattern 匹配部分,依然可选。用来匹配一些需要处理的行。上面的命令,只匹配tcp开头的行,其他的不进入处理。
- Action 模块。主要逻辑体,按行处理,统计打印,都可以。
注意:
- awk的主程序部分使用单引号‘包围,而不能是双引号。
- awk的列开始的index是0,而不是1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号