python爬虫
python爬虫
## 1.Python爬虫架构
-
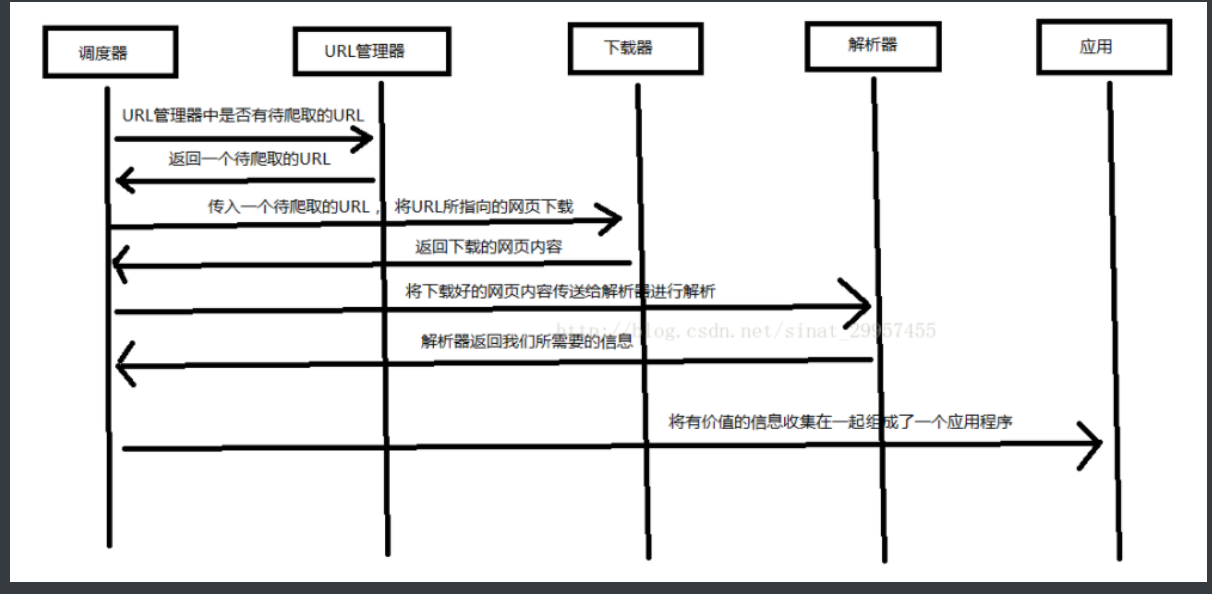
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
-
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
-
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
-
网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
-
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
-
应用程序:就是从网页中提取的有用数据组成的一个应用。
2.爬虫的合法性
- 几乎每一个网站都有一个名为 robots.txt 的文档,当然也有部分网站没有设定 robots.txt。对于没有设定 robots.txt ,也就是该网站所有页面数据都可以爬取。如果网站有 robots.txt 文档,就要判断是否有禁止访客获取的数据。
- 查看robot协议的方法——>网站首页有效URL + /robots.txt
3.抓去数据的两种方式:GET/POST
- 在抓去数据时先从header先看看是get方式还是post方式
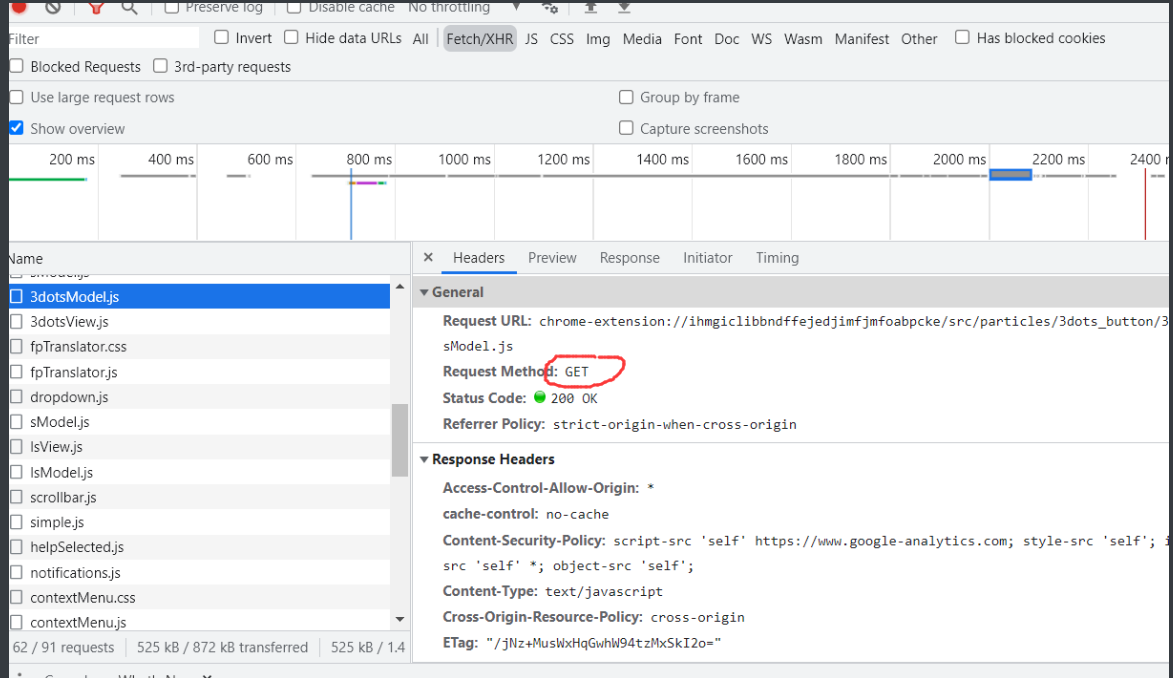
- 记住无论是header或者data都是字典型的!
1.get方法
import requests
# get方法
url = "http://www.cntour.cn/"
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
#头部伪装,
# 节点伪装
strhtml = requests.get(url,headers=header) #此时返回的为一个对象
print(strhtml.text)#解析内容
#本身而言,get其实一个url就可以了,即单单的一个网址就够了,后去可以加from data,代理节点啊,什么的都是为了提高爬虫的效率
2.post方法
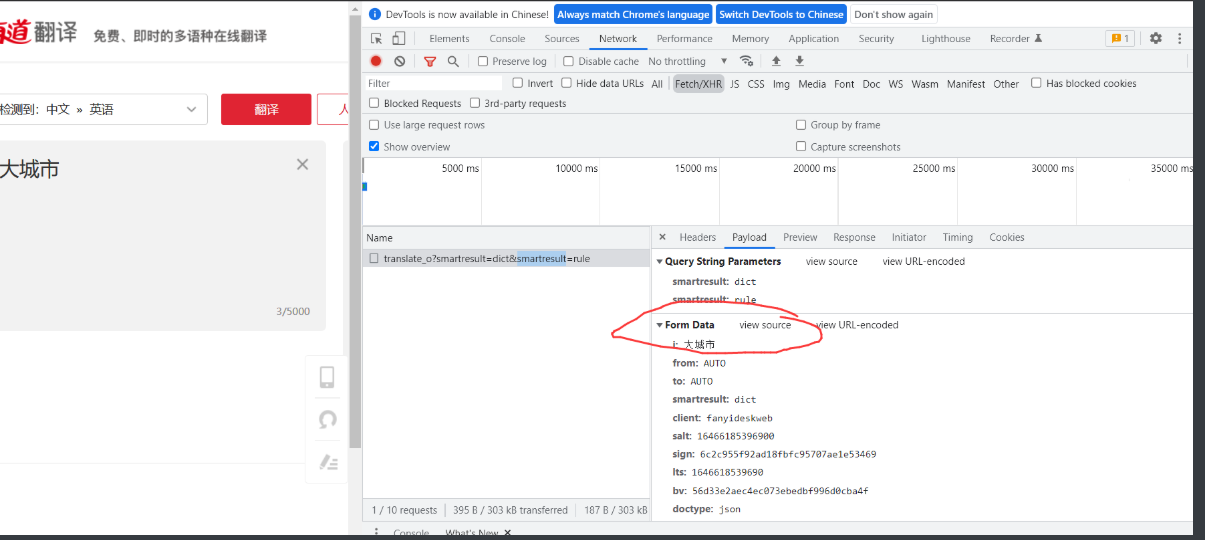
- 单击 Headers,发现请求数据的方式为 POST
- 将 Headers 中的 URL 复制出来
- Form Data 中的请求参数如图 15 所示,数据格式为多个字典
#post访问
url = "https://redisdatarecall.csdn.net/recommend/get_head_word?bid=blog-87865942" #url并不是直接的网址,而是head上的
header = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
str1shtml = requests.post(url,headers=header)
print(str1shtml.text)
#
From_data={'i':word,'from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
str1shtml = requests.post(url,headers=header,data = From_data )
4.使用 Beautiful Soup 解析数据
import requests #导入requests包
from bs4 import BeautifulSoup
url='http://www.cntour.cn/'
strhtml=requests.get(url)
soup=BeautifulSoup(strhtml.text,'lxml') #然后 Beautiful Soup 选择最合适的解析器来解析这段文档,此处指定 lxml 解析器进行解析。解析后便将复杂的 HTML 文档转换成树形结构,并且每个节点都是 Python 对象
data = soup.select('#main>div>div.mtop.firstMod.clearfix>div.centerBox>ul.newsList>li>a')#接下来用 select(选择器)定位数据,定位数据时需要使用浏览器的开发者模式,将鼠标光标停留在对应的数据位置并右击,然后在快捷菜单中选择“检查”命令,如图 18 所示:随后在浏览器右侧会弹出开发者界面,右侧高亮的代码(参见图 19(b))对应着左侧高亮的数据文本(参见图 19(a))。右击右侧高亮数据,在弹出的快捷菜单中选择“Copy”➔“Copy Selector”命令,便可以自动复制路径。
print(data)
5.清洗和组织数据
至此,获得了一段目标的 HTML 代码,但还没有把数据提取出来,接下来在 PyCharm 中输入以下代码:
for item in data:
result={
'title':item.get_text(),
'link':item.get('href') }
print(result)
6.使用正则表达式清洗
- 在 Python 中调用正则表达式时使用 re 库,这个库不用安装,可以直接调用。
爬虫攻防
1. 伪装浏览器(header)
2.增设延时,每 3 秒钟抓取一次,代码如下
import time
time.sleep(3)
3.构建代码池
- 此处用的购买的代码(https://zhimahttp.com/wirte_list/#recharge)
- 注册领取流程(https://blog.csdn.net/weixin_43074474/article/details/118407514)
def ip_list(ip_url,url):
#通过随机ip池进行反扒
rp = requests.get(ip_url)
proxy_list = rp.text.split('\r\n') #此时生成的一个ip列表
ip_list = []
flag = 1
for i in range(50):
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip,
'https': proxy_ip}
try:
response = requests.get(url=url,proxies=proxies)
if response.status_code == 200:#
print(proxy_ip)
return response
break
except:
proxy_list.remove(proxy_ip) #没用的就移除
# 并将flag值置为0
if proxy_list == []:
print("无可用ip")
break
if __name__ == '__main__':
ip_url = "http://webapi.http.zhimacangku.com/getip?num=60&type=1&pro=&city=0&yys=0&port=1&time=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions="
url = "https://poi.mapbar.com/xingtai/520/"
ip_hanshu = ip_list(ip_url,url)
print(ip_hanshu)
有用的参考内容:http://c.biancheng.net/view/2011.html
前期幼稚码——前期的数据爬取及分类整理
前期的数据爬取及分类整理
from bs4 import BeautifulSoup
import re
import urllib.request
def main():
baseurl = "https://movie.douban.com/top250?start=0&filter="
#1.爬取网页
datalist = getData(baseurl)
savepath =r".\豆瓣电影top250.xls"#./:保存至当前位置。.\:保存至文件路径
#3.保存数据
saveData(savepath)
#创建正则表达式的规则:匹配掉什么?留下的是什么??
#影片详情连接的规则
findlink = re.compile(r'<a href="(.*)">') #创建正则表达式,表示规则 (.*?):网站都是字符串表示的,来表示任意的字符串
#所设立的规则中利用正则表达式的是即为所要提取的内容
#影片图片的提取
findimage = re.compile(r'<img .* src="(.*?)"/>',re.S) #re.S让换行符包含在字符中,进行无差别的匹配
#影片的片名
findname = re.compile(r'<span .*>(.*?)</span>')
#影片的评分
findscore = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#影片的简介
summary = re.compile(r'<p class="">(.*?)</p>',re.S) #换行符很重要!!!!
#爬取网页
def getData(baseurl):
datalist = []
#对网址进行加工
for i in range(0,1): #调用获取页面信息10次
url = baseurl + str(i*25)#需要对url的样式进行观察并总结其中的规律
html = askURL(url)#保存获取到的额网页源码
#2.逐一解析数据
data = []
soup = BeautifulSoup(html,"html.parser")#解析器
for item in soup.find_all("div",class_="item"): #查找符合要求的字符串,形成列表??
item = str(item)#是有对数据的类型进行字符串装换的啊!!!
link = re.findall(findlink,item)[0] #re库用来通过正则表达式查找指定的字符串,利用规则进行匹配
data.append(link)
image = re.findall(findimage, item)
data.append(image)
#对标题进行加工
titles = re.findall(findname, item)
if (len(titles)==2):
ctitles = titles[0]
data.append(ctitles)
otitles = titles[1].replace("/",'')
data.append(otitles)
else:
data.append(titles[0])
data.append(" ")#外文名留空
vieos_summary = re.findall(summary,item)[0] #这里肯定还是字符串类型!!
vieos_summary = re.sub(r'<br/>(\s+)?'," ",vieos_summary) # 匹配空格 ,此处设立的规则是你所要调换的对象,
# 问题如果前后没有标识物,是否还可以(可以的)
vieos_summary = re.sub("/"," ",vieos_summary)
vieos_summary = re.sub(" ",'',vieos_summary)
data.append(vieos_summary)
print(data)
break
return datalist
#爬取网页内容
def askURL(url):#传一个参数
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"}
#头部信息,伪装部分成浏览器需要的必要信息
request = urllib.request.Request(url,headers=head)
html = ""
try:
response =urllib.request.urlopen(request)#发出请求返回一个对象
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:#让程序更加健壮
if hasattr(e,"code"):#分析出错类型
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#保存数据
def saveData(savepath):
pass
if __name__ == "__main__":#主函数
main()
思考及整理( 残!!!待补充!!)
# 第一步简单的网页爬取
html = "https://movie.douban.com/top250?start=0&filter="
import urllib.request
import re
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"
}
request = urllib.request.Request(html,headers = head)
respond = urllib.request.urlopen(request)#发出请求并返回一个对象
result = respond.read().decode("utf-8")
print(result)
'''
对于urllib,request爬取网页的步骤
1.研究url的规律,是单独的网页信息还是有各种连接的
2.伪装成浏览器
3.利用Request函数进行信息的爬取此时应传入所伪装的头部信息
4.利用urlopen打开
5.读取所返回的对象(注意是否含有汉语,视情况是否加utf-8)
6.最后得出的结果应该是html类型???
'''
#第二步:对信息进行加工处理
from bs4 import BeautifulSoup
soup = BeautifulSoup(result,"result.parser") #对html进行解析
soup = soup.findall("div",class_="item") #找到完整的信息块
print(str(soup))
#利用正则表达式,对信息进行分类整理
findlink = re.compile(r'')
print(soup,type(soup))
小知识点
Beautiful Soup将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是python对象,所有对象可以归纳为4种
- Tag
- NavigableString
- BeautifulSoup
- Comment

 浙公网安备 33010602011771号
浙公网安备 33010602011771号