结对作业二
结对第二次作业——顶会热词统计的实现
作业基本信息
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次作业 |
| 团队成员 | 031801124&221801126 |
| 这个作业的目标 | 顶会热词统计的实现 |
| 其他参考文献 | CSDN , GitHub |
基础功能实现
总览
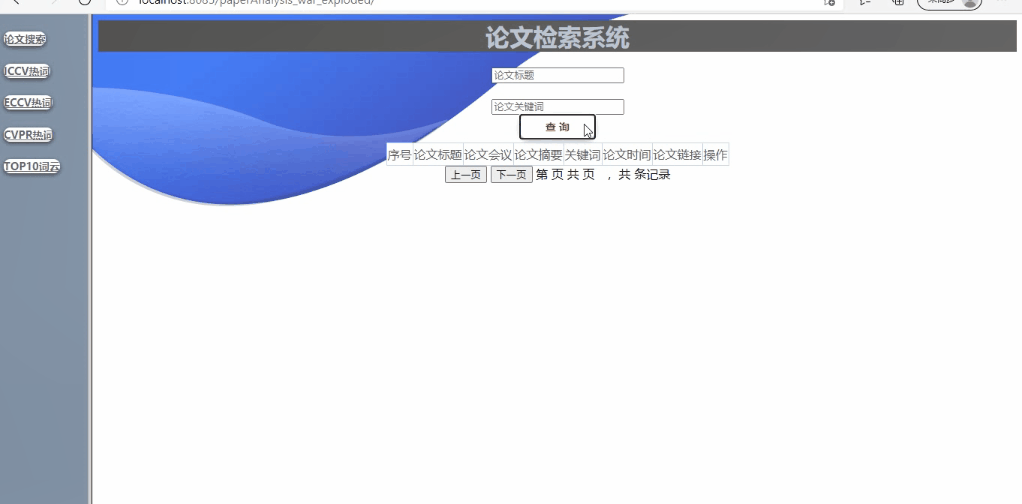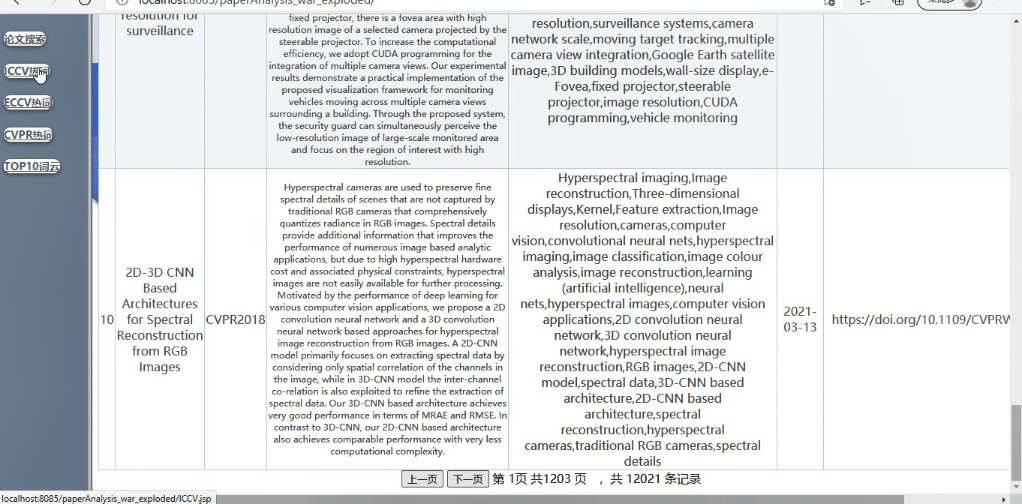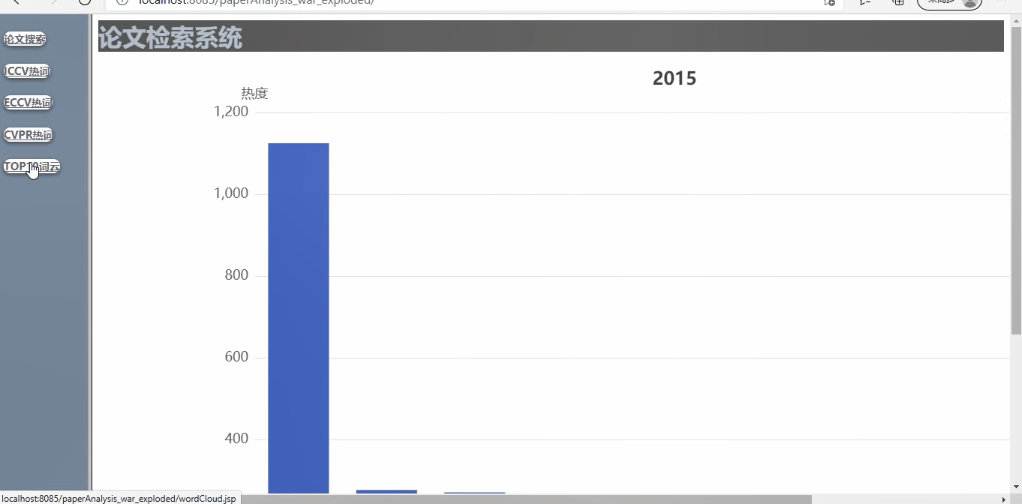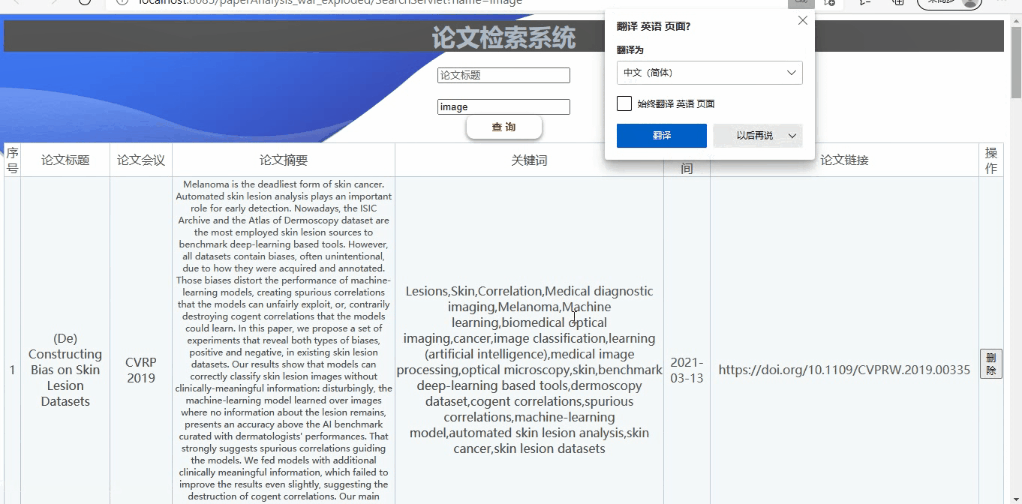
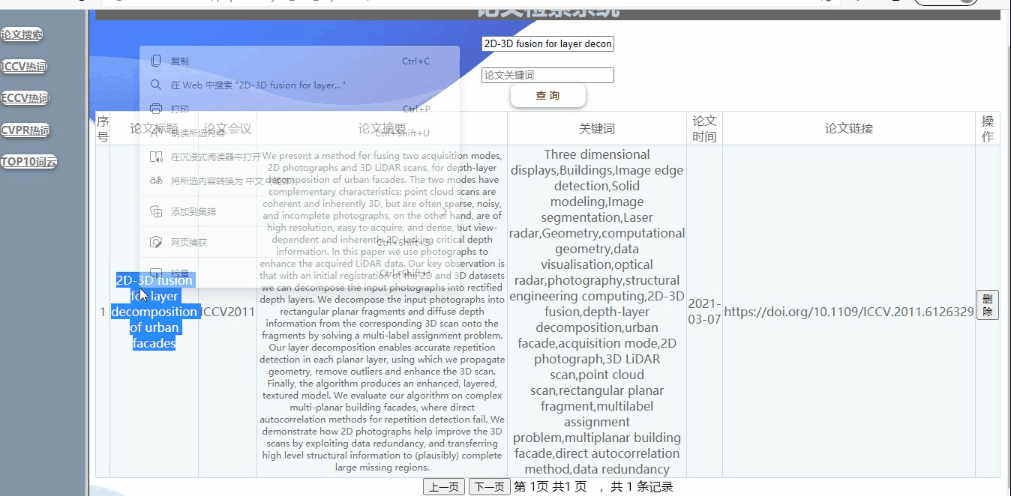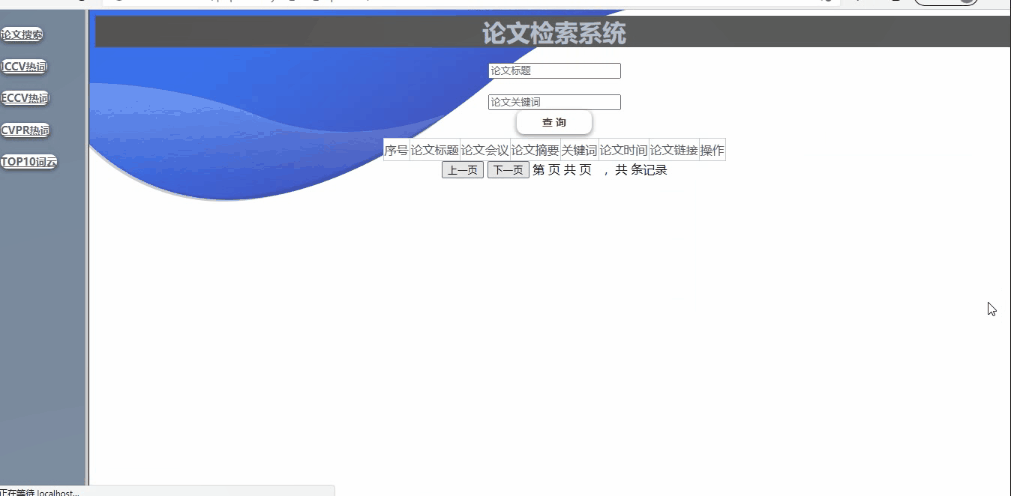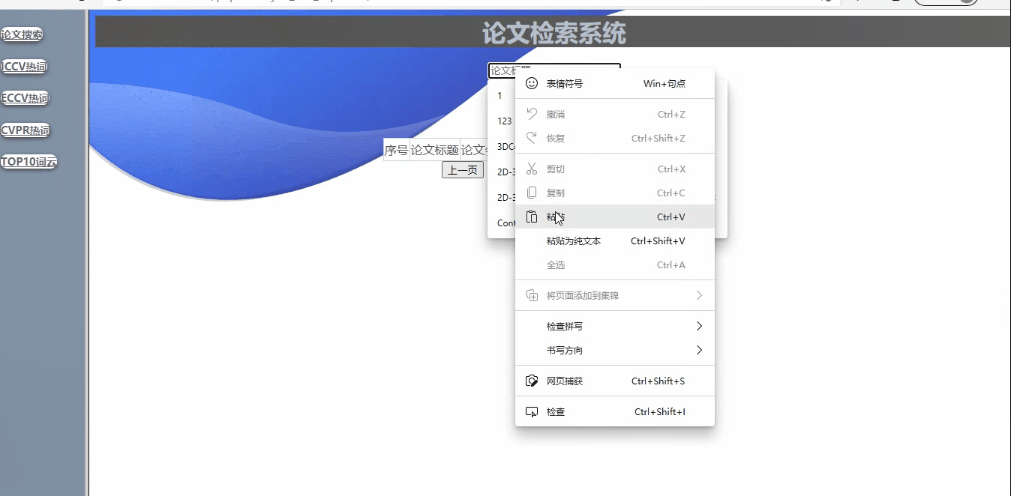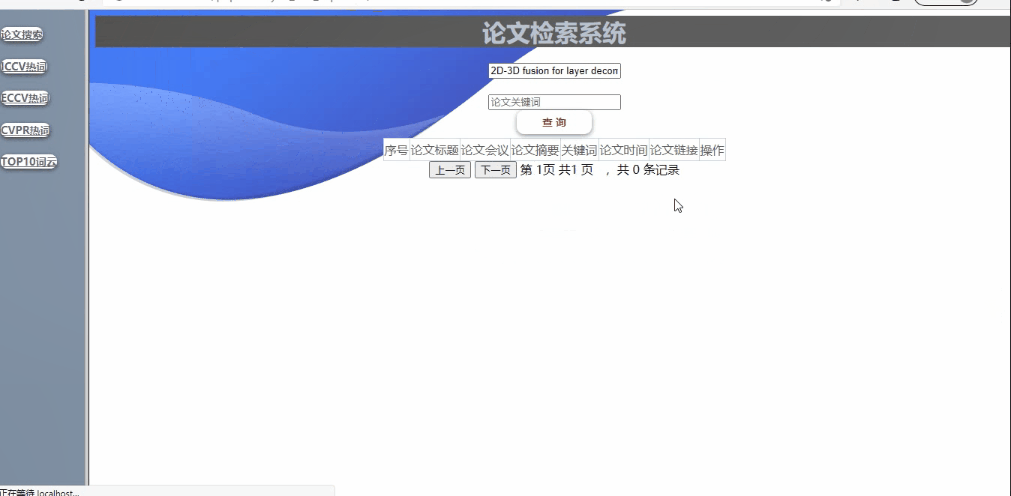
功能1:对已爬取的论文列表进行操作
-
可对论文列表进行删除
实现如下:
-
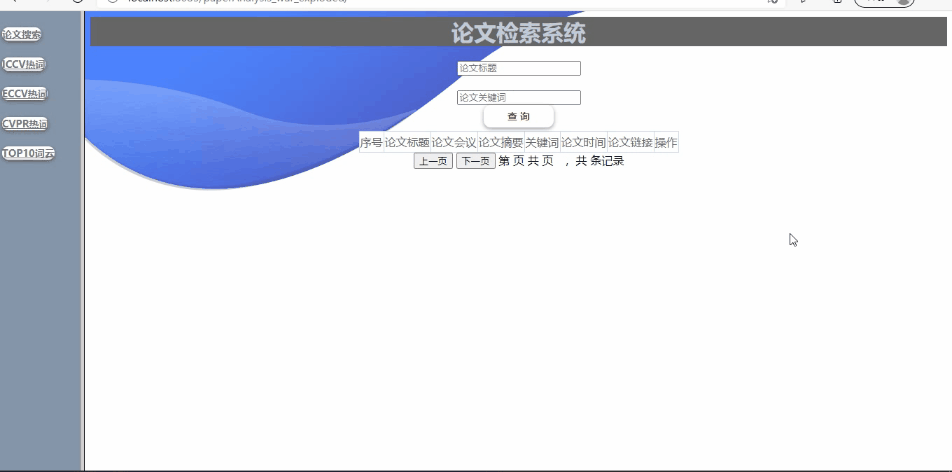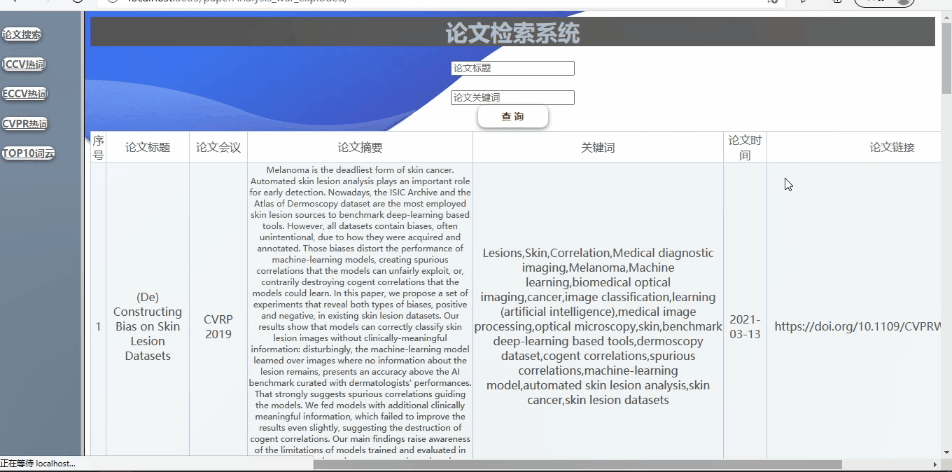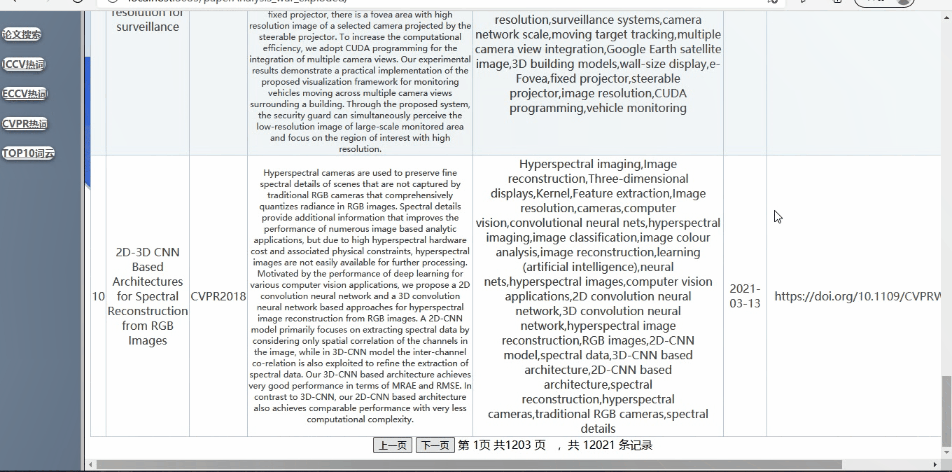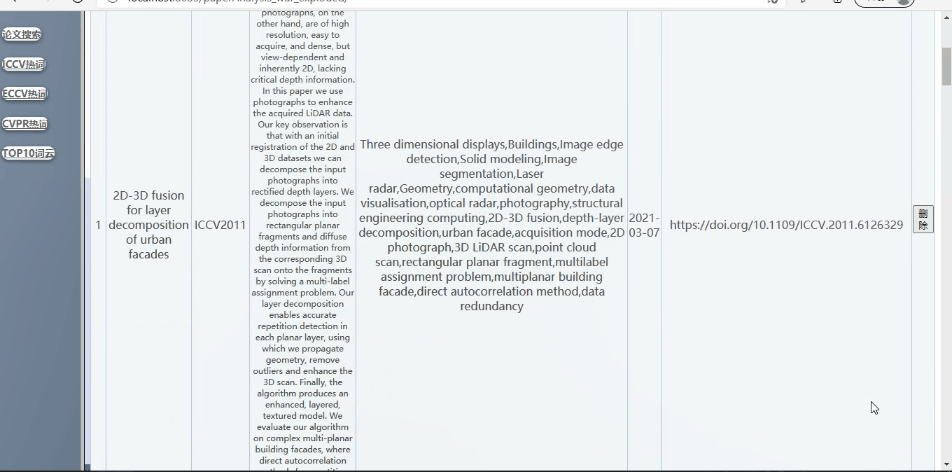
可对论文列表进行查询详细信息(支持模糊查询,查询结果的展示、排序等功能可自行设计)
实现如下:(支持模糊查询,查询结果的展示、排序等功能)
全局搜索
全字匹配搜索

模糊搜索

功能2:分析已爬取到的论文信息,提取top10个热门领域或热门研究方向
- 形成如关键词图谱之类直观的查看方式,点击某个关键词可展现相关的论文;
使用echart词云实现

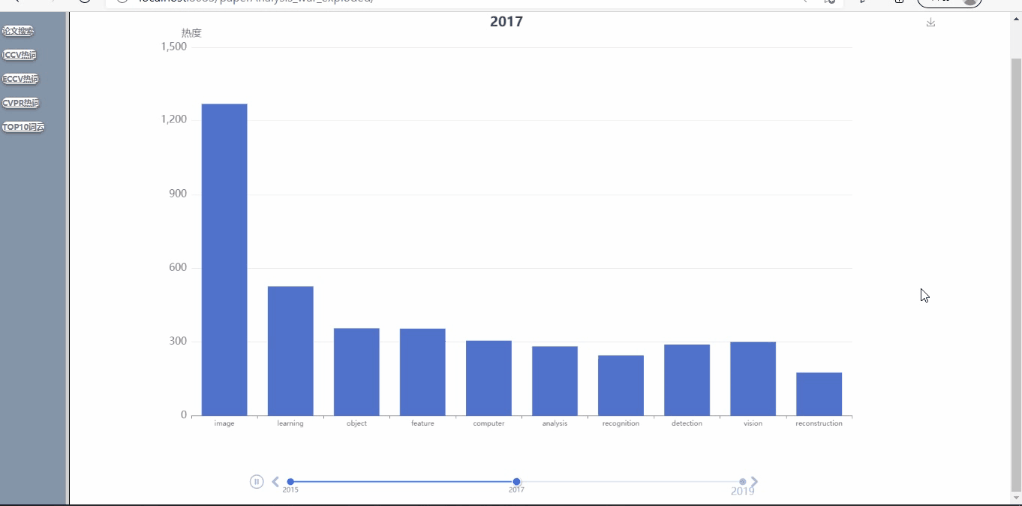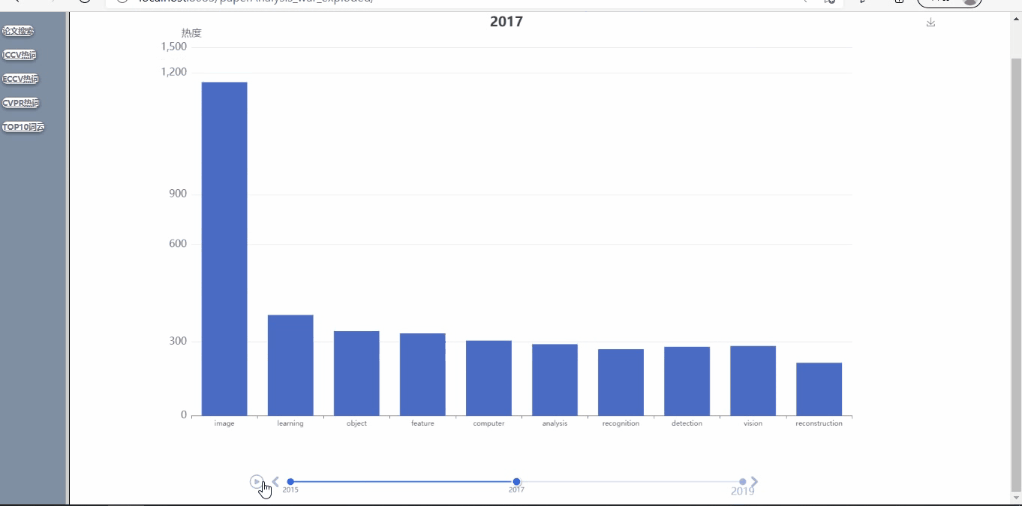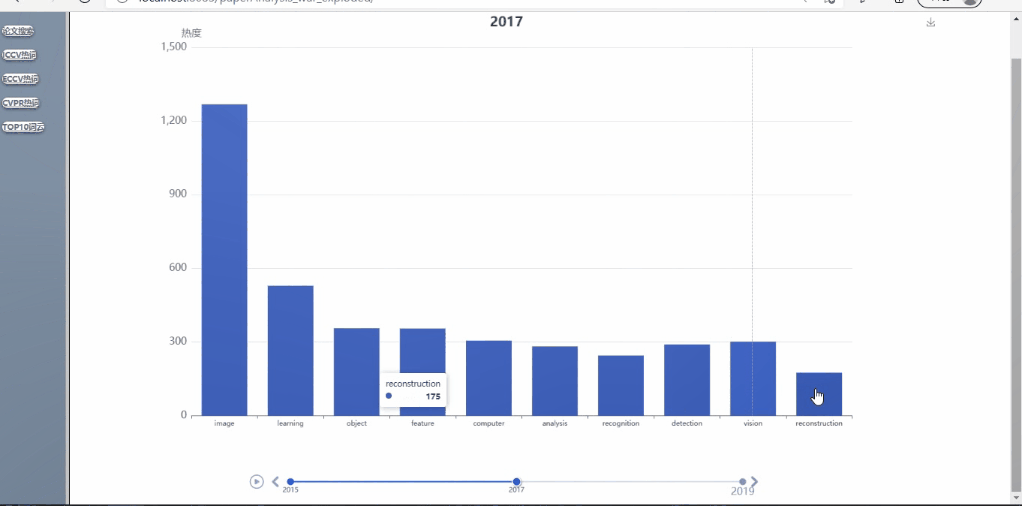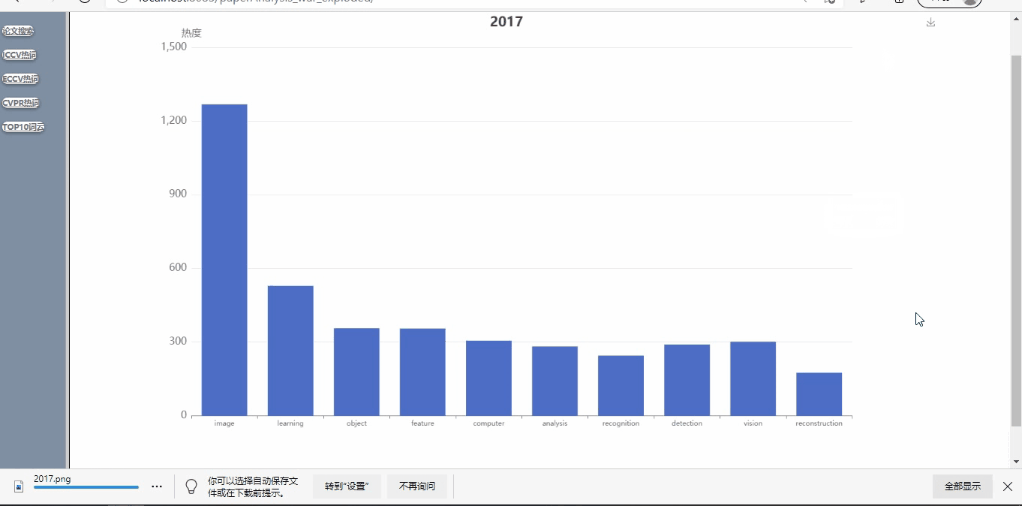
- 可对多年间、不同顶会的热词呈现热度走势对比,以动图的形式呈现(这里将范畴限定在计算机视觉的三大顶会CVPR、ICCV、ECCV内)
不同会议的多年论文趋势展示
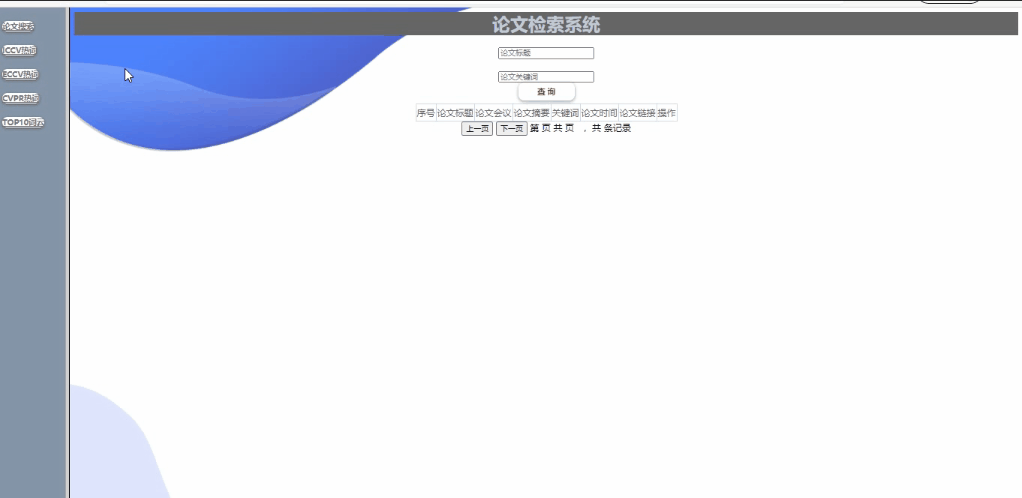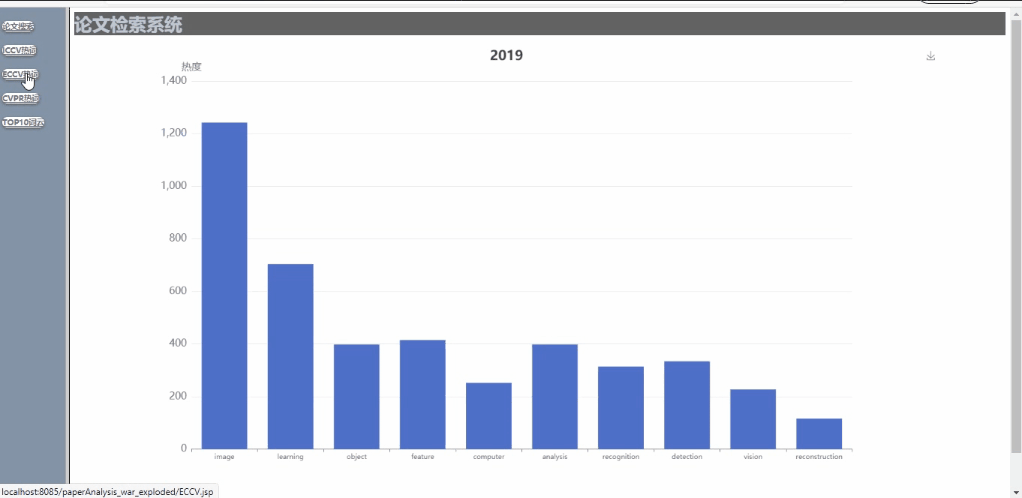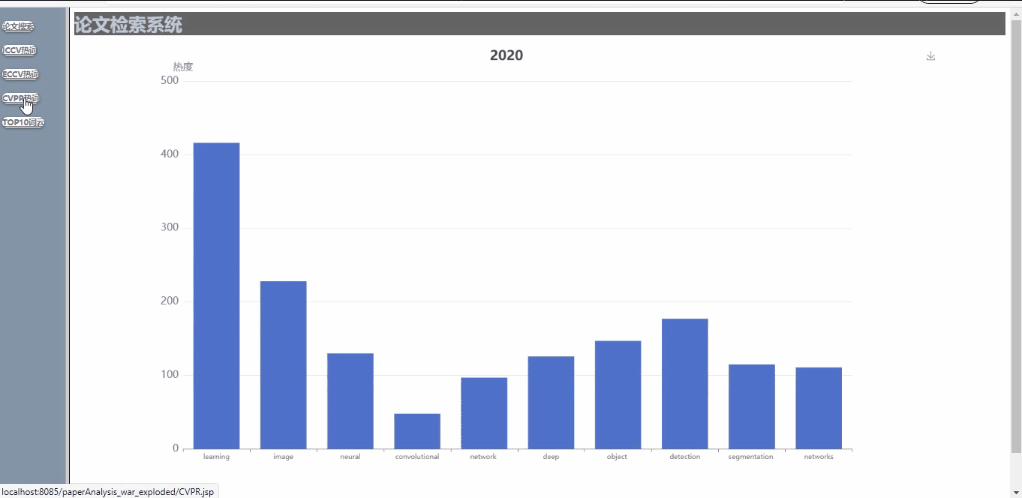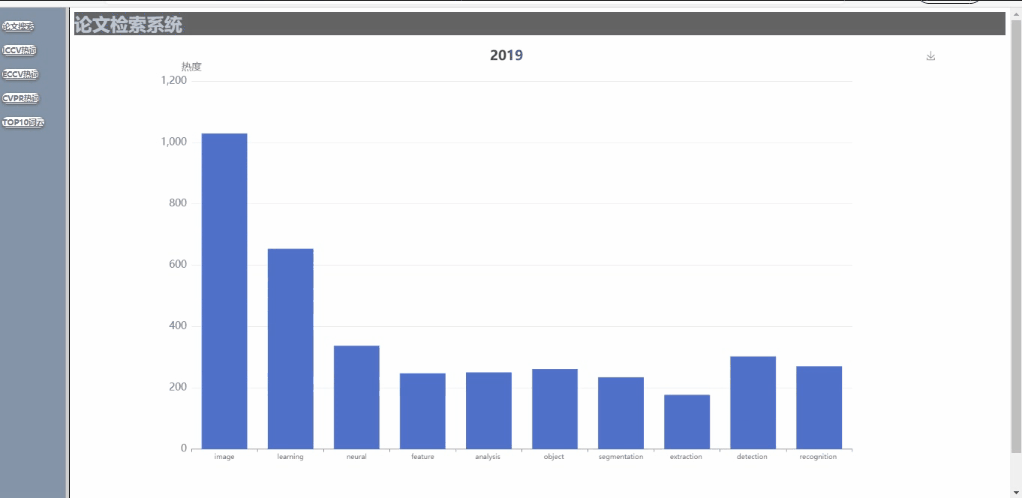
我们还实现了对显示的图表的保存
附加功能
功能3:获取待爬取论文列表及论文信息爬取
通过论文列表,爬取论文的摘要、关键词、原文链接;
- 数据来源网站:CVPR、ICCV、ECCV
- 至少爬取三年、三大顶会各300篇论文
- 可编写爬虫代码实现,也可使用爬虫工具(如八爪鱼)爬取
实现:使用八爪鱼爬虫工具实现,速度很慢,爬了很久...
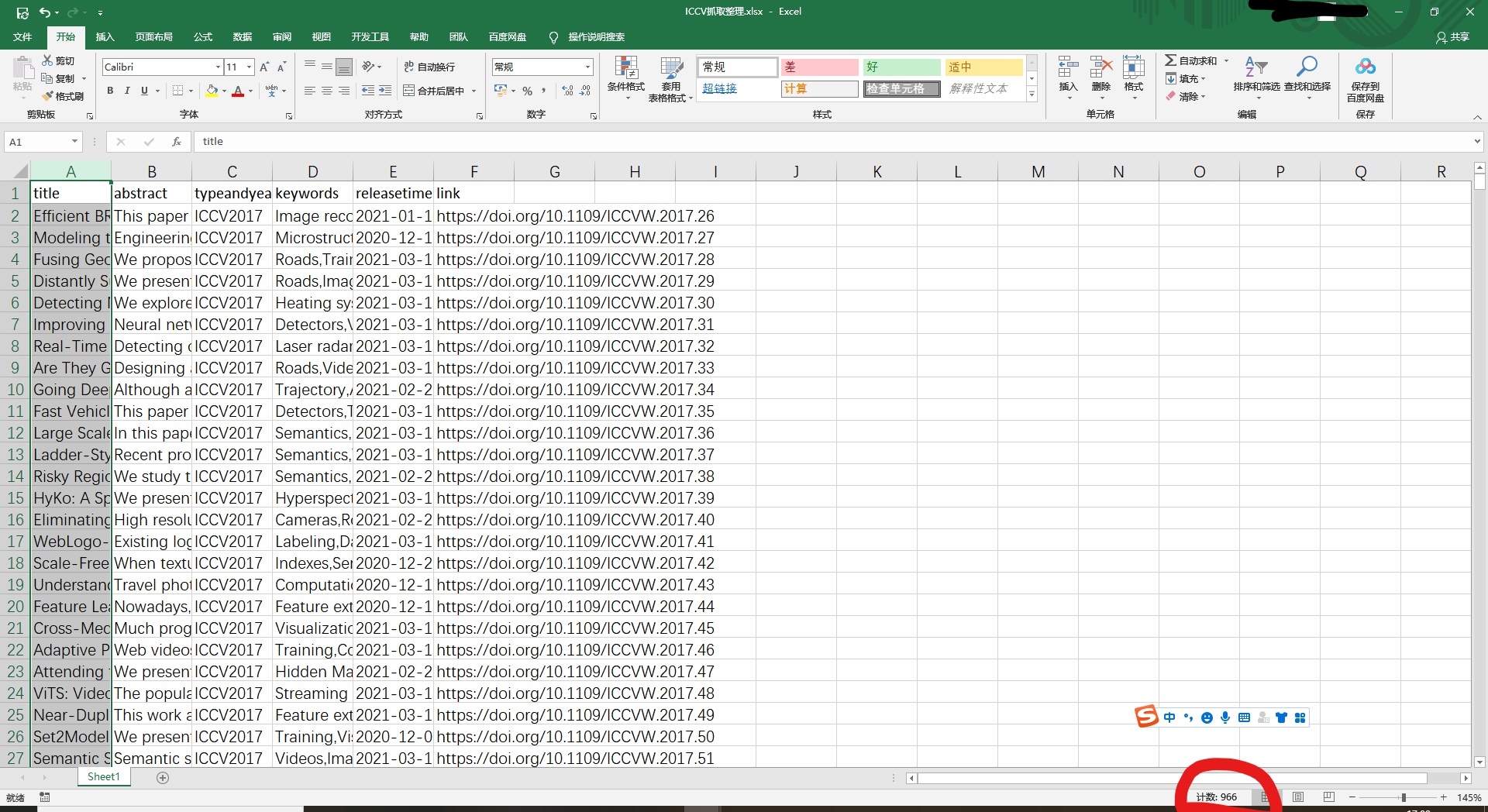
ICCV爬取后的数据库,大于300条记录,满足要求
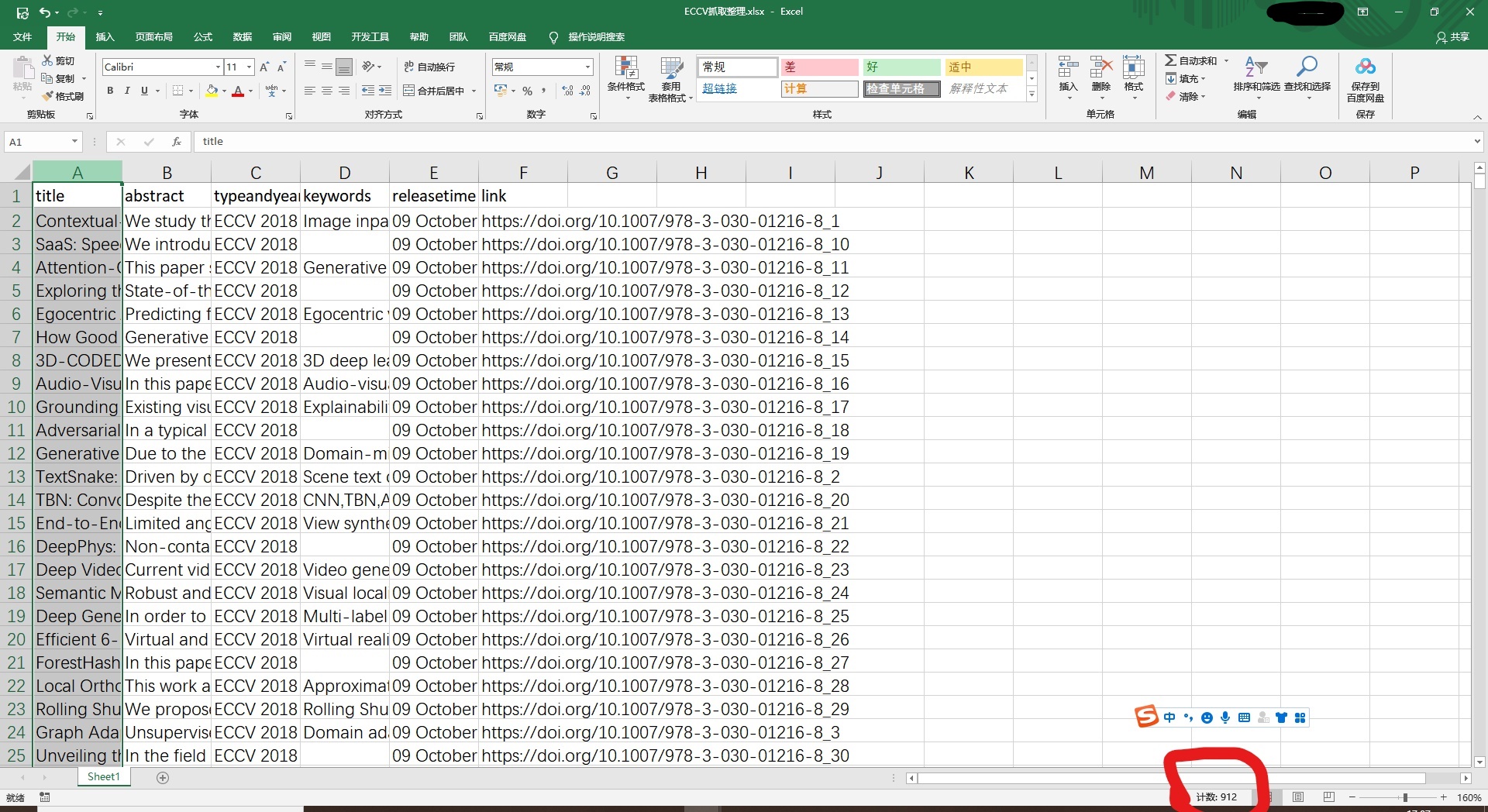
ECCV爬取后的数据库,大于300条记录,满足要求
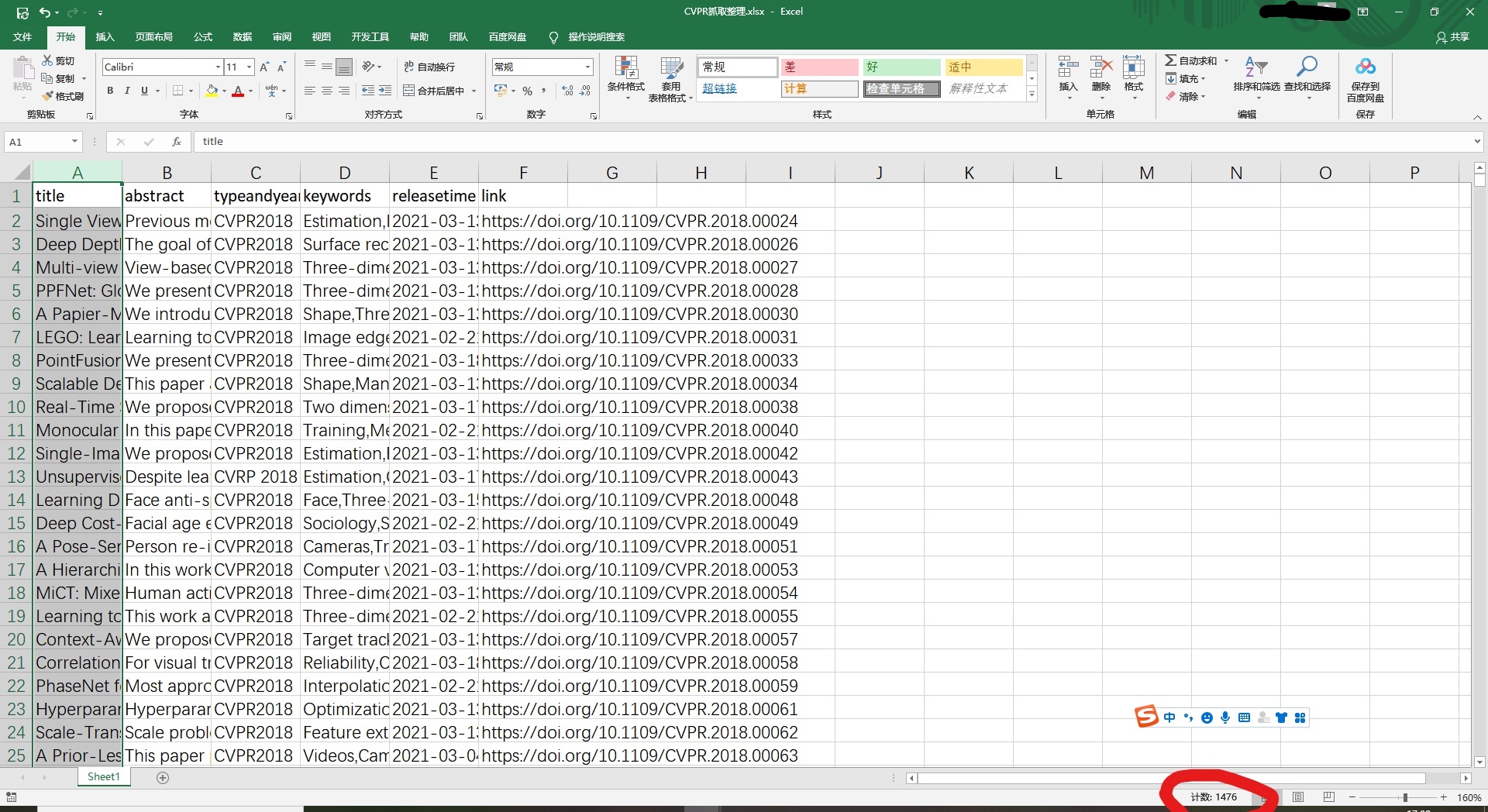
CVPR爬取后的数据库,大于300条记录,满足要求
项目部署
本次项目需要部署到云服务器上,并且在博客中给出链接
编码要求
github使用
-
Fork下面仓库,然后在根目录中新建一个以学号1&学号2(两位结对成员的学号)命名的文件夹,并至少进行20次以上的commit修改,两人至少分别提交10次以上,commit记录应该符合项目实情,如果虚构会被扣去所有分数。仓库目录结构没有硬性要求,但要保证可以依靠此仓库提供的代码来构建项目。
https://github.com/kofyou/PairProject -
对于非仓库要求的代码,如编译器生成的项目文件、输出文件、class、jar包、exe等,应该使用.gitignore进行忽略,并确保不会提交到github上。

-
为自己的仓库编写README.md,内容包括,作业链接、结对学号、项目介绍。
-
在这次编程合作中学习使用Git分支、Release发布及其他高级功能。建立一条dev分支,让你的队友和你在dev分支上开发,开发结束后再合并到main分支。在基本功能开发完成后发布release包,标注版本为1.0.0,后边完成更多功能可以继续发布新的release包。
-
在完成项目后,deadline之前,请正确发起一个Pull Requet ,并确保自己的代码最终成功签入。(如果成功签入会在原始项目主页看到自己学号为名的文件夹)
代码规范制定
这一次作业仍然需要编写一份codestyle.md作为代码规范,但是要求该代码规范来自于主流的官方规范或者大公司推荐的规范,并在代码规范顶部标注来源。
技术和框架
使用基于Web来开发,使用Web框架,如JSP、Servlet、等系列
博客撰写要求
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 100 | 130 |
| •Estimate | •估计这个任务需要多少时间 | 1200 | 1310 |
| Development | 开发 | 60 | 70 |
| •Analysis | •需求分析 (包括学习新技术) | 120 | 310 |
| •Design Spec | •生成设计文档 | 20 | 40 |
| •Design Review | •设计复审 | 20 | 50 |
| •Coding Standard | •代码规范(为目前的开发制定合适的规范) | 30 | 60 |
| •Design | •具体设计 | 60 | 90 |
| •Coding | •具体编码 | 240 | 410 |
| •Code Review | •代码复审 | 60 | 130 |
| •Test | •测试(自我测试,修改代码,提交修改) | 20 | 40 |
| Reporting | 报告 | 100 | 160 |
| •Test Repor | •测试报告 | 20 | 45 |
| •Size Measurement | •计算工作量 | 20 | 40 |
| •Postmortem & Process Improvement Plan | •事后总结, 并提出过程改进计划 | 60 | 110 |
| 合计 | 2130 | 2880 |
Github仓库地址
云服务器的访问链接
展示你的成品
结对讨论过程描述
刚拿到题目回顾了一下结对作业一的顶会热词统计原型设计

遇到的问题:对题目的实现的效果不是很清晰,怕达不到第一次原型设计的作业呈现的效果;编程上,不知道从何下手,对相关技术不是很了解,使用什么技术和框架?使用什么开发工具?以及GitHub的使用还不是很熟练,再一个就是结对编程的经验不足,可能存在分工等问题(虽然好像没有?)
解决的方法:对第一次原型设计的作业实现在进行需求分析和设计,优化模型实践;技术上使用刚刚在学习的JavaEE相关知识进行开发,在CSDN、b站、博客园等进行servlet+jsp等相关技术学习,使用IDEA配合GitHub开发。实现了良好的效果。
查找的资料和过程:
我们在CSDN、b站、博客园等进行servlet+jsp等相关技术学习。相关🔗如下:
https://space.bilibili.com/19789508?spm_id_from=333.788.b_765f7570696e666f.1
https://www.bilibili.com/video/BV1uv411q7i3
https://blog.csdn.net/weixin_44100514/article/details/86408840
以及周筠编辑提供的学习榜样
https://www.cnblogs.com/ZCplayground/p/6539235.html
https://www.cnblogs.com/wenhongyu/archive/2017/12/06/7992028.html
结对讨论过程截图

代码说明
特别说明:本项目为个人学习用途,非商业用途,可能存在使用部分网络代码,或模块化代码块以及其他已存在的代码。对于重复使用的代码,我们不做任何商业用途,仅仅作为学习目的、交流、模仿、借鉴,没有任何抄袭等其他意图,如果您不希望您的代码出现在我们的程序内,请您联系我们删除,谢谢您的理解与支持。
1.SearchServlet用post方法处理主页的搜索(附加换页功能的后端处理)和详情页的删除。dopost方法套用模板来做。queryPapers用req传来的参数来判断现在第几页以及论文的关键词来查询。
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String type = req.getParameter("type");
switch (type) {
case "1": // 保存
break;
case "2": // 编辑
break;
case "3": // 删除
deletePaper(req, resp);
break;
default: // 查询
queryPapers(req, resp);
}
}
public void queryPapers(HttpServletRequest req, HttpServletResponse resp) {
try {
PaperService paperService=new PaperServiceImpl();
Paper tempPaper=new Paper();
tempPaper.setPaperTitle(req.getParameter("pTitle"));
tempPaper.setPaperKeyword(req.getParameter("pKeyword"));
tempPaper.setPaperReleasetime(req.getParameter("PaperReleasetime"));
String pageNum = req.getParameter("pageNum");
String changeNum = req.getParameter("changeNum");
// pl每页显示的记录行数, pn当前页码,cn(上一页、下一页、查询),tn总的记录数
int pl = 10, pn = 1, cn = 0, tn = paperService.queryNumber(tempPaper);
// tp总的页数
int tp = tn / 10 + (tn % 10 == 0 ? 0 : 1);
// 当根据查询条件查询结果为空时,总页数默认为1页
if (tp == 0) {
tp = 1;
}
if (pageNum != null && !"".equals(pageNum)) {
pn = Integer.parseInt(pageNum);
}
if (changeNum != null && !"".equals(changeNum)) {
cn = Integer.parseInt(changeNum);
}
if (!(pn == 1 && cn == -1) && !(pn == tp && cn == 1)) {
pn = pn + cn;
}
if (pn > tp) {
pn = tp;
}
List<Paper> list = paperService.queryPapers(tempPaper, pn, pl);
req.setAttribute("paper", tempPaper);
req.setAttribute("pageNum", pn);
req.setAttribute("totalPageNum", tp);
req.setAttribute("totalNum", tn);
req.setAttribute("paperList2", list);
req.getRequestDispatcher("paperList.jsp").forward(req, resp);
} catch (SQLException throwables) {
throwables.printStackTrace();
} catch (ServletException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
int deletePaper(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String Link=req.getParameter("pLink");
PaperService paperService=new PaperServiceImpl();
System.out.println(paperService.deletePaper(Link));
req.getRequestDispatcher("paperList.jsp").forward(req, resp);
return 0;
}
2.用get方法处理词云功能中点击单词传给服务器的url并实现搜索。由于词云只能传网页地址过来故实现doget,逻辑上与dopost差不多
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
try
{
PaperService paperService=new PaperServiceImpl();
Paper tempPaper=new Paper();
/* tempPaper.setPaperTitle(req.getParameter("pTitle"));*/
String keyword=new String(req.getParameter("name").getBytes("ISO8859-1"),"UTF-8");
tempPaper.setPaperKeyword(keyword);
/* tempPaper.setPaperReleasetime(req.getParameter("PaperReleasetime"));*/
String pageNum = "1";
String changeNum = "0";
// pl每页显示的记录行数, pn当前页码,cn(上一页、下一页、查询),tn总的记录数
int pl = 10, pn = 1, cn = 0, tn = paperService.queryNumber(tempPaper);
// tp总的页数
int tp = tn / 10 + (tn % 10 == 0 ? 0 : 1);
// 当根据查询条件查询结果为空时,总页数默认为1页
if (tp == 0) {
tp = 1;
}
if (pageNum != null && !"".equals(pageNum)) {
pn = Integer.parseInt(pageNum);
}
if (changeNum != null && !"".equals(changeNum)) {
cn = Integer.parseInt(changeNum);
}
if (!(pn == 1 && cn == -1) && !(pn == tp && cn == 1)) {
pn = pn + cn;
}
if (pn > tp) {
pn = tp;
}
List<Paper> list = paperService.queryPapers(tempPaper, pn, pl);
req.setAttribute("paper", tempPaper);
req.setAttribute("pageNum", pn);
req.setAttribute("totalPageNum", tp);
req.setAttribute("totalNum", tn);
req.setAttribute("paperList2", list);
req.getRequestDispatcher("paperList.jsp").forward(req, resp);
} catch (SQLException throwables) {
throwables.printStackTrace();
} catch (ServletException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
3.搜索(附加换页功能)与删除的jsp页面 用表单来post,遍历论文列表用le表达式。
<div id="divcss5">
<form method="post" id="queryForm" action="<%=path%>/SearchServlet">
<input type="text" name="pTitle" value="${paper.paperTitle}" placeholder="论文标题"/><br><br>
<input type="text" name="pKeyword" value="${paper.paperKeyword}" placeholder="论文关键词"/><br>
<input type="hidden" name="pLink" value="${paper.paperLink}" placeholder="论文链接"/>
<input type="hidden" name="type" value="0" />
<input type="hidden" name="pageNum" value="${pageNum}" />
<input type="hidden" id="changeNum" name="changeNum" value="" />
<button onclick="changePage(0);" id="btnSearch">查 询</button>
</form>
</div>
<table border="1">
<tr>
<td>序号</td>
<td>论文标题</td>
<td>论文会议</td>
<td>论文摘要</td>
<td>关键词</td>
<td>论文时间</td>
<td>论文链接</td>
<td>操作</td>
</tr>
<c:forEach items="${paperList2}" var="l" varStatus="vs">
<tr>
<td>${vs.index + 1}</td>
<td>${l.getPaperTitle()}</td>
<td>${l.getPaperTypeYear()}</td>
<td style="font-size:5pt;width: 400px">${l.getPaperAbstract()}</td>
<td>${l.getPaperKeyword()}</td>
<td>${l.getPaperReleasetime()}</td>
<td>${l.getPaperLink()}</td>
<td>
<%--<button type="button" onclick="">编 辑</button>--%>
<%--<button type="button" onclick="deletePaper(l.getPaperLink())">删 除</button>--%>
<form method="post" id="deleteForm" action="<%=path%>/SearchServlet">
<input type="hidden" name="pLink" value="${l.getPaperLink()}"/>
<input type="hidden" name="type" value="3" />
<input type="hidden" name="pageNum" value="${pageNum}" />
<input type="hidden" name="changeNum" value="" />
<button onclick="deletePaper(${l.getPaperLink()});">删除</button>
</form>
</td>
</tr>
</c:forEach>
</table>
<button type="button" onclick="changePage(-1)">上一页</button>
<button type="button" onclick="changePage(1)">下一页</button>
第 ${pageNum}页 共${totalPageNum} 页 ,共 ${totalNum} 条记录
</body>
</html>
<script>
function changePage(num) {
document.getElementById("changeNum").value = num;
document.getElementById("queryForm").submit();
}
function deletePaper(link)
{
document.getElementById("changeNum").type=3;
document.getElementById("queryForm").pLink=link;
document.getElementById("queryForm").submit();
}
</script>
4.页面划分为左菜单与右主页面的实现 用frame来划分
<html>
<title>论文检索系统</title>
<frameset cols="120,*">
<frame src="leftMenu.jsp">
<frame src="paperList.jsp" name="rightframe">
</frameset>
</html>
5.词云跳转实现 数据是使用WordCount程序统计关键词然后手动输入到程序中。数据项中的url数据项是点击的跳转链接 词云调用现成的js文件实现
data: [
{
name: 'iamge',url:"SearchServlet?name=image",
value: 10000,
textStyle: {
normal: {
color: 'black'
},
emphasis: {
color: 'red'
}
}
},
{
name: 'learning',url:"SearchServlet?name=learning",
value: 6181
},
......
chart.on("click",function(e)
{
window.open(e.data.url);
});
6.按条件查询的sql语句写法 where 1=1来防止出现sql语句的错误
@Override
public List<Paper> queryUsers(Paper p, int pageNum, int lineNum) throws SQLException {
int limit_x = (pageNum - 1) * lineNum;
int limit_y = lineNum;
StringBuffer sql = new StringBuffer("select * from paperInfo ");
sql.append(" where 1 = 1 ");
if (p.getPaperAbstract() != null && !"".equals(p.getPaperAbstract())) {
sql.append(" and PaperAbstract like '%" + p.getPaperAbstract() + "%' ");
}
if (p.getPaperKeyword() != null && !"".equals(p.getPaperKeyword())) {
sql.append(" and PaperKeyword like '%" + p.getPaperKeyword() + "%' ");
}
if (p.getPaperLink() != null && !"".equals(p.getPaperLink())) {
sql.append(" and PaperLink like '%" + p.getPaperLink() + "%' ");
}
if (p.getPaperReleasetime() != null && !"".equals(p.getPaperReleasetime())) {
sql.append(" and PaperReleasetime like '%" + p.getPaperReleasetime() + "%' ");
}
if (p.getPaperTitle() != null && !"".equals(p.getPaperTitle())) {
sql.append(" and PaperTitle like '%" + p.getPaperTitle() + "%' ");
}
if (p.getPaperTypeYear() != null && !"".equals(p.getPaperTypeYear())) {
sql.append(" and PaperTypeYear like '%" + p.getPaperTypeYear() + "%' ");
}
sql.append(" order by PaperTitle ");
sql.append(" limit " + limit_x + "," + limit_y);
System.out.println(sql.toString());
List<Paper> list = new ArrayList<>();
MysqlDB mysqlDB = new MysqlDB();
Connection conn = mysqlDB.getConn();
Statement stmt = null;
ResultSet rs = null;
try {
stmt = conn.createStatement();
rs = stmt.executeQuery(sql.toString());
while (rs.next()) {
Paper tempPaper = new Paper();
tempPaper.setPaperTitle(rs.getString("paperTitle"));
tempPaper.setPaperAbstract(rs.getString("paperAbstract"));
tempPaper.setPaperLink(rs.getString("paperLink"));
tempPaper.setPaperKeyword(rs.getString("paperKeyword"));
tempPaper.setPaperTypeYear(rs.getString("PaperTypeYear"));
tempPaper.setPaperReleasetime(rs.getString("PaperReleasetime"));
list.add(tempPaper);
}
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
rs.close();
stmt.close();
conn.close();
}
return list;
}
7.热词统计 热词统计功能调用echart来实现。数据也是用WordCount程序统计关键词然后手动输入到程序中。
<div id="main" style="width: 1536px;height:864px;"></div>
<script type="text/javascript">
var myChart = echarts.init(document.getElementById('main'));
var yearlist = ['2015','2017','2019'];
var countryList = ['image','learning','object','feature','computer','analysis','recognition','detection','vision','reconstruction'];
var option = {
timeline:{
axisType: 'category',
autoPlay: true,
playInterval: 1500,
data: yearlist,
label:{
fontSize: 18
}
},
baseOption:{
dataset:{
source:[
['year','image','learning','object','feature','computer','analysis','recognition','detection','vision','reconstruction'],
['2015',1125,
277,
271,
260,
245,
237,
228,
221,
220,
190 ],
历程与收获和评价
阅读《构建之法》第四章的内容,结合在构建之法中学习到的相关内容,结对伙伴分别撰写结对开发项目的心路历程与收获,并评价结对队友。
031801124
这次结队开发正好可以运用刚刚学习的javaee的内容,正好我们两人都有上javaee的选修课,所以在技术上沟通比较畅通,在磨合阶段很顺利。也很快就确定了用servlet+jsp的结构来实现项目。之后的实现功能和前端设计在团队合作下推进的很顺利,合作得很不错。git熟练使用后效果很好,update队友的代码按按钮就好了。
这次除了javaee课上学的还学到了servlet用get来跳转链接,学会了echart和爬虫工具的使用。最后效果令人满意。队友评价:
031801124:
善于沟通,对作品态度认真,效率很高!跟他合作起来完成这项作业非常愉快。
221801126
我在阅读《构建之法》的四五章后,明白了结对编程不仅需要实现实际功能,满足用户需求,还有许多其他需要考虑的地方,代码依赖、codestyle代码规范、代码可读性、单元测试、黑白盒测试等等,对此我阅读了许多CSDN和博客园的相关文章,重新增加和删改了之前的代码规范和相关文档,如首先对文件进行合理划分,再者通过添加必要的注释,增加代码可读性,还有就是在函数命名时也尽量采用有意义的命名等等。
这次结对编程刚开始有些坎坷,比如GitHub建仓库的时候有些问题,加之我们俩也是刚刚开始学习javaEE,一开始进度不是很快。后来在开发过程中,两个人经过沟通,共同进步,互帮互助,学习了servlet+jsp的结构来实现项目,还有echarts实现图表。还学会了GitHub团队合作开发,所谓实践出真知,你没有试过犯错,就永远不知道什么时候pull会出错......我觉得我们的团队模式很和谐,两个人各有分工,不会出现谁主导的情况。最后,希望接下来的作业对我温柔一点……
队友评价:
221801126
这次结对作业是我第二次进行两个人组队编程,我的队友认真负责,善于沟通,碰到不会的难题也非常积极地去解决,是一个非常好的队友,和他合作非常愉快。和他相互交流沟通也是让我受益匪浅,我知道了一个产品的顺利开发是需要团队的一起努力的结果,宇哥是十分的棒,一有问题就及时沟通,节省了许许多多的时间,提高了开发的效率。这两次的结对作业下来,一起收获很多,合作很愉快!~
写在最后:
特别说明:本项目为个人学习用途,非商业用途,可能存在使用部分网络代码,或模块化代码块以及其他已存在的代码。对于重复使用的代码,我们不做任何商业用途,仅仅作为学习目的、交流、模仿、借鉴,没有任何抄袭等其他意图,我们已经最大程度体现我们的代码学习来源和其他获取代码的方式。如果有遗漏,或者如果您不希望您的代码出现在我们的程序内,请您联系我们删除,谢谢您的理解与支持。Salute&Peace.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号