
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | <作业要求的链接> |
| 这个作业的目标 | 阅读《构建之法》并提问,完成词频统计程序,撰写博客 |
| 其他参考文献 | CSDN github 单元测试等相关链接 各位老师的博客园 |
目录:
part1:阅读《构建之法》并提问
题目要求:
一、基本要求
一、快速看完整部教材(教材开学会发,可以先看邹欣老师的博客园讲义),列出你仍然不懂的5到10个问题,发布在你的个人博客上。如何提出有价值的问题? 请看这个文章,以及在互联网时代如何提问题。 还有这些要点:
在每个问题后面,请说明哪一章节的什么内容引起了你的提问,提供一些上下文。
列出一些事例或资料,支持你的提问 。
说说你提问题的原因,你说因为自己的假设和书中的不同而提问,还是不懂书中的术语,还是对推理过程有疑问,还是书中的描述和你的经验(直接经验或间接经验)矛盾?
一个模板可以是这样:
我看了这一段文字(引用文字),有这个问题(提出问题)。我查了资料,有这些说法(引用说法),根据我的实践,我得到这些经验(描述自己的经验)。 但是我还是不太懂,我的困惑是(说明困惑)。
【或者】我反对作者的观点(提出作者的观点,自己的观点,以及理由)。
我的完成:
3.2 软件工程师的思维误区
如同书上提出的概念:分析麻痹:一种极端情况是想弄清楚所有细节、所有依赖关系之后再动手,心理上过于悲观,不想修复问题,出了问题都赖在相关问题上。分析太多,腿都麻了,没法起步前进,故得名“分析麻痹”( Analysis Paralysis )。下面是工程师果冻和项目经理大牛之间的对话:
木桶有一个洞,咋办啊,大牛?
修哇,果冻!
用啥来修啊,大牛?
用粗麻绳把它堵上,果冻!麻绳太长,咋办啊,大牛?
用刀砍短啊,果冻!刀太钝,咋办啊,大牛?
磨刀啊,果冻!
磨刀石太干,咋办啊,大牛?
拿木桶去取水啊,果冻!木桶有一个洞,咋办啊,大牛?
Q:确实是开发的通病,想弄清楚所有细节、所有依赖关系之后再动手,心理上过于悲观,不想修复问题,出了问题都赖在相关问题上。分析太多,腿都麻了,没法起步前进。但是如果不进行细节的厘清,可能也会在之后的开发中产生问题。如何正确解决上述心理呢?
我的想法是:将时间在分析和实践里面进行权衡和取舍,大的项目先勾勒出轮廓,在构建的同时再进行细节处理。但是这个权衡的“度”要怎么把握呢?
5.2.10官僚模式
书上提到:这种模式脱胎于大机构的组织架构,几个人报告给一个小头目,几个小头目报告给中头目,依次而上。这种模式在软件开发中会出问题。因为成员之间不光有技术方面的合作和领导,同时还混进了组织上的领导和被领导关系。跨组织的合作变得比较困难,因为各自头顶上都有不同的老板。
Q:通过阅读,我了解到了“官僚模式”的软件开发的弊端。承认其模式有之弊病之处,但是在日常的生活工作中还是会有类似的开发经历。书中没有提到此模式的优点和改进,这是我的疑问。
我的想法是:将次模式的优点最大化,因为此模式中存在领导,可将其监督职能发挥作用,提高效率。但是剩下的方法我还没有想到。
6.1敏捷的流程
在《构建之法》的第六章中:在软件工程的语境里,"敏捷流程”是一系列价值观和方法论的集合。从2001年开始,一些软件界的专家开始倡导“敏捷”的价值观和流程,他们肯定了流行做法的价值,但是强调敏捷的做法更能带来价值。
Q:“迅敏流程”是一系列价值观和方法论的集合。迅敏开发的原则有:1.尽早并持续的交付有价值的软件以满足顾客要求 2.欢迎需求的变化,并利用这种变化来提高用户竞争优势等等。但是以现实情况来看,这些要求是否过于难以实现了。同时在后文中提到,对于团队来说,如果你的团队很弱,那么强行把敏捷(或其他高级方法)套在上面也没用,也许还会适得其反,如果团队已经有这么厉害,那么不用scrum也能写好软件。那么迅敏这一思想的意义在哪里?
我的想法:坚守原则,交付有价值的软件以满足顾客要求,提高团队能力。但是我还是对迅敏这一思想的意义不够理解。
8.7分而治之
在书本第八章中提到:WBS通常从最终的产品开始,一层一层往下,把大型交付件( Deliverable)分割为小型、具体的交付件。这样的分割可以持续下去,直到WBS的使用者(开发团队、接收方)达到共识。从数据结构方面来看,WBS分割的结果是一棵树。所有子节点都最终有一个根节点。每个节点描述的是要交付的产品或文档,而不是开发团队的努力或花费(各个叶节点的成本可以作为次节点的属性展现出来)。
Q:从中我了解到:1.保证所有子节点覆盖了全部父节点包含的内容。2.保证各个子节点不要相互覆盖。3.叶子节点要保证足够小,能在一个里程碑中完成。在通常的软件项目中,叶节点的成本最好不要超过两周。如果团队成员从常理出发,认为叶节点不宜再分下去,那就可以停止。4.从结果(Outcome)出发构建WBS,而不是从团队的活动(Action )出发。但是模块之间的联系如何实现呢?
我的想法是:对于各模块负责人在开发过程中保持沟通,使用各种接口进行模块调用,或在开始的设计文档时就提出解决方法。但是这只是我对于WBS的猜想,网上对于专业要求较高的WBS的文档还是比较少,且我对于具体的实践还没有遇到,故在此做个疑问。
12.2用户体验设计的步骤和目标
用户体验和用户界面设计的目的是什么?有哪些步骤呢?一些没有经验的工程师觉得,“我先把代码写好,然后有一些会画图的人来把界面改一改就好了……”,这种想法是非常幼稚和有害的。另一方面,如果认为工程师只能等着设计师的线框图才能开始工作,这也是同样幼稚的。用户体验设计的一个重要目的就是要降低用户的认知阻力(Cog-nitive Friction),即用户对于软件界面的认知(想象某事应该怎么做,想象某操作应该产生什么结果)和实际结果的差异。
Q: 一些软件设计的各种方式也没有办法做到不学就上手,顶多算是学起来图形化界面比较完整,相比起LaTex等论文编辑器更容易上手罢了。而且对于一些软件下载后也没有很好的简易教程交给用户,很多人都不知道这个功能。那么如果大多数用户都不了解,不会用到的功能是否还有必要去开发呢?
我的想法:此类的软件应配备简易的图文流程。就像百度网盘更新都会通过五六步的图文引导来简明快捷的介绍最新版本增加的新功能。同时之前章节有举例飞机的安全功能,虽然几率小但是还是要做。但是放在此处说明开发的重要性好像又不合适。
第16章IT行业的创新
文章提到:关于创新,有哪些似是而非的论断? WIIFM ( What's In It for Me ) ?创新者的困境,创新的时机,创新路上的鸿沟(Chasm),先发优势和后发优势,改良式的创新和颠覆式的创新,效能过剩,NPS,CAC、用户留存率的名词
Q:关于创新其实有许多有趣的话题可以谈:比如伟大的创新来自灵光一闪吗?2.人人都喜欢做创新?不一定,有时候创新者自己就不喜欢创新,希望自己的成果不要被颠覆 3.创新者一定是一马当先的吗?
我的想法:创新分两种:1.持续性创新2.颠覆性创新。且在创新之前,要有很多的基础准备工作,知识的储备;对于好的想法要看用户已有的习惯。后来者分析了领先者的劣势,进行了改进,厚积薄发。当然还是要实践才能出真知,不可纸上谈兵。
16.2.3创新的时机、方法
《构建之法》第十六章提到:在不少场合提到这个黄金点游戏:N个同学(N通常大于10 ),每人写一个0-100之间的有理数(不包括0或100 ),交给裁判,裁判算出所有数字的平均值,然后乘以0.618(所谓黄金分割常数),得到G值。提交的数字最靠近G(取绝对值)的同学得到N分,离G最远的同学得到-2分,其他同学得0分。玩了几天以后,大家发现了一些很有意思的现象,比如黄金点在逐渐地往下移动。如果你和其他20个聪明人玩这个游戏,你会选择什么数字呢?
Q:哪些决定更利于创新,哪些决定在某种程度上阻碍了创新?创新的时机、方法?
我的想法:文章有一个具体的例子,如果用户(一个生活在中国二线城市,有高中文化水平,有基本计算机基础的成年人)要在一个文稿中写居中的一句话,在下表所列的各种工具中,用户是怎么才能做到的。 倘若认知阻力大,学习曲线就会比较陡;但是经过学习和练习,如果用户适应了新的认知模式,工作效率便会有较大的提高。时机方法同理一个团队的产品(或者产品群)和众多竞争对手在各个市场上竞争,谁都想赢,但是在竞争的环境中有很多的因素需要考虑,一个团队的资源总是有限的,不可能什么都做,每天要做很多具体的决定。
二、附加题
大家知道了软件和软件工程的起源,请问软件工程发展的过程中有什么你觉得有趣的冷知识和故事?
小知识:Git来自于Linux的创始人Linus,只花了两周时间自己他就用C写了一个分布式版本控制系统!
很多人都知道,Linus在1991年创建了开源的Linux,从此,Linux系统不断发展,已经成为最大的服务器系统软件了。Linus虽然创建了Linux,但Linux的壮大是靠全世界热心的志愿者参与的,这么多人在世界各地为Linux编写代码,那Linux的代码是如何管理的呢?事实是,在2002年以前,世界各地的志愿者把源代码文件通过diff的方式发给Linus,然后由Linus本人通过手工方式合并代码!不过,到了2002年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是Linus选择了一个商业的版本控制系统BitKeeper,BitKeeper的东家BitMover公司出于人道主义精神,授权Linux社区免费使用这个版本控制系统。安定团结的大好局面在2005年就被打破了,原因是Linux社区牛人聚集,不免沾染了一些梁山好汉的江湖习气。开发Samba的Andrew试图破解BitKeeper的协议(这么干的其实也不只他一个),被BitMover公司发现了(监控工作做得不错!),于是BitMover公司怒了,要收回Linux社区的免费使用权。Linus可以向BitMover公司道个歉,保证以后严格管教弟兄们,嗯,这是不可能的。实际情况是这样的:Linus花了两周时间自己用C写了一个分布式版本控制系统,这就是Git!一个月之内,Linux系统的源码已经由Git管理了!牛是怎么定义的呢?大家可以体会一下。Git迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub,包括jQuery,PHP,Ruby等等。
历史就是这么偶然,如果不是当年BitMover公司威胁Linux社区,可能现在我们就没有免费而超级好用的Git了。
part2:WordCount编程
-
Github项目地址
https://github.com/yangzishen/PersonalProject-C
-
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 420 | 600 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 30 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 200 | 200 |
| • Coding | • 具体编码 | 500 | 600 |
| • Code Review | • 代码复审 | 30 | 120 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 200 | 180 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 60 |
| • Size Measurement | • 计算工作量 | 30 | 60 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 1800 | 2000 |
-
解题思路描述
基本需求
假设有一个软件每隔一小段时间会记录一次用户的搜索记录,记录为英文。
输入文件和输出文件以命令行参数传入。例如我们在命令行窗口(cmd)中输入命令
则会统计input.txt中的以下几个指标
统计文件的字符数(对应输出第一行):
统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
然后将统计结果输出到output.txt,输出的格式如下;其中
word1和word2对应具体的单词,number为 统计出的个数;换行使用'\n',编码统一使用UTF-8。
我先分析了程序的几个需求:
文件需要通过命令行输入输出 使用C++的文件处理流来处理I/O操作
统计字符 使用
string类自带的长度统计函数解决统计单词总数 此处需要
- 判断是否为单词 通过逻辑判断函数处理
- 不同单词的区分 使用
map- 统计单词个数 同步计数即可
- 有效行数
- 判断换行符
- 判断是否为空行
- 判断是否有
\t \n \r null字符出现
- 容错性 使用抛出捕获异常处理
我将程序分为一下三个文件,采用 输入->字符处理->输出 的结构完成编程
CountWord.cpp (主程序,可以从命令行接收参数)
Lib.h(包含其它自定义函数)
Lib.cpp(包含其它自定义函数)
流程图: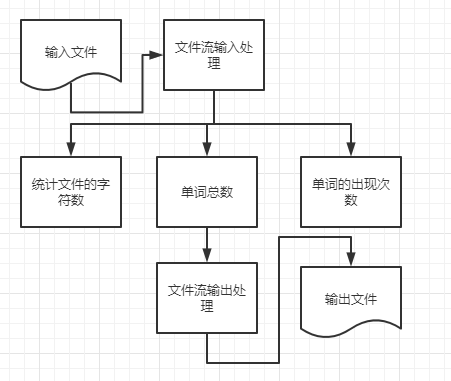
-
代码规范制定链接
代码的规范:
https://github.com/yangzishen/PersonalProject-C/blob/main/221801126/codestyle.md
-
设计与实现过程
计算模块接口的设计与实现过程。
接口函数:
string InputFile(const char* filename);输入接口void OutputFlie(char* filename,string inputString) ;输出接口int CountChar(string inputString);统计字符接口
int CountRow(string inputString);统计有效行接口int CountWord(string inputString);统计单词接口输入处理
使用输入接口的文件流从指定文件中输入。
string InputFile(const char* filename){ ifstream in(filename, ios::in); istreambuf_iterator<char> beg(in), end; string sstring(beg, end); in.close(); return sstring; }
输出处理
使用输出接口的文件流输出到指定文件中。
void OutputFlie(char* filename,string inputString) {
ofstream outputFlie(filename);
outputFlie << "characters: " << CountChar(inputString) << endl;
outputFlie << "words: " << CountWord(inputString) << endl;
outputFlie << "lines: " << CountRow(inputString) << endl;
···
}
统计文件的字符数
Q6:程序是否需要考虑中文
A6:不需要,可以理解为不会出现ascii码之外的字符:
经阅读Q&A可知只需要考虑ASCII码数量,所以直接输出文本字符串的长度即可。
int CountChar(string inputString) {
int count = 0;
count = inputString.length();
return count;
}
统计文件的行数
Q8:输入文件的换行
A8:作业描述疏忽了,现在补充一下:输入文件的换行标识也是'\n',同时'\r'需要计入字符总数。例如,下面两个文本的行数都是2,字符数分别是13和12。
"hello\r\nworld!"
"hello\nworld!"
经阅读Q&A可知只需要考虑通过对前一字符不是 空白字符 的\n进行统计,即可得到不是空白行数
int CountRow(string inputString) {
int i = 1;
int sum = 0;
while (i < inputString.length()) {
if ( inputString[i] == '\n') {
if(!IsBlankChar(inputString[i-1]))
sum++;
}
i++;
}
return sum;
}
统计文件的单词
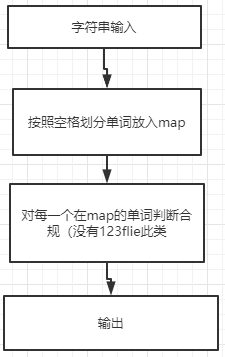
遍历,将 每两个空白字符之间的字母和数字 判断为一个 备选字符 放入map;遍历map,如果不满足单词条件:(1:前4个为字母,或(2不足4个字符 的剔除出map。需要统计词频时候排序输出即可。
int CountWord(string inputString) {
int sum = 0;
···
for (int i = 0, j = 0; j < inputString.length() && i < inputString.length();) {
if (IsEnglishLetter(inputString[i])) {
j = i;
bool flag = 1;
···
map<string, int>::iterator it = m.begin();
while (it != m.end()) {
if (it->second > 1) {
sum += it->second - 1;
}
it++;
}
···
return sum;
}
-
性能改进
-
由测试可见,随着统计字符的增加,I/O的时间被放大,文件I/O消耗量巨大,故需要改进文件的读写方式,提高文件效率。
-
此外,程序中需要多次遍历所以输入的字符,也是消耗时间很大的占比。
-
还有一些频繁的函数调用的值的消耗,如
string类中.length()的值可以存起来作为全局变量调用,减少开销。
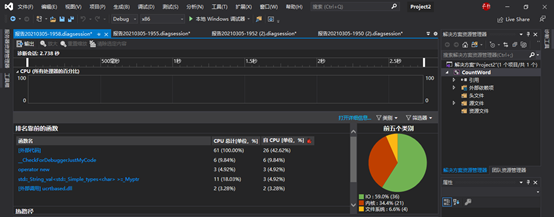
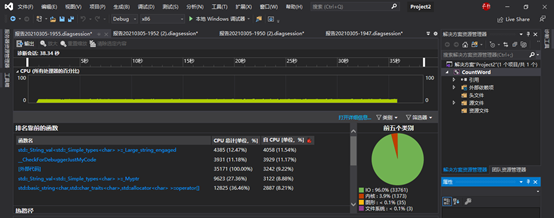
-
单元测试
测试使用系统命令行进行,命令行指定输入输出文件的路径。例子如下:
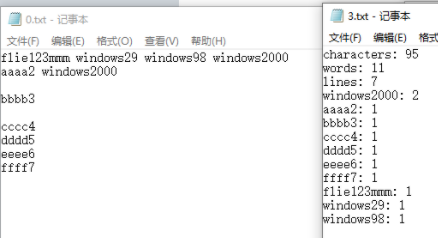
1、统计字符测试
包含\n\t\r和空格
int main(){
string inputString = "abc\n\t\r ";
cout<< CountChar(inputString);
return 0;
}
2、统计行数测试
测试函数中测试了出现空白行情况
int main(){
string inputString = "ab\n\t\r \n\nfdg3\n\n";
cout<< CountRow (inputString);
return 0;
}
3、统计单词测试
测试函数中测试了若干不满足标准的字符如:以数字开头,字母不足4个的,还有频率相同按字典序输出
int main(){
string inputString = "123asd abc111 abcd abc ";
cout<< CountWord(inputString);
return 0;
}
int main(){
string inputString = "aaaa1 aaaa1 aaaa1 aaaa1 ";
inputString =+ "aaaa2 aaaa2 aaaa2 aaaa2 ";
cout<< CountWord(inputString);
return 0;
}
大文件测试:
使用的是我之前发表的会议论文节选,贴合实际使用场景。
使用vs2019所带的单元测试的项目配置后,进行测试代码。
#include "stdafx.h"
#include "CppUnitTest.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace CalculatorUnitTest
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
//测试代码
}
};
}
异常处理说明
使用异常抛出处理:
int main(int argc, char* argv[]) {
try {
·······
}
catch(exception){
cout << "error";
}
return 0;
}
心路历程与收获
本次作业难度较大,加班加点了很久,还请老师和助教多多见谅!首先,我刚看到题目时认为很简单,只需要实现几个功能即可,实际上需要注意的东西非常多,需要考虑单词判断的逻辑,空行出现的情况,和词频统计的方法等等注意点。也正因此实际耗费时间比计划多得多,希望在下一次作业中我可以再接再厉,努力完成好!还有git相关的命令,GitHub代码的托管和commit、pr的相关操作的学习也让我收获很多。一开始我教程看了很多还是弄了半天不知道怎么找分支,fork项目,上传,询问了已经完成的同学才大致完成。所以如果有提交问题或者文件找不了还请助教告诉我一下,我立刻回复!最后是代码的测试和修改,我使用的是将main函数和其他功能函数分离的方法,测试的时候VS2019时不时的报错,也将项目的难度和所花的时间放大。所以我两种测试的方式都有使用,既有传统的写文档命令行输入看输出的白盒测试,还使用了VS测试,对我自己也收获很多!这次作业也提醒我了要摆正心态,提高技术,在下一次作业中尽快动手,努力完成的更好!

