

可执行文件的生成过程
- 预处理
- 删除"#define"并展开所定义的宏
- 处理所有条件预编译指令,如"#if" ,"#ifdef","#endif"等
- 插入头文件到"#include"处,可以递归方式进行处理
- 删除所有的注释"//"和"/* */"
- 添加行号和文件名标识,义便编译时编译器产生调试用的行号信息
- 保留所有#pragma编译指令(编译器需要用)
-
汇编
-
数据:
1.真值和机器数:
2.内存对齐
CPU每次读取8字节,增加存储空间,减少数据读取时间,优化方式:改变数据排列顺序
3.数据类型转换
不同宽度整数(int long short unsiged)转换发生:截断与扩展
浮点数转换:编码格式转换(精度损失,溢出,小数丢弃)
一个运算表达式中有不同数据类型时,C语言会自动进行类型转换 -
运算
整数加减运算:补码加减运算
状态寄存器
查看:i r eflags
CF SF ZF CF:0 6 7 11
状态标志信息:
- 为后续条件转移类指令提供条件判断依据
- 为整数运算后结果是否正确提供了判断依据
正确判断:
无符号整数 CF
带符号整数 OF浮点数运算:
IEE754 -
控制
数据传送指令:
mov指令:- 一般传送:等宽数据
- movz:零扩展传送
- movs:符号扩展传送
- b,w,l:8,16,32
mov指令与lea指令的区别:
lea指令:加载有效地址 存储器-》寄存器加减运算指令:
整数乘法指令:
imul带符号乘法
mul 无符号乘法
简单乘法常用:移位 和 加法 实现控制转移指令:
jmp无条件转移指令
条件转移指令:以eflgas寄存器中的状态标志位为转移条件
call过程调用指令:
ret过程返回指令:
中断指令栈和过程调用:
p调用者 eax ecx edx
q被调用者 ebx esi edi
-
-
编译
可重定位目标文件格式:
- ELF文件头 :包含16字节标识信息,文件类型,机器类型,节头表偏移,节头表的表项大小以及表项个数
- .text节:编译后的代码部分
- .data节:已初始化的全局变量
- .bss节:未初始化的全局变量,仅是占位符,不占据任何实际的磁盘空间。区分初始化和非初始化是为了空间效率
- .rodata节:只读数据,如printf格式串,switch跳转表
- .symtab节:存放函数名 和 全局变量信息,不包含局部变量
- .rel.text节:.text节的重定位信息,用于重新修改代码段的指令中的地址信息
- .rel.data节:.data节的重定位信息,用于对被模块使用或定义的全局变量进行重定位的信息
- .debug节:调试用符号表
- strtab节:包含symtab和debug节中符号及节名
- Section header table:每个节的节名、偏移和大小
其中.text,.data,.bss,.rodata四个节将会分配存储空间
工具:
readelf -h xxx.o //读出elf头信息
readelf -S xxx.o //读出elf节头表信息
4.链接
可执行目标文件格式:
与可重定位目标文件的不同:
- ELF头中e_entry给出了执行程序时第一条指令的地址
- 多了程序头表,也称为段头表
ELF头,程序头表,.init节.text节.rodata节装入只读(代码)段,.data节,.bss节装入读写(数据)段 - 多了一个.init节,用于定义_init函数,该函数用来进行可执行目标文件开始执行时的初始化工作
- 少了两个.rel节(无需重定位)
工具:
readelf -l xxx //读出elf程序头表信息
链接步骤:
-
符号解析:确定符号引用关系
- 程序中有定义和引用的符号(变量和函数)
- 编译器将定义的符号存放在一个符号表中
- 编译器将符号的引用存放在重定位节中
- 连接器将每个符号的引用都与一个确定的符号定义建立联系
-
重定位
- 将多个代码段和数据段分别合并为一个单独的代码段和数据段
- 计算每个定义的符号在虚拟地址空间中的绝对地址/pc相对地址
- 将可执行文件中的符号引用处的地址修改为重定位后的地址信息
链接符号的类型:
- 全局符号:由本模块定义并能够被其他模块引用的符号。非static函数和非static全局变量
- 外部符号:由其他模块定义并被本模块引用的全局符号
- 局部符号:仅由本模块定义和引用的本地符号。带static的函数和变量
记录在.symtab节中,是一个结构数组
静态链接:
1.通过ar生成静态库
2.通过gcc -static -o xxx ./xxx.a
符号重定位:
readelf -r xxx.o //查看重定位表
动态链接的共享库:
静态库缺点:
1.占用大量内存和磁盘空间
2.更新困难,使用不便
解决方案:
使用shared libraries,Linux下常称为动态共享对象(dynamic shared objects, .so文件)
动态链接有两种方式:
在第一次加载时进行:
- Linux中,通常由动态连接器(ld-linux.so)自动处理,标准C库libc.so通常按照这种方式动态链接
在已经开始运行后进行: - 在Linux中通过调用dlopen()等接口来实现
在内存和磁盘中只有一个备份
在程序头表中有一个特殊的段:interp,其中记录了动态链接器目录以及文件名ld-linux.so
可执行文件的加载
- Linux创建进程过程
- shell命令行解释器接受用户输入的命令行
- 当用户输入可执行文件名和参数,并回车后,开始对命令进行解析,获得各个命令行参数并构造传递给函数execve()的参数列表,将参数个数送到argc
- 调用函数fork()。fork()函数的作用是,创建一个子进程并使新创建的子进程获得与父进程相同的虚拟空间映射和页表,也即子进程完全复制父进程的mm_struct,vm_area_struct数据结构和页表,并将父进程和子进程中每个私有页的访问权限都设置为只读,将两个进程vm_area_struct中描述的私有区域中的页面说明为私有的写时拷贝页。如果其中某一页发生写操作,则内核将使用写时拷贝机制在主存中分配一个新页框,并将页面内容拷贝到新页框中。
- 将第二步得到的参数传入,并调用execve调用,从而实现在新创建的子进程的上下文中加载并运行程序。在函数execve()中,通过启动加载器执行任务并启动程序运行。具体过程包括:
- 删除已有的VM用户空间中的区域结构vm_area_struct及其页表
- 根据可执行文件的程序头表创建新进程VM用户空间中的各个私有区域和共享区域,生成相应的vm_area_struct链表,并为每个区域页面生成相应的页表项。其中,私有区域包括只读代码,已初始化数据,未初始化数据,栈和堆。
- 新进程用户空间中有四个区域被映射到普通文件中的对象:只读代码区域,已初始化数据区域与可执行文件中的私有写时拷贝对象进行映射;共享库的数据区域和代码区域与共享库中的共享对象分别映射,未初始化数据,堆和栈都是私有的,请求0的页面,映射到匿名文件。未初始化数据区域长度由可执行文件提供,堆和栈的初始长度都是0。
- 加载实际上没有真正把可执行文件中的代码和数据从硬盘读入主存,而是根据可执行文件中的程序头表,对当前进程上下文中关于存储器映射的一些数据结构进行初始化,包括页表和各个vm_area_struct信息,加载后,将PC(EIP)设定指向Entry point(即符号_start处),最终执行main函数,以启动程序执行,只有在运行过程中,CPU检测到指令或数据不在主存,才会通过缺页中断,实际将数据或代码装入主存。
- 可执行文件的存储器映像
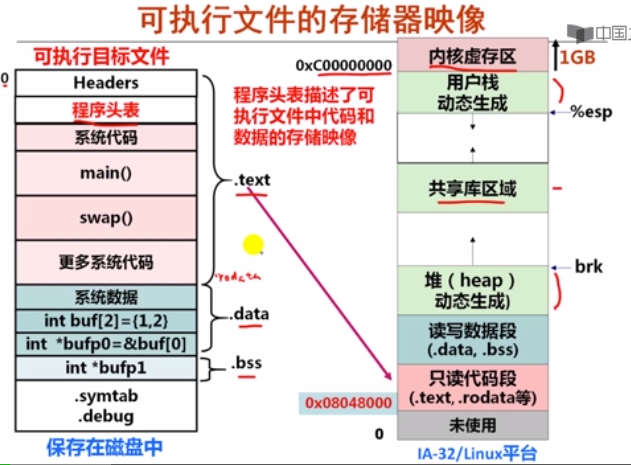
进程的执行过程
-
进程的观测
-
进程的异常行为
待补充
