深入浅出一致性哈希
哈希是什么
哈希又称散列,是一种计算数据指纹的方法。
哈希函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来
业务场景
常见的业务场景;网站用户请求后,为了性能一般都会加一层缓存。
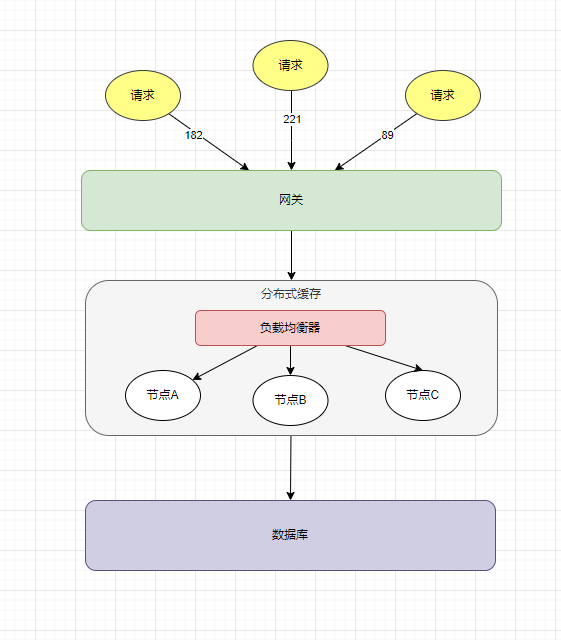
缓存有多个节点,每个节点存储了不同数据。
获取数据,先根据数据取模(哈希)找到缓存节点,如果命中缓存则直接返回结果。否则,请求DB,再缓存,再返回结果。
取模算法:
hash(data)=data mod nodeNum,比如请求数据是100,有3个节点,定位在哪个节点,使用 100%3=1 来定位到 index=1 的节点
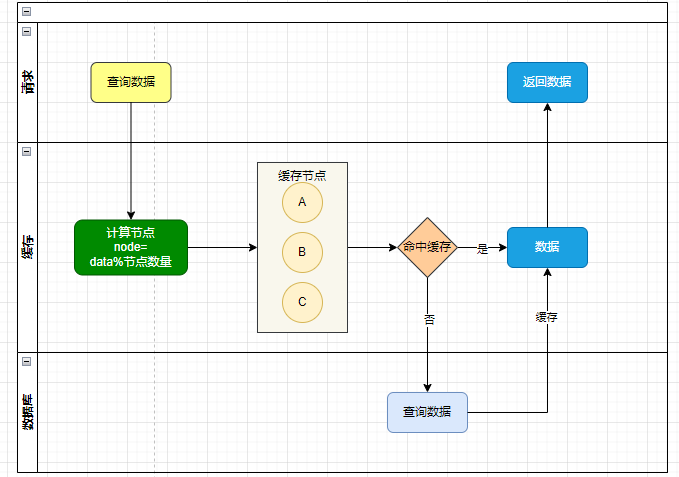
问题:比如系统负载能力不足,再加个缓存节点,但是发现基本上所有数据取余的结果会发生变化
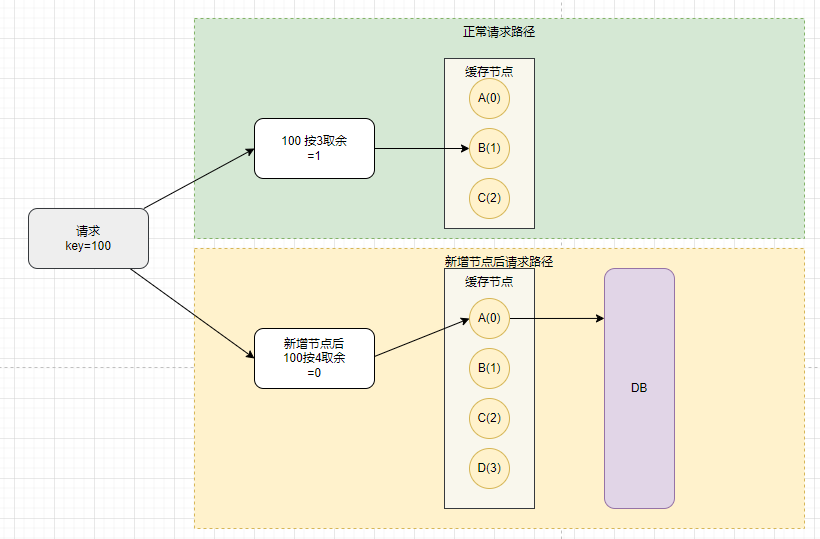
新增节点后,请求到缓存服务节点0,但是节点0没有缓存数据,又去请求DB。如果大量请求过来,大部分都去请求DB,造成DB的压力,这样也失去的增加缓存服务的意义了。
一致性哈希
一致哈希将每个对象映射到圆环边上的一个点,系统再将可用的节点机器映射到圆环的不同位置。查找某个对象对应的机器时,需要用一致哈希算法计算得到对象对应圆环边上位置,沿着圆环边上查找直到遇到某个节点机器,这台机器即为对象应该保存的位置。 当删除一台节点机器时,这台机器上保存的所有对象都要移动到下一台机器。添加一台机器到圆环边上某个点时,这个点的下一台机器需要将这个节点前对应的对象移动到新机器上。 更改对象在节点机器上的分布可以通过调整节点机器的位置来实现
比如有3个节点,将节点信息hash后,找到圆环的位置
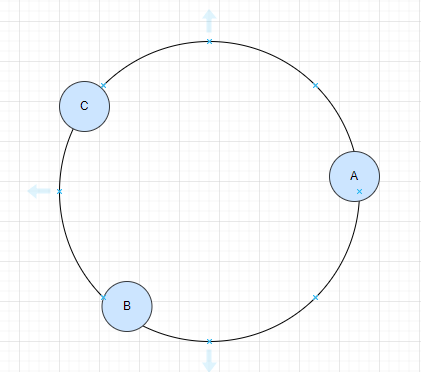
有请求数据时,对数据也做hash,找到圆环位置。那么从数据data位置开始,按顺时针寻址到的第一个节点就是要请求的节点
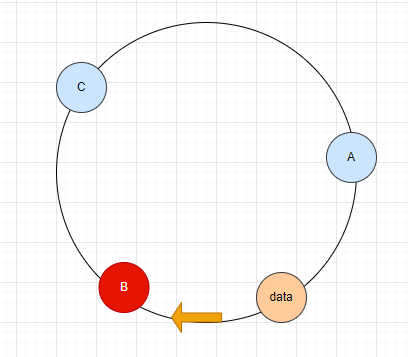
当有新节点 D 加进来后,D的位置如果在B前面,那么将B的数据迁移到D,相同的数据data计算节点是D。
这样的好处是,不用所有节点都做数据迁移,只需要迁移一个或少量数据
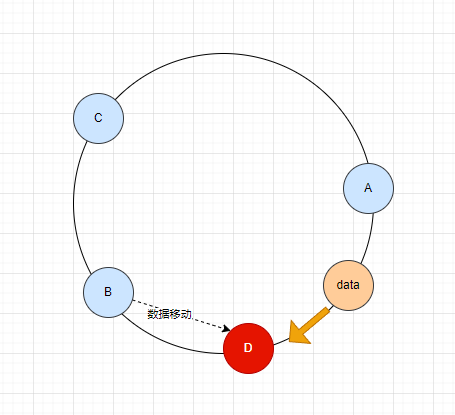
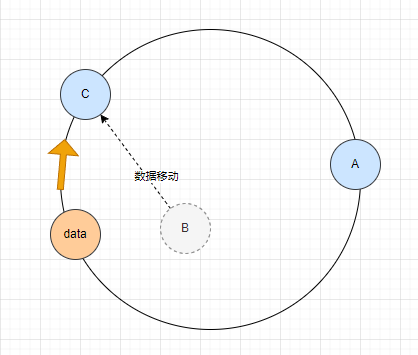
同样道理,当节点B下线时,将B的数据迁移到节点C
节点不均衡问题
一致性哈希可以解决数据大量移动的问题。但是可能存在这样的情况:大量请求的数据经过hash计算,都寻址到某一个节点,这样这个节点会面临很大压力,而其他节点很空闲资源浪费
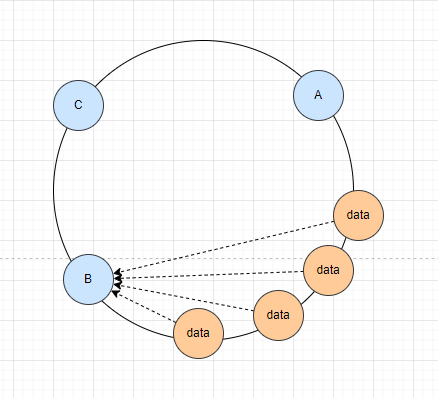
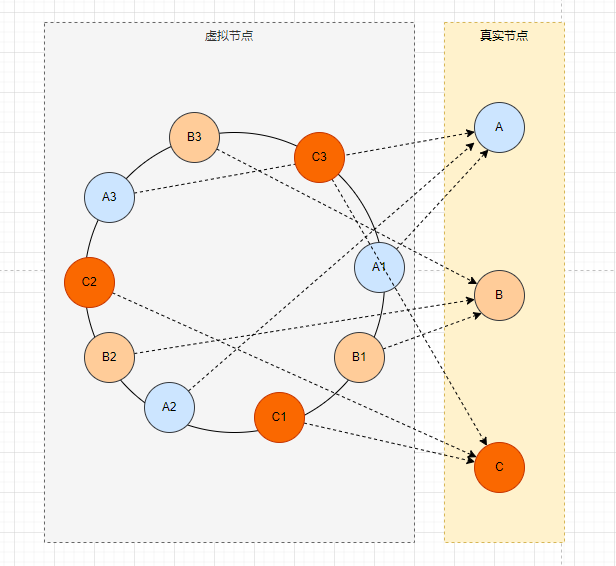
这时候,又有人想出来了虚拟节点(不得不说,人类这个脑子是真的聪明)
将每个节点都分配多个虚拟节点,分布在圆环上,这样圆环上的节点就很均匀了
nginx中也有一致性hash的使用
https://www.nginx.com/resources/wiki/modules/consistent_hash/
upstream somestream {
consistent_hash $request_uri;
server 10.50.1.3:11211;
server 10.50.1.4:11211;
server 10.50.1.5:11211;
}
// ...
server {
listen 80;
server_name localhost;
location / {
default_type text/html;
set $memcached_key $request_uri;
memcached_pass somestream;
error_page 500 404 405 = @fallback;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号