Prometheus 简介
什么是普罗米修斯?
Prometheus是一个开源系统监控和警报工具包,最初由 SoundCloud构建。自 2012 年启动以来,许多公司和组织都采用了 Prometheus,该项目拥有非常活跃的开发者和用户社区。它现在是一个独立的开源项目,独立于任何公司进行维护。为了强调这一点,并明确项目的治理结构,Prometheus 于 2016 年作为继Kubernetes之后的第二个托管项目加入了云原生计算基金会。
Prometheus 将其指标收集并存储为时间序列数据,即指标信息与记录时的时间戳以及称为标签的可选键值对一起存储。
有关 Prometheus 的更详尽的概述,请参阅从 媒体部分链接的资源。
特征
普罗米修斯的主要特点是:
- 具有由指标名称和键/值对标识的时间序列数据的多维数据模型
- PromQL,一种灵活的查询语言 来利用这个维度
- 不依赖分布式存储;单个服务器节点是自治的
- 时间序列收集通过 HTTP 上的拉模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持模式
什么是指标?
用外行的话来说,指标是数字测量。时间序列意味着随着时间的推移记录变化。用户想要测量的内容因应用程序而异。对于 Web 服务器,它可能是请求时间,对于数据库,它可能是活动连接数或活动查询数等。
指标在理解您的应用程序为何以某种方式工作方面起着重要作用。假设您正在运行一个 Web 应用程序并发现该应用程序运行缓慢。您将需要一些信息来了解您的应用程序发生了什么。例如,当请求数量很高时,应用程序可能会变慢。如果您有请求计数指标,您可以找出原因并增加服务器数量来处理负载。
组件
Prometheus 生态系统由多个组件组成,其中许多组件是可选的:
- 抓取和存储时间序列数据的主要Prometheus 服务器
- 用于检测应用程序代码的客户端库
- 支持短期工作的推送网关
- 用于 HAProxy、StatsD、Graphite 等服务的特殊用途出口商。
- 一个alertmanager来处理警报
- 各种支持工具
大多数 Prometheus 组件都是用Go编写的,这使得它们易于构建和部署为静态二进制文件。
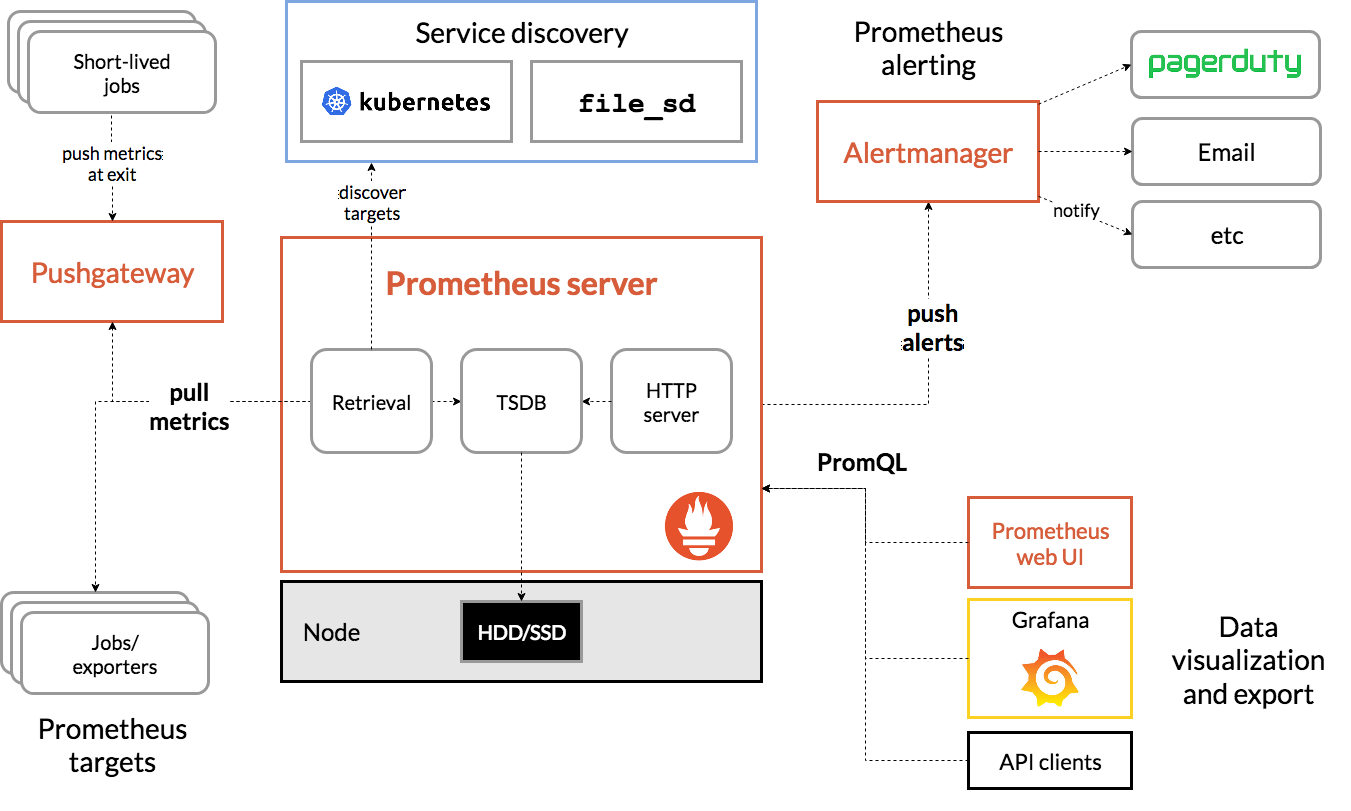
Prometheus 直接或通过一个用于短期作业的中间推送网关从检测作业中抓取指标。它在本地存储所有抓取的样本,并对这些数据运行规则,以聚合和记录现有数据的新时间序列或生成警报。Grafana或其他 API 消费者可用于可视化收集的数据。
1.1.1 Prometheus生态圈组件
- Prometheus Server:主服务器,负责收集和存储时间序列数据
- client libraies:应用程序代码插桩,将监控指标嵌入到被监控应用程序中
- Pushgateway:推送网关,为支持short-lived作业提供一个推送网关
- exporter:专门为一些应用开发的数据摄取组件—exporter,例如:HAProxy、StatsD、Graphite等等。
- Alertmanager:从Prometheus server端接收到alerts后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接
收方式有:电子邮件,企业微信,钉钉,webhook
1.1.2 架构理解
Prometheus既然设计为一个维度存储模型,可以把它理解为一个OLAP系统。
1、存储计算层
- Prometheus Server,里面包含了存储引擎和计算引擎。
- Retrieval组件为取数组件,它会主动从Pushgateway或者Exporter拉取指标数据。
- Service discovery,可以动态发现要监控的目标。
- TSDB,数据核心存储与查询。
- HTTP server,对外提供HTTP服务。
2、采集层
采集层分为两类,一类是生命周期较短的作业,还有一类是生命周期较长的作业。
- 短作业:直接通过API,在退出时间指标推送给Pushgateway。
- 长作业:Retrieval组件直接从Job或者Exporter拉取数据。
3、应用层
应用层主要分为两种,一种是AlertManager,另一种是数据可视化。
- AlertManager
对接Pagerduty,是一套付费的监控报警系统。可实现短信报警、5分钟无人ack打电话通知、仍然无人ack,通知值班人员Manager...
Emial,发送邮件
... ...
- 数据可视化
Prometheus build-in WebUI
Grafana
其他基于API开发的客户端
Prometheus工作原理
- Prometheus server定期从配置好的jobs或者exporters中拉metrics,或者接收来自Pushgateway发过来的metrics,或者从其他
的Prometheus server中拉netrics.
- Prometheus server在本地存储收集到的metrics,并运行已定义好的alert.rules,记录新的时间序列或者向Alertmanager推送警报。
- Alertmanager根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
什么时候适合?
Prometheus 可以很好地记录任何纯数字时间序列。它既适合以机器为中心的监控,也适合监控高度动态的面向服务的架构。在微服务的世界中,它对多维数据收集和查询的支持是一个特别的优势。
Prometheus 专为可靠性而设计,是您在中断期间访问的系统,可让您快速诊断问题。每个 Prometheus 服务器都是独立的,不依赖于网络存储或其他远程服务。当您的基础架构的其他部分出现故障时,您可以依赖它,并且您无需设置大量基础架构即可使用它。
什么时候不合适?
普罗米修斯重视可靠性。您始终可以查看有关系统的可用统计信息,即使在出现故障的情况下也是如此。如果您需要 100% 的准确性,例如按请求计费,Prometheus 不是一个好的选择,因为收集的数据可能不够详细和完整。在这种情况下,您最好使用其他系统来收集和分析计费数据,并使用 Prometheus 进行其余监控。
普罗米修斯配置
Prometheus 配置为YAML。Prometheus 下载在一个名为 的文件中附带了一个示例配置,prometheus.yml这是一个很好的起点。
我们删除了示例文件中的大部分注释以使其更加简洁(注释是前缀为 a 的行#)。
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
# - "first.rules"
# - "second.rules"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
示例配置文件中包含三个配置块:global、rule_files和scrape_configs。
该global块控制 Prometheus 服务器的全局配置。我们有两个选择。第一个,scrape_interval控制 Prometheus 抓取目标的频率。您可以为单个目标覆盖它。在这种情况下,全局设置是每 15 秒抓取一次。该evaluation_interval选项控制 Prometheus 评估规则的频率。Prometheus 使用规则来创建新的时间序列并生成警报。
该rule_files块指定我们希望 Prometheus 服务器加载的任何规则的位置。现在我们还没有规则。
最后一个块,scrape_configs控制 Prometheus 监控的资源。由于 Prometheus 还将有关自身的数据公开为 HTTP 端点,因此它可以抓取和监控自身的健康状况。在默认配置中,有一个名为 的作业prometheus,用于抓取 Prometheus 服务器公开的时间序列数据。该作业包含一个单一的、静态配置的目标,即localhoston port 9090。Prometheus 期望指标在 . 路径上的目标上可用/metrics。所以这个默认作业是通过 URL 抓取的:http://localhost:9090/metrics。
返回的时间序列数据将详细说明 Prometheus 服务器的状态和性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号