
沙漏网络框架视频生成算法
基于沙漏网络框架的视频生成算法
技术概述
描述这个技术是做什么的/什么情况下会使用到这个技术,学习该技术的原因,技术的难点在哪里。控制在50-100字内。
在视频生成预测的方法中,传统的视频生成方法会出现复合误差的传递,生成严重拖影。使用基于沙漏网络框架的视频生成算法来进行人体姿态估计(技术难点),利用神经图灵机对人体姿态进行预测(技术难点),最后将姿态和背景结合生成视频,从而获得更精确的生成视频。应用于视频制作等领域中。
技术详述
描述你是如何实现和使用该技术的,要求配合代码和流程图详细描述。可以再细分多个点,分开描述各个部分。
实现一: 利用3D沙漏网络架构来进行人体姿态估计
1.1沙漏网络框架背景说明
准确的姿态估计是理解人类在图片或者视频中行为的关键。对于一张单独的 RGB 图像, 我们希望可以准确定位出一些身体重要的关键点。对于人体姿态的理解及姿体结构对于高层任务,例如人机交互等是很重要的。
在姿态估计领域同样有着多个严峻的挑战。一个好的估计系统必须对遮挡还有严重的变形有很好的鲁棒性,能检测出一些奇特的姿势,包括对光照和衣服等变化的影响具有不变性。
本文提出 “stacked hourglass” 的网络来进行姿态估计,它可以获取到所以尺度图像的信息,因为网络结构的下采样和上采样操作,从结构上看像一个沙漏(hourglass) 而得名,像其他卷积方法一样,我们也将输入图片下采样到一个很小的分辨率,再上采样,并将统一尺寸的特征结合起来。另一方面,hourglass 网络由于它更对称的拓扑结构又不同于之前的一些网络设计。
下面是单个的Hourglass Network工作原理。串联的Stacked Hourglass相比单个网络主要是复用全身关节信息来提高单个关节的识别精度。
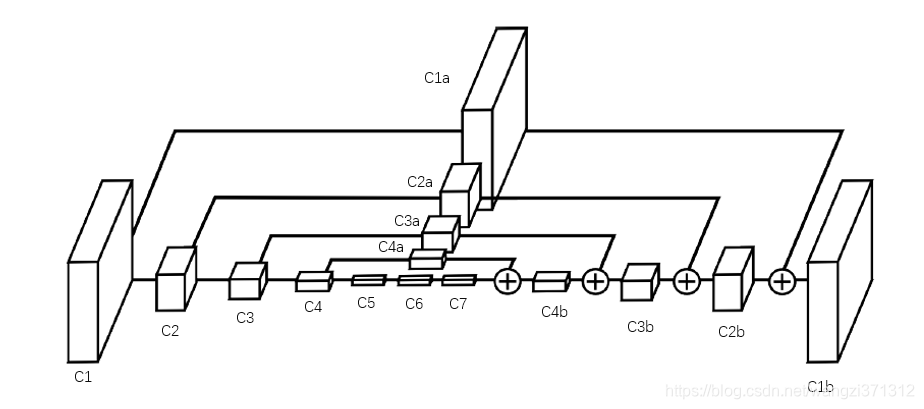
上图就是原论文里给出的HourGlass Model,跟2.2节中的网络结构(c1-c7)相比,有两个显著不同:(1)右边就像左边的镜像一样,倒序的复制了一份(c4b-c1b),整体上看起来就是一个沙漏(2)上面也复制了一份(c4a-c1a),而且每个方块还通过加号与右边对应位置的方块合并。
我们来分析下c4b这个网络层,它是由c7和c4a合并来的,这里有两块操作:
(1)c7层通过上采样将分辨率扩大一倍,上采样相当于pool层的反操作,为了将feature map的分辨率扩大,比如c7的kernel size为 4x4 ,那么上采样后得到的kernel size 为 8x8 。
(2)c4a层与c4层的大小保持一致,可以看作是c4层的“副本”,它的kernel size 是c7的两倍,刚好与被上采样后的c7大小一致,可以直接将数值相加,那么就得到了c4b
用python伪代码写下来上述操作如下:
c7_up = up_sample(c7) # 1x4x4x256 -> 1x8x8x256
c4_a = residual(c4) # 1x8x8x256 -> 1x8x8x256
# c4_a相当于c4的副本,但是经过了一个residual处理
c4b = c4_a + c7_up # 1x8x8x256
接下来就是c3b这个网络层,同样的,先对c4b进行上采样,然后与c3a合并,python伪代码如下:
c4_up = up_sample(c4_b) # 1x8x8x256 -> 1x16x16x256
c3_a = residual(c3) # 1x16x16x256 -> 1x32x32x256
c3b = c3_a + c4_up # 1x16x16x256
1.2:沙漏式设计
Hourglas结构的设计主要是源于想要抓住每个尺度信息的需求。例如一些局部信息对识别一些特征(例如脸,手等)很重要,而对于最后姿态的估计需要对整个身体有一个好的理解,这就要抓住很多局部的特征信息并结合起来。人的朝向,他们四肢的排列,相邻关节的关系都是在不同尺度图像中最好辨认的。 而 hourglass 则是一个简单的,最小化的设计,有这个能力捕捉全部的特征信息并做出最后的像素级别的预测。所有关节的预测是一起的,放在一个大的高维矩阵里,上图是为了演示才分开画的。
[ px1_of_c1b ]->[socre_of_neck,score_of_wrist,socre_of_knee,... ]
[ px2_of_c1b ]->[score_of_neck,score_of_wrist,score_of_knee,... ]
# px1_of_c1b,px2_of_c1b 是特征层c1b上的两个像素
# score_of_neck 是预测该点为颈部关键点的得分
1.3:层实现
上面提出的 “hourglass” 只是一个形状像沙漏的结构,内部的实现细节还是很灵活的,文中也对一些结构进行了探索,例如从 GoogLeNet,ResNet 中学习的用连续的 3x3 代替 5x5,残差结构, Inception 结构等 ,最终定下的设计是使用:残差结构,最大的卷积核不超过 3x3, 瓶颈结构。
1.4 :堆叠沙漏与中间监督
堆叠沙漏与中间监督上面提到为什么做多个 “hourglass” 结构的级联,并且每一个级联预测的 heatmaps (上图中蓝色区域)都会与真值对比产生一个 loss,最后将这些 loss 都加在一起,文中通过实验证明了这样做比只考虑最后一个 loss 的结果要好很多,这种考虑网络中间部分输出的训练就是中间监督
给定单帧,我们希望获得人体重要关节点的像素级定位。而传统的沙漏网络是基于单张图片进行人体姿态估计,没有利用时间上前后帧的信息。用上时间上前后帧的信息可以更精确的对人体姿态进行估计,因此,我们的沙漏网络在传统的沙漏网络上增加了时间依赖性。一个好的姿态估计系统要有很好的鲁棒性,主要体现在已下几个方面:
1.能够对严重的遮挡或者变形的图片进行很好的人体姿态估计。
2.对图片中不常见的人体姿态能够做出很好的人体姿态估计。
3.对图片中的光线和衣着打扮等对人物的外貌改变,不能影响网络对人体姿态的估计。
为了增强图片效果,我们将图片进行了+/-30度的不同程度地旋转操作,同时也对图片尺度进行0.75-1.25倍的变换.
实现二:利用神经图灵机进行人体姿态预测
通过引入一个使用注意力程序进行交互的外部存储器(external memory)来增强神经网络的能力。神经图灵机可以与图灵机或者冯·诺依曼体系相类比,但每个组成部分都是可微的,可以使用梯度下降进行高效训练。
相比LSTM,神经图灵机拥有外部存储,可以更好的存储长时记忆,增强预测能力。
2.1:神经图灵机(NTM)介绍
神经图灵机通过将神经网络与外部记忆资源耦合而对该神经网络的能力进行了延展——它们可以通过注意(attention)过程与外部记忆资源交互。
这种组合的系统类似于图灵机或冯·诺依曼结构,但它是端到端可微分的,使得其可以有效地使用梯度下降进行训练。
初步的结果表明神经图灵机可以根据输入和输出样本推理得到基本的算法,比如复制、排序和联想回忆(associative recall)。
RNN 相比于其它机器学习方法的突出之处在于其在长时间范围内学习和执行数据的复杂转换的能力。此外,我们都知道 RNN 是图灵完备的,因此其有能力模拟任意程序,只要连接方式合适即可。
标准 RNN 的能力被扩展以简化算法任务的解决方案。这种丰富性主要是通过一个巨大的可寻址的记忆实现的,所以通过类比于图灵的通过有线存储磁带实现的有限状态机(finite-state machine)的丰富性,其被命名为神经图灵机(NTM)。
和图灵机不同,神经图灵机是一种可微分的计算机,可以通过梯度下降训练,从而为学习程序提供了一种实用的机制。
关键在于,该架构的每个组件都是可微分的,使其可以直接使用梯度下降进行训练。这可以通过定义「模糊(blurry)」的读写操作来实现,其可以或多或少地与记忆中的所有元素进行交互(而非像普通的图灵机或数字计算机那样处理单个元素)。
2.2神经图灵机的优势所在:
神经图灵机拥有外部存储,可以更好的存储长时记忆,增强预测能力。
技术使用中遇到的问题和解决过程
要求问题的描述和解决有一定的内容,不能草草概括。要让遇到相关问题的人看了你的博客之后能够解决该问题。
技术路线:
编程语言使用python,机器学习框架使用tensorflow
问题1:
现有视频生成预测模型由于是实现像素级的预测,会出现复合误差传递问题,使得模型生成视频失真严重,不能很好地对视频进行预测。
解决方法:我们希望能通过分级处理,来避免复合误差传递。利用3D沙漏网络来生成人体姿态,结合背景来生成视频。
问题2:
利用LSTM来生成人体姿态,其所能记忆时长有限。
解决方法:引入神经图灵机,增加外部记忆,用来更好的预测人体姿态估计。
预期成果:
生成的视频能够直观看出人物运动趋势。
总结
在视频生成预测的方法中,传统的视频生成方法会出现复合误差的传递,生成严重拖影。使用基于沙漏网络框架的视频生成算法来进行人体姿态估计,利用神经图灵机对人体姿态进行预测,最后将姿态和背景结合生成视频,从而获得更精确的生成视频。可将此模型应用于视频修复,视频平滑,电影制作等领域中。神经图灵机拥有外部存储,可以更好的存储长时记忆,增强预测能力。生成的视频能够直观看出人物运动趋势。
列出参考文献、参考博客(标题、作者、链接)。
Newell, Alejandro, Kaiyu Yang, and Jia Deng. “Stacked hourglass networks for human pose estimation.” arXiv preprint arXiv:1603.06937 (2016).
C. L. Philip Chen, C. Y. Zhang*, L. Chen and M. Gan, “Fuzzy Restricted Boltzmann Machine for the Enhancement of Deep Learning,” IEEE Transactions on Fuzzy Systems, vol.23, no.6, pp.2163-2173, Dec. 2015.
C. Y. Zhang, C. L. Philip Chen, M. Gan and L. Chen, “Predictive Deep Boltzmann Machine for Multi-Period Wind Speed Forecasting,” IEEE Transactions on Sustainable Energy, vol.6, no.4, pp.1416-1425, Oct. 2015.

