pandas数据统计(方差/标准差/峰度/偏度/差值百分比/相关系数/排名(rank)等)
数据统计
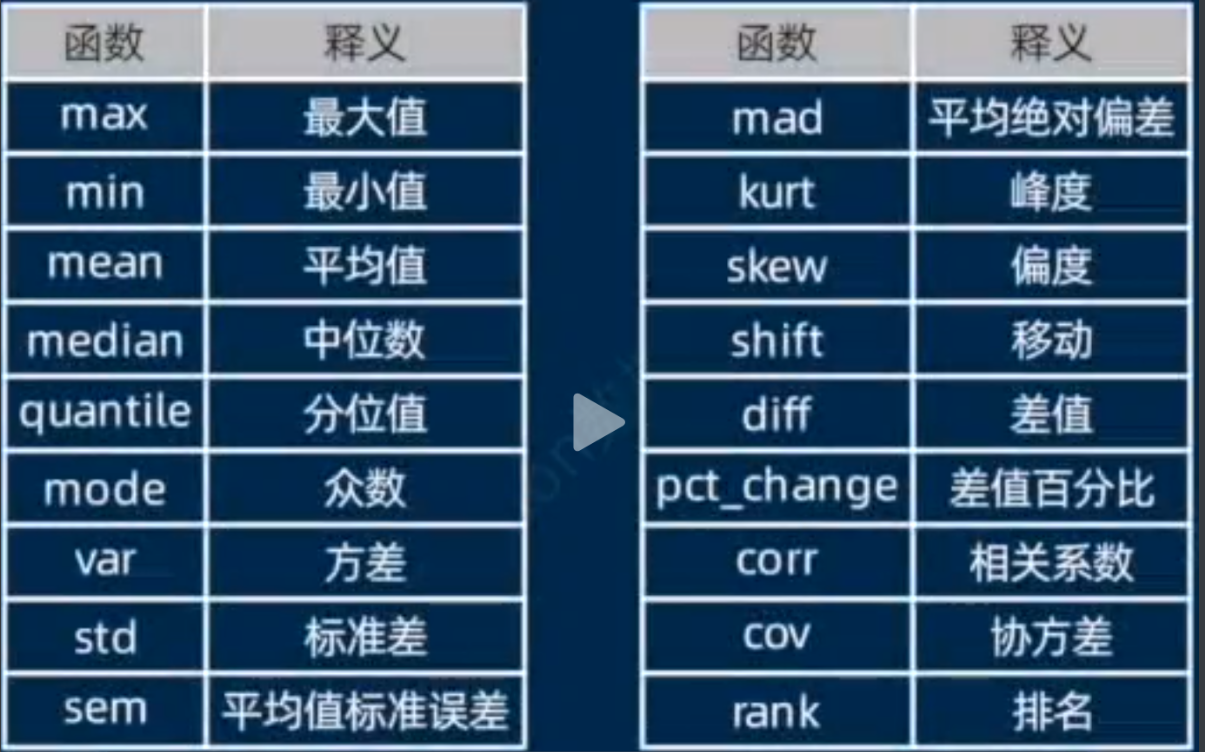
#1.中位数 median
#median()参数解释
median(
self,
axis: Axis | None | lib.NoDefault = lib.no_default,#轴方向
skipna: bool_t = True,#处理NA值,默认为true,即跳过NA值
level: Level | None = None,#对于涉及多重索引的,可以通过该参数选择具体的索引行或列
numeric_only: bool_t | None = None,#只针对数字类型进行操作,一般不建议使用
**kwargs,
)
df.median()
#2.分位值 quantile
#quantile()参数解释
med = df.quantile(q=0.5) #0.5分位值
med = df.quantile(q=0.25)#0.25分位值
med = df.quantile(q=[0.25,0.5,0.75])#q也可以是一个列表求0.25/0.5/0.75的分位值
print(med)
#3.众数 mode
#mode返回的同样是一个数据框
df1 = df.copy()
#不适用的单元格用NA填充,主要是为了迎合数据框的构造
df1.loc[0,"a"] = 90
df1.loc[0,"c"] = 75
mod = df1.mode()
print(mod)
#a,b,c列均有2个相同的数
#此时输出的结果便没有NA值
'''
输出结果
a b c
0 90 80 75
'''
#4.方差
var = df.var()
#5.标准差
df.std()
#6.标准误 sem
df.sem()
#7.平均绝对偏差 mad
#表示每个数据点与平均值之间的平均距离(最小二乘法)
df.mad()
#8.峰度(峰态系数) kurt
#表征概率密度分布曲线在平均值处峰值高低的特征数,直观来看峰度反映了峰部的尖度。样本的峰度是和正态分布相比较而言的,如果峰度>3,则峰的形状比较尖,比正态分布的峰要陡峭,峰度高就意味着方差增大是由低频度的大于或小于平均值的极端差值引起的。该函数默认是计算数据框每列的平均绝对偏差
df.kurt()
#9.偏度(偏态/偏态系数) skew
#是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征,偏度定义中包括正态分布(偏度=0),右偏分布(也叫正偏分布,其偏度>0),左偏分布(也叫负偏分布,其偏度<0)
df.skew()
#在数据处理过程中经常会涉及到同一列或同一行进行移动以及计算差值等,在pandas中提供shift、diff 、pct_change等函数来处理这些情况
#10偏移 shift
#shif函数是对数据进行偏移
#参数解释
def shift(
self,
periods: int = 1, #偏移量,默认为1
freq: Frequency | None = None,#对时间序列适用
axis: Axis = 0,
fill_value: Hashable = lib.no_default, #填充NA值的参数
)
#默认是数据框沿着0轴方向向下偏移1,对于留空的数值单元,用NA值填充,偏移后数据尾部多出来的数据被丢弃,形成行列数量与与原有数据框一致的新的数据框
#情况1:
a = {"a":[80,90,60,73,89],
"b":[80,75,80,85,83],
"c":[70,75,80,73,62]}
df = pd.DataFrame(a)
print(df)
var = df.shift()
print(var)
"""
输出结果
a b c
0 80 80 70
1 90 75 75
2 60 80 80
3 73 85 73
4 89 83 62
a b c
0 NaN NaN NaN
1 80.0 80.0 70.0
2 90.0 75.0 75.0
3 60.0 80.0 80.0
4 73.0 85.0 73.0
"""
#periods与fill_value参数的应用
a = {"a":[80,90,60,73,89],
"b":[80,75,80,85,83],
"c":[70,75,80,73,62]}
df = pd.DataFrame(a)
print(df)
var = df.shift(periods=2,fill_value=0)#沿0轴方向移动2个位置,空出来的数用0填充
print(var)
"""
输出结果
a b c
0 80 80 70
1 90 75 75
2 60 80 80
3 73 85 73
4 89 83 62
a b c
0 0 0 0
1 0 0 0
2 80 80 70
3 90 75 75
4 60 80 80
"""
#当行索引为时间序列的序列时,可以设置freq参数,该参数的值为时间偏移单位,可以按“天”、“月”等
#11差值diff
a = {"a":[80,90,60,73,89],
"b":[80,75,80,85,83],
"c":[70,75,80,73,62]}
df = pd.DataFrame(data=a)
print(df)
var = df.diff(periods=2)#沿0轴方向移动2个位置,原来数据框减去移动后的数据框后得到的值
print(var)
"""
#输出结果
a b c
0 80 80 70
1 90 75 75
2 60 80 80
3 73 85 73
4 89 83 62
a b c
0 NaN NaN NaN
1 NaN NaN NaN
2 -20.0 0.0 10.0
3 -17.0 10.0 -2.0
4 29.0 3.0 -18.0
"""
#12差值百分比 pct_change
#默认情况下,axis=0,该函数是沿着0轴方向对数据进行差值百分比计算
a = {"a":[80,90,60,73,89],
"b":[80,75,80,85,83],
"c":[70,75,80,73,62]}
df = pd.DataFrame(data=a)
print(df)
var = df.pct_change(periods=2)#沿0轴方向移动2个位置,原来数据框减去移动后的数据框后得到的值
print(var)
"""
#输出结果
a b c
0 80 80 70
1 90 75 75
2 60 80 80
3 73 85 73
4 89 83 62
a b c
0 NaN NaN NaN
1 NaN NaN NaN
2 -0.250000 0.000000 0.142857
3 -0.188889 0.133333 -0.026667
4 0.483333 0.037500 -0.225000
"""
#13相关系数:corr
df.corr()#计算数据框的相关系数
df["a"].corr(df["b"])#计算a列与b列的相关系数
#14协方差cov
df.cov()#计算数据框的协方差
df["a"].corr(df["b"])#计算a列与b列的协方差
#15排名函数rank
#参数解释
def rank(
self: NDFrameT,
axis=0,
method: str = "average",#排名计算方法设置
numeric_only: bool_t | None | lib.NoDefault = lib.no_default, #只用数字类型
na_option: str = "keep", #缺失值的处置
ascending: bool_t = True,#升序或降序的设置,默认是升序
pct: bool_t = False,#结果是否以百分比的形式呈现,日常应用如排名前百分之几
a = {"a":[80,90,60,73,89],
"b":[80,75,80,85,83],
"c":[70,75,80,73,62]}
df = pd.DataFrame(data=a)
print(df)
var = df.rank()#沿0轴方向移动2个位置,原来数据框减去移动后的数据框后得到的值
print(var)
"""
#输出结果
a b c
0 80 80 70
1 90 75 75
2 60 80 80
3 73 85 73
4 89 83 62
a b c
0 3.0 2.5 2.0
1 5.0 1.0 4.0
2 1.0 2.5 5.0
3 2.0 5.0 3.0
4 4.0 4.0 1.0
"""
#method函数,
a = {"a":[80,90,60,73,89],
"b":[80,75,80,85,83],
"c":[70,75,80,73,62]}
df = pd.DataFrame(data=a)
print(df)
var = df["b"].rank(method="min")#沿0轴方向移动2个位置,原来数据框减去移动后的数据框后得到的值
print(var)
"""
#默认情况下输出结果的有2个2.5,是并列第2名
0 2.5
1 1.0
2 2.5
3 5.0
4 4.0
当method="min",是按照最小的次序排列的
0 2.0
1 1.0
2 2.0
3 5.0
4 4.0
method="first",对于并列的情况先遇到的排在前面后遇到的排在后面
method="dense",对于并列的情况进行紧凑性排名不会有空余的名次,对排名进行压缩
"""
#na_option参数
a = {"a":[80,90,60,73,89],
"b":[80,75,80,85,83],
"c":[70,75,80,73,62]}
df = pd.DataFrame(data=a)
df1 =df.copy()
df1.loc[0,"b"] = np.nan
df1.loc[3,"b"] = np.nan
var = df1.rank(na_option="bottom",method="first")#沿0轴方向移动2个位置,原来数据框减去移动后的数据框后得到的值
print(var)
"""
当参数na_option='keep'时,保留Na值
a b c
0 3.0 NaN 2.0
1 5.0 1.0 4.0
2 1.0 2.0 5.0
3 2.0 NaN 3.0
4 4.0 3.0 1.0
当参数na_option='top'时,Na值放前边
a b c
0 3.0 1.5 2.0
1 5.0 3.0 4.0
2 1.0 4.0 5.0
3 2.0 1.5 3.0
4 4.0 5.0 1.0
当参数na_option='bottom'时,Na值放前边
a b c
0 3.0 4.0 2.0
1 5.0 1.0 4.0
2 1.0 2.0 5.0
3 2.0 5.0 3.0
4 4.0 3.0 1.0
"""
记录学习的点点滴滴

 浙公网安备 33010602011771号
浙公网安备 33010602011771号