


Python开启进程的2中方式
知识点一:进程的理论
进程:正在进行的一个程序或者说一个任务,而负责执行任务的则是CPU
进程运行的的三种状态:
1.运行:(由CPU来执行,越多越好,可提高效率)
2.阻塞:(遇到了IQ,3个里面可以通过减少阻塞有效的来提高效率)
3.就绪:(等待CPU来执行的过程)
知识点二:开启进程的两种方式
开启进程:开启进程就是将父进程里面串行执行的程序放到子进程里,实现并发执行,这个过程中,会将父进程数据拷贝一份到子进程。
运行角度:是2个进程
注意:子进程内的初始数据与父进程的一样,如果子进程被创建了被运行了,那么
子进程里面数据更改对父进程无影响,2个进程是存在运行的
方式一:通过调用multiprocessing模块下面的Process类方法
#方式一:通过调用multiprocessing模块下面的Process类方法 ''' p = Process(target=task, args=('子进程',)) : target=task:指定执行任务的目标是谁 args:后面跟元组,是给target指定函数传的参数 p=Process(..)相当于是对类Process进行实例化得到了P对象 ''' from multiprocessing import Process import time def task(x): print("%s is runnin"%x) #子进程打印输出 time.sleep(3) print('%s is done'%x) #子进程打印输出 if __name__ == '__main__': #开进程要统一放到main方法的下面 p=Process(target=task,args=('子进程',)) p.start() print('主') #父进程的打印输出 ''' 注意点: 1.p=Process(target=task,args=('子进程',)) 这一步:只是在向操作系统发我要开启一个子进程的信号(具体开子进程的操作是由操作系统来完成的) *所有这个过程中的时间也是不固定的 2.p.start(): 开启一个子进程 运行过程分析: 右键运行父类先运行起来(此时p.start()子类也已经在造了,但是会有时间延迟)-->print('主')--> 然后依次运行子进程里面内容;子进程 is runnin\子进程 is done '''
方式二:借助process类,自定义一个类(继承Process),从而造一个对象
#方式二:借助process类,自定义一个类(继承Process),从而造一个对象 from multiprocessing import Process import time class Myprocess(Process): #辅助理解, # def __init__(self,x): # super().__init__()#保留原有Process类里面的方法 # self.name=x #***如果要自定义传参,self.name=x必须要放到super()._init_()下面 # def run(self): print("%s is running" % self.name) #默认函数对象有name方法 ,结果为:Myprocess-1 time.sleep(3) print('%s is done' % self.name) if __name__ == '__main__': # p=Myprocess('子进程1',) 开启init方式就可以自定义参数传值 p=Myprocess() #实例化Myprocess类调用了类面的init方法,得到了一个对象p p1=Myprocess() p.start() #p.run() 对象去调用了类里面的run方法,进而执行run里面的函数体代码 p1.start() print('主')
以上2中方式的对比分析:
方式二:子类只能运行同一个run里面输出的方式(run名字是固定的,不能更改)
方式一:可以自定义多个task函数,并且写不同的输出内容,例如task1-->p1 task2-->p2...等等灵活性更高
父类、子类进程内存空间是彼此隔离的:
from multiprocessing import Process import time x=100 def task(): global x x=11 #当子类已经建立成功时,子类里面对数据的变动,不会印象父类 print(x) #11 print('done') if __name__ == '__main__': p=Process(target=task) p.start() time.sleep(10) # 让父进程在原地等待10,是为了等父类先建立好,用于验证子类里面的变动不会影响父类的值 print(x) #打印时父类的,即全局的 100
知识点三:僵尸进程、孤儿进程
僵尸进程:(无害的)
子进程运行结束后,会保留进程的ID号等信息,
目的是为了父进程能查看子进程的状态,以及回收僵尸状态的子进程
孤儿进程:(无害的)
在子类没有运行完的情况下,父类先行结束,这种情况下,当子进程结束时,
状态就叫做孤儿进程,当然也会被系统层面上的孤儿院回收
有一种情况是有害的:
如果父类,不停的在造子类,父类一直不死,此时PID会占用过多,导致内存也会占用很多
这种情况是有害的
知识点四:进程对象相关的属性
1.PID接口查看
#查看PID应用: # print(p.pid):外面直接查看子类pid #os.getpid():在内部查看子类pid #os.getpid():在外面查看父类的pid #os.getppid():在里面查看父类的pid import time import os from multiprocessing import Process def task(x): print('%s is running'%os.getpid()) #子进程内查看自己pid的方式 time.sleep(100) print('子类下查看父类的id:%s'%os.getppid()) #查看父类的pid time.sleep(100) print('%s is done'%x) if __name__ == '__main__': p=Process(target=task,args=('子进程1',)) p.start() print(p.pid,) #父进程内查看子类pid的方式 time.sleep(50) print('父类下查看父类自己的id:',os.getpid()) print('主')
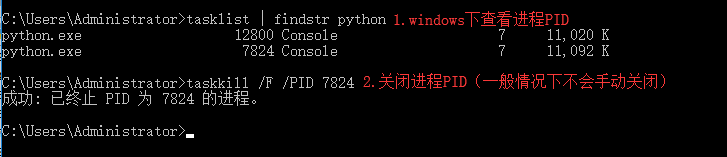
2.join()
import time from multiprocessing import Process def task(name,n): print('%s is running'%name) time.sleep(n) print('%s is done'%name) if __name__ == '__main__': p1=Process(target=task,args=("进程1",1)) #用时1s p2=Process(target=task,args=("进程2",2)) #用时1s p3=Process(target=task,args=("进程3",3)) #用时1s start_time=time.time() p1.start() # p1.join() #如果是这种情况就是总共6s左右了 p2.start() # p2.join() p3.start() # p3.join() # 让父进程在原地等待,等子进程在运行完毕后,才执行下一行代码() #注意:并不是串行,当第一秒在运行p1时,其实p2、p3也已经在运行,当1s后到p2时只需要再运行1s就到p3了,到p3也是一样。 p1.join() p2.join() p3.join() stop_time=time.time() #3.2848567962646484总结 print(stop_time-start_time) print('主')

