一、web简单框架的构建
一、HTTP协议
http协议简介
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP) 是一种用于分布式、协作式和超媒体信息系统的应用层协议。
1999年6月公布的 RFC 2616,定义了HTTP协议中现今广泛使用的一个版本——HTTP 1.1。
http协议概述
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
HTTP工作原理
HTTP 请求/响应的步骤:
- 客户端连接到web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.luffycity.com。 - 发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。 - 服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。 - 释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求; - 客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
HTTP请求方法
请求方法
get post
GET提交的数据会放在URL之后,也就是请求行里面,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456.(请求头里面那个content-type做的这种参数形式,后面讲) POST方法是把提交的数据放在HTTP包的请求数据部分中.
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
GET与POST请求在服务端获取请求数据方式不同,就是我们自己在服务端取请求数据的时候的方式不同了
常用的get请求方式:浏览器输入网址 ,a标签 ,form标签 method='get'
post请求方法,一般都用来提交数据.比如用户名密码登录
其他方法:HEAD PUT DELETE TRACE OPTIONS CONNECT PATCH请求方法
get post
GET提交的数据会放在URL之后,也就是请求行里面,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456.(请求头里面那个content-type做的这种参数形式,后面讲) POST方法是把提交的数据放在HTTP包的请求数据部分中.
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
GET与POST请求在服务端获取请求数据方式不同,就是我们自己在服务端取请求数据的时候的方式不同了
常用的get请求方式:浏览器输入网址 ,a标签 ,form标签 method='get'
post请求方法,一般都用来提交数据.比如用户名密码登录
其他方法:HEAD PUT DELETE TRACE OPTIONS CONNECT PATCH
GET:就是获取数据的操作
DELETE:就是请求服务器删除数据的操作
POST:就是添加数据的操作
PUT:就是更新数据的操作
....
-
get请求和post的区别
<form action="http://127.0.0.1:8001"> 用户名:<input type="text" name="username"> 密 码: <input type="text" name="password"> <input type="submit"> </form> GET /?username=alex&password=123 HTTP/1.1 提交的数据会放在URL之后,也就是请求行里面 Host: 127.0.0.1:8001 Connection: keep-alive ..... <form action="http://127.0.0.1:8001" method="post"> 用户名:<input type="text" name="username"> 密 码: <input type="text" name="password"> <input type="submit"> </form> POST / HTTP/1.1 Host: 127.0.0.1:8001 Connection: keep-alive .... username=alex&password=dasd POST方法是把提交的数据放在HTTP包的请求数据部分中get:
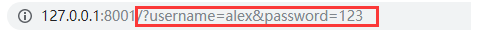
post:

HTTP状态码
状态代码的第一个数字代表当前响应的类型:
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误
URL
超文本传输协议(HTTP)的统一资源定位符将从因特网获取信息的五个基本元素包括在一个简单的地址中:
- 传送协议。
- 层级URL标记符号(为[//],固定不变)
- 访问资源需要的凭证信息(可省略)
- 服务器。(通常为域名,有时为IP地址)
- 端口号。(以数字方式表示,若为HTTP的默认值“:80”可省略)
- 路径。(以“/”字符区别路径中的每一个目录名称)
- 查询。(GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题)
- 片段。以“#”字符为起点
比如:https://www.cnblogs.com/clschao/articles/9230431.html?name=chao&age=18
HTTP请求协议格式

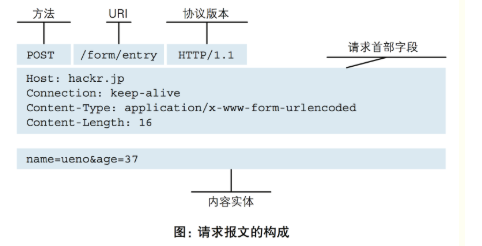
请求格式
GET / HTTP/1.1 --- GET /clschao/articles/9230431.html?name=chao&age=18 HTTP/1.1
User-Agent:....
xx:xx
请求数据 get请求方法没有请求数据 post请求数据方法的请求数据放在这里
HTTP响应响应协议格式
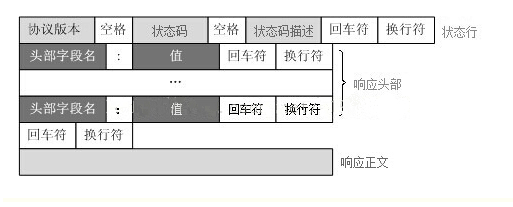

响应格式
HTTP/1.1 200 ok
kl:v1
k2:v2
响应数据
http协议特点
1.基于 请求-响应 的模式
2.无状态保存(缺点:每次访问都是新的,无法维持长时间的联系,无法和网页持续的交流)
3.无连接(一次请求一次响应,就断开连接了,保证效率)
请求:request
响应:response
网页查看请求和响应的信息
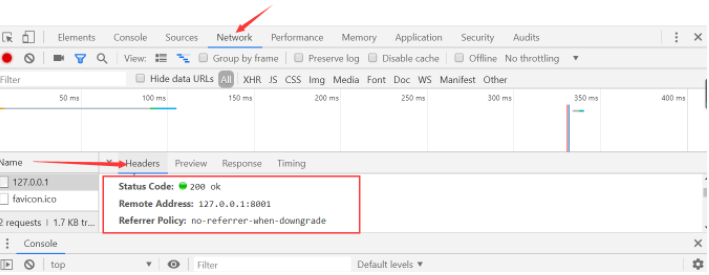
反爬
在请求头部信息中,有一项User-Agent选项,可以运用与反扒
-
先写一个爬取网页的代码,爬京东的主页
import requestsres = requests.get('https://www.jd.com/2019') with open('jd.html','w',encoding='utf-8') as f: f.write(res.text) 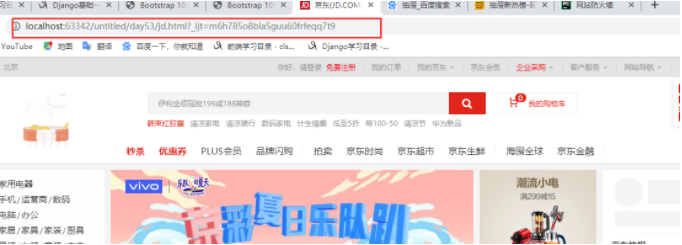访问的地址是我们本地的地址,
拿到的的京东的html是可以打开访问的,跟京东的主页一样;就没有做UA反爬 -
爬抽屉的主页
import requestsres = requests.get('https://dig.chouti.com/') with open('ct.html','w',encoding='utf-8') as f: f.write(res.text)
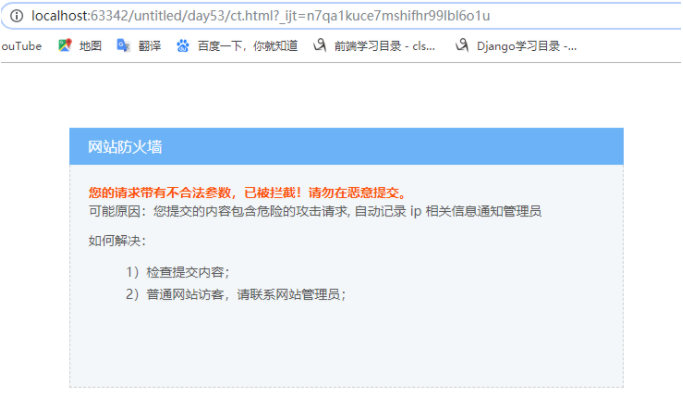
此时拿到的html页面打开是显示网站防火墙的,说明做了UA反爬措施
-
伪装来解决反爬的问题
在抽屉的network中,找到User-Agent,

以键值对的形式放在requests中,让其以网页的身份去访问
import requestsres = requests.get('https://dig.chouti.com/',headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'}) with open('ct.html','w',encoding='utf-8') as f: f.write(res.text)
二、web框架的本质及定义
所有的Web应用本质上就是一个socket服务端,而用户的浏览器就是一个socket客户端,基于请求做出响应,客户都先请求,服务端做出对应的响应,按照http协议的请求协议发送请求,服务端按照http协议的响应协议来响应请求,这样的网络通信,我们就可以自己实现Web框架了。
因为socket就是做网络通信用的,下面我们就基于socket来自己实现一个web框架,写一个web服务端,让浏览器来请求,并通过自己的服务端把页面返回给浏览器,浏览器渲染出我们想要的效果。
-
初级版本
import socket
server = socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()while 1:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
print(from_client_msg)conn.send(b'HTTP/1.1 200 ok\r\n\r\n') with open('01momo.html','rb') as f: data = f.read() conn.send(data) conn.close()01momo.html文件中写着:
<h1>你好世界</h1> Python中的socket就是服务端,当网页客户端来访问时,就返回给一个html,样式是一个标题写着:你好世界
实现:因为http协议的格式,先写状态码,发送给网页,然后读出html文件,发送给客户端,就实现了一个基本的web框架
-
初级版本
import socket
server = socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()while 1:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
print(from_client_msg)conn.send(b'HTTP/1.1 200 ok\r\nk1:v1\r\n\r\n') with open('03简单版.html','rb') as f: data = f.read() conn.send(data) conn.close()03简单版.html:
<head><br> <style><br> h1{<br> background-color: yellow;<br> }<br> </style></p> </head> <body> <h1>你想知道的我们都有</h1> 一年的四季: <ul> <li>春</li> <li>夏</li> <li>秋</li> <li>冬</li> </ul> <script> alert('客观来玩呀') </script> </body> 这个版本在html文件中,写了css样式,用同样的方式,也完成了简单的web框架,等到了网页效果
-
升级版本
这个版本考虑到css样式不是写在html文件里面,而是单独写在一个css文件里,然后用link引入的
import socket
server = socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()while 1:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
print(from_client_msg)conn.send(b'HTTP/1.1 200 ok\r\nk1:v1\r\n\r\n') with open('04升级版.html','rb') as f: data = f.read() conn.send(data) conn.close()04升级版.html:
<head><br> <link href="text.css" rel="stylesheet"></p> </head> <body> <h1>你想知道的我们都有</h1> 一年的四季: <ul> <li>春</li> <li>夏</li> <li>秋</li> <li>冬</li> </ul> <script src="test.js"></script> </body> text.css:
h1{
background-color: yellow;
}test.js:
alert('客观来玩呀~~');
可以正常的拿到页面,但是css、js效果没有了
打开网页的network,分析原因:
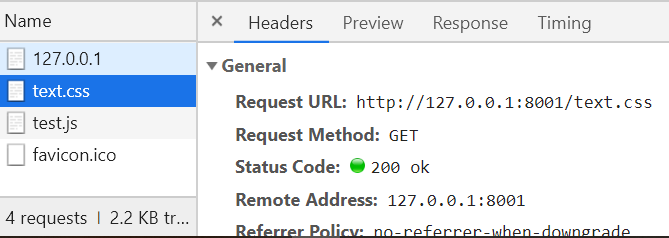
发现除了最上边的主请求,还有text.css、test.js、favicon.ico请求,向服务端要这几个文件;
因为写了相对路径,就是还向自己写的服务器里请求,而写了绝对路径的,比如图片的网址,就会向别的服务器要,就不用自己再传一个文件过去了
- 升级版本(解决css、js、图片等问题)
首先要得到请求的文件:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
request_str = from_client_msg
path = request_str.split('\r\n')
print(path)
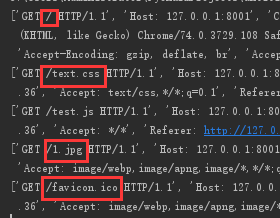
以 split('\r\n') 分割,就把每个请求行、请求头都分出来了,取第一项,再以空格切分,取第二项,就是我们要得到的请求地址
path = request_str.split('\r\n')[0].split(' ')[1]

通过判断路径的名称,回复对应请求的文件:
import socket
server = socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()
while 1:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
request_str = from_client_msg
path = request_str.split('\r\n')[0].split(' ')[1]
print(path)
conn.send(b'HTTP/1.1 200 ok\r\nk1:v1\r\n\r\n')
if path == '/':
with open('04升级版.html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
elif path == '/text.css':
with open('text.css','rb') as f:
data = f.read()
conn.send(data)
conn.close()
elif path == '/test.js':
with open('test.js','rb') as f:
data = f.read()
conn.send(data)
conn.close()
elif path == '/1.jpg':
with open('1.jpg','rb') as f:
data = f.read()
conn.send(data)
conn.close()
elif path == '/22.ico':
with open('22.ico','rb') as f:
data = f.read()
conn.send(data)
conn.close()
这样我们就等到了有js、css效果的网页,但是写的太low
-
函数进阶版本
import socket
server = socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()def html(conn):
with open('04升级版.html', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()def css(conn):
with open('text.css', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()def js(conn):
with open('test.js', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()def jpg(conn):
with open('1.jpg', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()def ico(conn):
with open('22.ico', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()while 1:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
# print(from_client_msg)
request_str = from_client_msg
path = request_str.split('\r\n')[0].split(' ')[1]
print(path)
conn.send(b'HTTP/1.1 200 ok\r\nk1:v1\r\n\r\n')
if path == '/':
html(conn)
elif path == '/text.css':
css(conn)
elif path == '/test.js':
js(conn)
elif path == '/1.jpg':
jpg(conn)
elif path == '/22.ico':
ico(conn)
把每个请求放在函数里,通过if判断去掉对应的函数
-
高级版
import socket
server = socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()def html(conn):
with open('04升级版.html', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()def css(conn):
with open('text.css', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()def js(conn):
with open('test.js', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()def jpg(conn):
with open('1.jpg', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()def ico(conn):
with open('22.ico', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()urlpatterns = [
('/',html),
('/text.css',css),
('/test.js',js),
('/1.jpg',jpg),
('/22.ico',ico),
]while 1:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
# print(from_client_msg)
request_str = from_client_msg
path = request_str.split('\r\n')[0].split(' ')[1]
print(path)
conn.send(b'HTTP/1.1 200 ok\r\nk1:v1\r\n\r\n')
for i in urlpatterns:
if path == i[0]:
i1
去掉了if判断,因为请求文件和发送文件都是异步的,不需要等待结果,所以还可以做异步并发处理
import socket
from threading import Thread
server = socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()
def html(conn):
with open('04升级版.html', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def css(conn):
with open('text.css', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def js(conn):
with open('test.js', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def jpg(conn):
with open('1.jpg', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def ico(conn):
with open('22.ico', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
urlpatterns = [
('/',html),
('/text.css',css),
('/test.js',js),
('/1.jpg',jpg),
('/22.ico',ico),
]
while 1:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
# print(from_client_msg)
request_str = from_client_msg
path = request_str.split('\r\n')[0].split(' ')[1]
print(path)
conn.send(b'HTTP/1.1 200 ok\r\nk1:v1\r\n\r\n')
for i in urlpatterns:
if path == i[0]:
# i[1](conn)
t = Thread(target=i[1],args=(conn,))
t.start()
- 高级版
动态页面,数据会发生变化的页面
import socket
from threading import Thread
import time
server = socket.socket()
server.bind(('127.0.0.1',8001))
server.listen()
def html(conn):
time_tag = str(time.time())
with open('07高级版动态页面.html', 'r',encoding='utf-8') as f:
data = f.read()
data = data.replace('$xxoo',time_tag)
data = data.encode('utf-8')
conn.send(data)
conn.close()
def css(conn):
with open('text.css', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def js(conn):
with open('test.js', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def jpg(conn):
with open('1.jpg', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
def ico(conn):
with open('22.ico', 'rb') as f:
data = f.read()
conn.send(data)
conn.close()
urlpatterns = [
('/',html),
('/text.css',css),
('/test.js',js),
('/1.jpg',jpg),
('/22.ico',ico),
]
while 1:
conn,addr = server.accept()
from_client_msg = conn.recv(1024).decode('utf-8')
# print(from_client_msg)
request_str = from_client_msg
path = request_str.split('\r\n')[0].split(' ')[1]
print(path)
conn.send(b'HTTP/1.1 200 ok\r\nk1:v1\r\n\r\n')
for i in urlpatterns:
if path == i[0]:
# i[1](conn)
t = Thread(target=i[1],args=(conn,))
t.start()
07高级版动态页面.html:
<body>
<h1>你想知道的我们都有</h1>
<h2>$xxoo</h2>
.....
</body>
通过字符串的替换,每次请求都会读出来html文件,把事先写好的一个字符串:$xxoo替换成 time_tag,也就是获取的时间戳,这样每次刷新页面,时间戳都会改变,这样页面的数据就动态起来了
-
wsgiref升级版
....
path = request_str.split('\r\n')[0].split(' ')[1]
....
conn.send(b'HTTP/1.1 200 ok\r\nk1:v1\r\n\r\n')
....
开发中的python web程序来说,一般会分为两部分:服务器程序和应用程序。
- 服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理
- 应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py 等。不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。
WSGI协议:一种规范,web服务器程序和web应用程序之间传输信息要统一消息格式。常用的WSGI服务器有uwsgi、Gunicorn。而Python标准库提供的独立WSGI服务器叫wsgiref,Django开发环境用的就是这个模块来做服务器
在socket接收请求信息、处理请求信息的时候,回复响应信息的格式的时候,有一个专门的模块可以完成这件事情,就是wsgiref,它可以把请求的信息全部处理成一个字典,想要什么就可以通过字典取值来得到
import time
from wsgiref.simple_server import make_server
# wsgiref本身就是个web框架,提供了一些固定的功能(请求和响应信息的封装,不需要我们自己写原生的socket了也不需要咱们自己来完成请求信息的提取了,提取起来很方便)
def html():
time_tag = str(time.time())
with open('07高级版动态页面.html', 'r',encoding='utf-8') as f:
data = f.read()
data = data.replace('$xxoo$',time_tag)
data = data.encode('utf-8')
return data
def css():
with open('text.css', 'rb') as f:
data = f.read()
return data
def js():
with open('test.js', 'rb') as f:
data = f.read()
return data
def jpg():
with open('1.jpg', 'rb') as f:
data = f.read()
return data
def ico():
with open('22.ico', 'rb') as f:
data = f.read()
return data
urlpatterns = [
('/', html),
('/text.css', css),
('/test.js', js),
('/1.jpg', jpg),
('/22.ico', ico),
]
#函数名字随便起
def application(environ, start_response):
'''
:param environ: 是全部加工好的请求信息,加工成了一个字典,通过字典取值的方式就能拿到很多你想要拿到的信息
:param start_response: 帮你封装响应信息的(响应行和响应头),注意下面的参数
'''
start_response('200 OK', [('k1','v1'),('k2','v2')]) # 新建添加回复的头部
path = environ['PATH_INFO']
for i in urlpatterns:
if path == i[0]:
ret = i[1]()
break
else:
ret = b'404 not found!'
# 如果请求的路径没有一个能对应上,走else,返回404 not found
return [ret] # 得到结果,模块内部把结果发送给网页
httpd = make_server('127.0.0.1', 8080, application)
print('Serving HTTP on port 8080...')
# 开始监听HTTP请求:
httpd.serve_forever()
- 连接数据库版
先启动mysql数据库,创建一个库(database),起名叫day53的库
建立一个model.py文件,专门用来创建表(table)的
import pymysql
conn = pymysql.connect(
host = '127.0.0.1',
port = 3306, # 默认的端口,公司用的可能不是这个,要设置
user = 'root',
password = '123',
database = 'day53',
charset = 'utf8'
)
cursor = conn.cursor(pymysql.cursors.DictCursor) # 获取游标
sql = 'create table userinfo(id int primary key auto_increment,name char(10),age int not null );'
cursor.execute(sql) # 执行
conn.commit() # 提交
cursor.close()
conn.close()
建立一个insertdata.py文件,模拟插入数据(正常应该直接放在业务逻辑里)
import pymysql
conn = pymysql.connect(
host = '127.0.0.1',
port = 3306, # 默认的端口,公司用的可能不是这个,要设置
user = 'root',
password = '123',
database = 'day53',
charset = 'utf8'
)
cursor = conn.cursor(pymysql.cursors.DictCursor) # 获取游标
sql = 'insert into userinfo(name,age) values ("yangzm",18);'
cursor.execute(sql) # 执行
conn.commit() # 提交
cursor.close()
conn.close()
建立一个showdata.py文件,专门用来查数据的,封装成一个函数,返回查出来的数据
import pymysql
def showdata():
conn = pymysql.connect(
host = '127.0.0.1',
port = 3306, # 默认的端口,公司用的可能不是这个,要设置
user = 'root',
password = '123',
database = 'day53',
charset = 'utf8'
)
cursor = conn.cursor(pymysql.cursors.DictCursor) # 获取游标
sql = 'select * from userinfo;'
cursor.execute(sql) # 执行
data = cursor.fetchone()
conn.commit() # 提交
cursor.close()
conn.close()
return data
此时查出来的是一个字典类型的数据

模拟这样一个场景,就是用户来访问我的网站,注册时提交了名字和年龄,保存在数据库里(这个保存的逻辑应该是在业务逻辑里写好的,本次只是模拟一下),现在想把这个数据库里面的数据读出来,放在html页面里去,然后在前端的页面展示
import time
from wsgiref.simple_server import make_server
from showdata import showdata
# wsgiref本身就是个web框架,提供了一些固定的功能(请求和响应信息的封装,不需要我们自己写原生的socket了也不需要咱们自己来完成请求信息的提取了,提取起来很方便)
def html():
userinfo_data = showdata() # 模块导入使用
with open('07高级版动态页面.html', 'r',encoding='utf-8') as f:
data = f.read()
data = data.replace('$xxoo$',userinfo_data['name'])#从数据库读出来的数据,展示到页面
data = data.encode('utf-8')
return data
def css():
with open('text.css', 'rb') as f:
data = f.read()
return data
def js():
with open('test.js', 'rb') as f:
data = f.read()
return data
def jpg():
with open('1.jpg', 'rb') as f:
data = f.read()
return data
def ico():
with open('22.ico', 'rb') as f:
data = f.read()
return data
urlpatterns = [
('/', html),
('/text.css', css),
('/test.js', js),
('/1.jpg', jpg),
('/22.ico', ico),
]
#函数名字随便起
def application(environ, start_response):
'''
:param environ: 是全部加工好的请求信息,加工成了一个字典,通过字典取值的方式就能拿到很多你想要拿到的信息
:param start_response: 帮你封装响应信息的(响应行和响应头),注意下面的参数
'''
start_response('200 OK', [('k1','v1'),('k2','v2')]) # 新建添加回复的头部
path = environ['PATH_INFO']
for i in urlpatterns:
if path == i[0]:
ret = i[1]()
break
else:
ret = b'404 not found!'
# 如果请求的路径没有一个能对应上,走else,返回404 not found
return [ret]
httpd = make_server('127.0.0.1', 8080, application)
print('Serving HTTP on port 8080...')
# 开始监听HTTP请求:
httpd.serve_forever()
这样,就完成了前端页面显示了从数据库读出来的数据的功能
- JinJa2高级版动态web框架
JinJa2 —— 模板渲染
动态页面(也就是字符串的替换),有一个专门的工具: jinja2 模块
安装:
pip install jinja2
用法:
template = Template(data) # 生成模板文件
ret = template.render({"name": "于谦", "hobby_list": ["烫头", "泡吧"]}) # 把数据填充到模板里面
from wsgiref.simple_server import make_server
from showdata import showdata
from jinja2 import Template
def html():
userinfo_data = showdata()
with open('10jinja2高级版动态web框架.html', 'r',encoding='utf-8') as f:
data = f.read()
tem = Template(data)
data = tem.render({'userinfo':userinfo_data})
# {'userinfo':{'id':1,'name':'yangzm','age':18}}
data = data.encode('utf-8')
return data
def css():
with open('text.css', 'rb') as f:
data = f.read()
return data
def js():
with open('test.js', 'rb') as f:
data = f.read()
return data
def jpg():
with open('1.jpg', 'rb') as f:
data = f.read()
return data
def ico():
with open('22.ico', 'rb') as f:
data = f.read()
return data
urlpatterns = [
('/', html),
('/text.css', css),
('/test.js', js),
('/1.jpg', jpg),
('/22.ico', ico),
]
#函数名字随便起
def application(environ, start_response):
'''
:param environ: 是全部加工好的请求信息,加工成了一个字典,通过字典取值的方式就能拿到很多你想要拿到的信息
:param start_response: 帮你封装响应信息的(响应行和响应头),注意下面的参数
'''
start_response('200 OK', [('k1','v1'),('k2','v2')]) # 新建添加回复的头部
path = environ['PATH_INFO']
for i in urlpatterns:
if path == i[0]:
ret = i[1]()
break
else:
ret = b'404 not found!'
# 如果请求的路径没有一个能对应上,走else,返回404 not found
return [ret]
httpd = make_server('127.0.0.1', 8080, application)
print('Serving HTTP on port 8080...')
# 开始监听HTTP请求:
httpd.serve_forever()
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Bootstrap 101 Template</title>
<link href="text.css" rel="stylesheet">
<link rel="icon" href="22.ico">
</head>
<body>
<h1>你想知道的我们都有</h1>
<h2>{{ userinfo }}</h2>
<!--userinfo就相当于我们查出来的那个数据字典{'id':1,'name':'yangzm','age':18}-->
<ul>
{% for k,v in userinfo.items() %}
<li>{{ k }}--{{ v }}</li>
{% endfor %}
</ul>
一年的四季:
<ul>
<li>春</li>
<li>夏</li>
<li>秋</li>
<li>冬</li>
</ul>
<img src="1.jpg" alt="">
<script src="test.js"></script>
</body>
</html>

也能够完成动态页面的效果,在前端页面显示从数据库读出来的数据
11 .起飞版web框架


 浙公网安备 33010602011771号
浙公网安备 33010602011771号