


2021141 2021-2022-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2114
姓名: 杨云泰
学号:20211401
实验教师:wzq
实验日期:2022年5月23日
必修/选修: 公选课
1.实验要求
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
课代表和各小组负责人收集作业(源代码、视频、综合实践报告)
注:在华为ECS服务器(OpenOuler系统)和物理机(Windows/Linux系统)上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
批阅:注意本次实验不算做实验总分,前三个实验每个实验10分,累计30分。本次实践算入综合实践,打分为25分。
评分标准:
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
(4)如果没有使用华为云服务(ECS或者MindSpore均可),本次实践扣10分。
注意:每个人的实验不能重复,课代表先统计大家做的内容并汇总,有重复的需要自行协商。
2.实验分析及设计过程
- 主要内容:爬取91看剧网视频、解密ts片段、合并上千条ts文件成、MP4文件。(用异步协程的方式)
一、分析,编程
1、爬取下载91视频网
1.1分析91视频网源代码,做出爬取策略获得m3u8文件。
- m3u8文件作用:用来存储每一个视频片段url的文件,包含了上千个.ts文件地址。
分析网页源代码
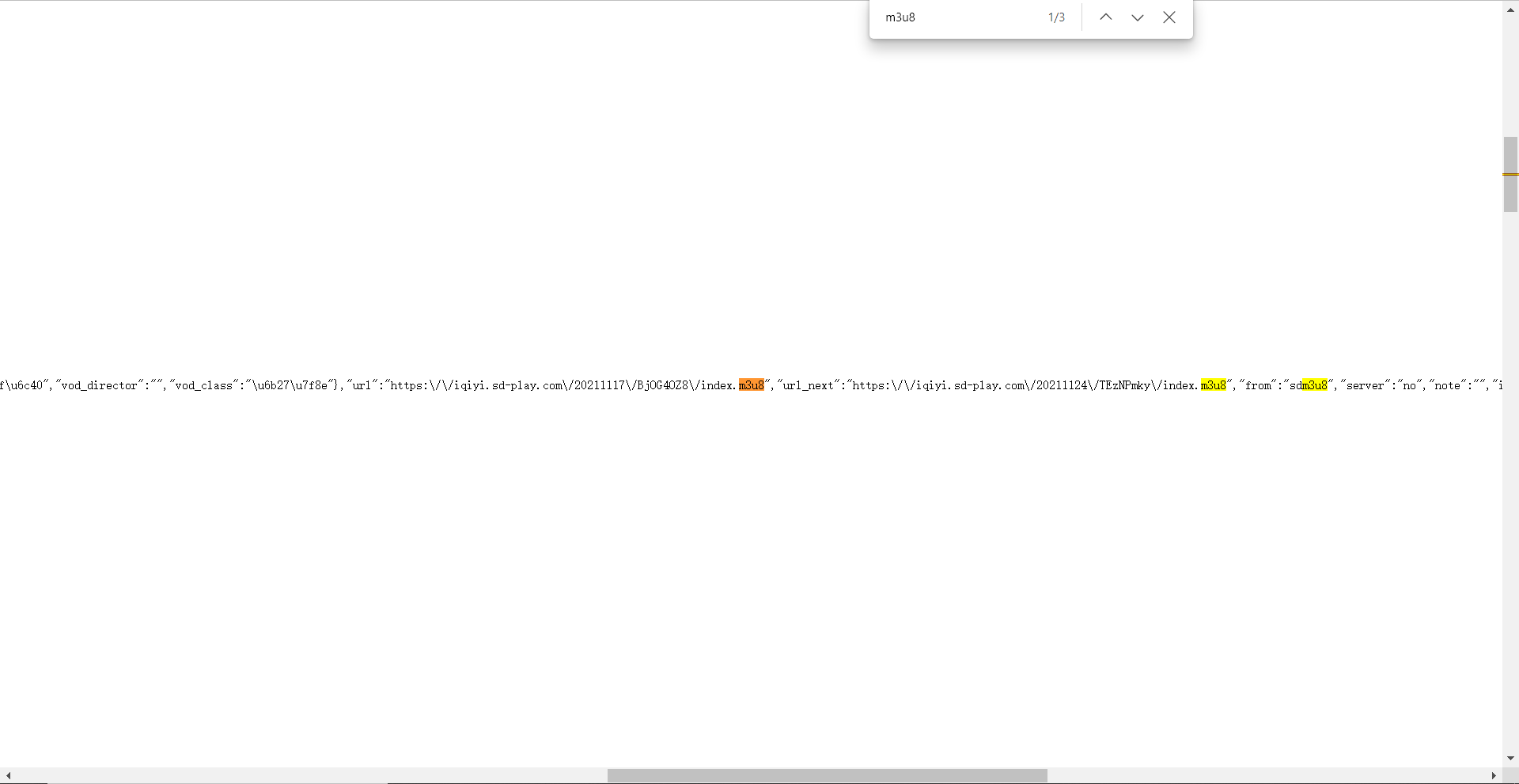
发现有两处有m3u8的url,经过验证发现url":"https://iqiyi.sd-play.com/20211117/BjOG4OZ8/index.m3u8",为本个视频的m3u8的url。
访问该url发现其指向的是另一个m3u8的部分url(如图)
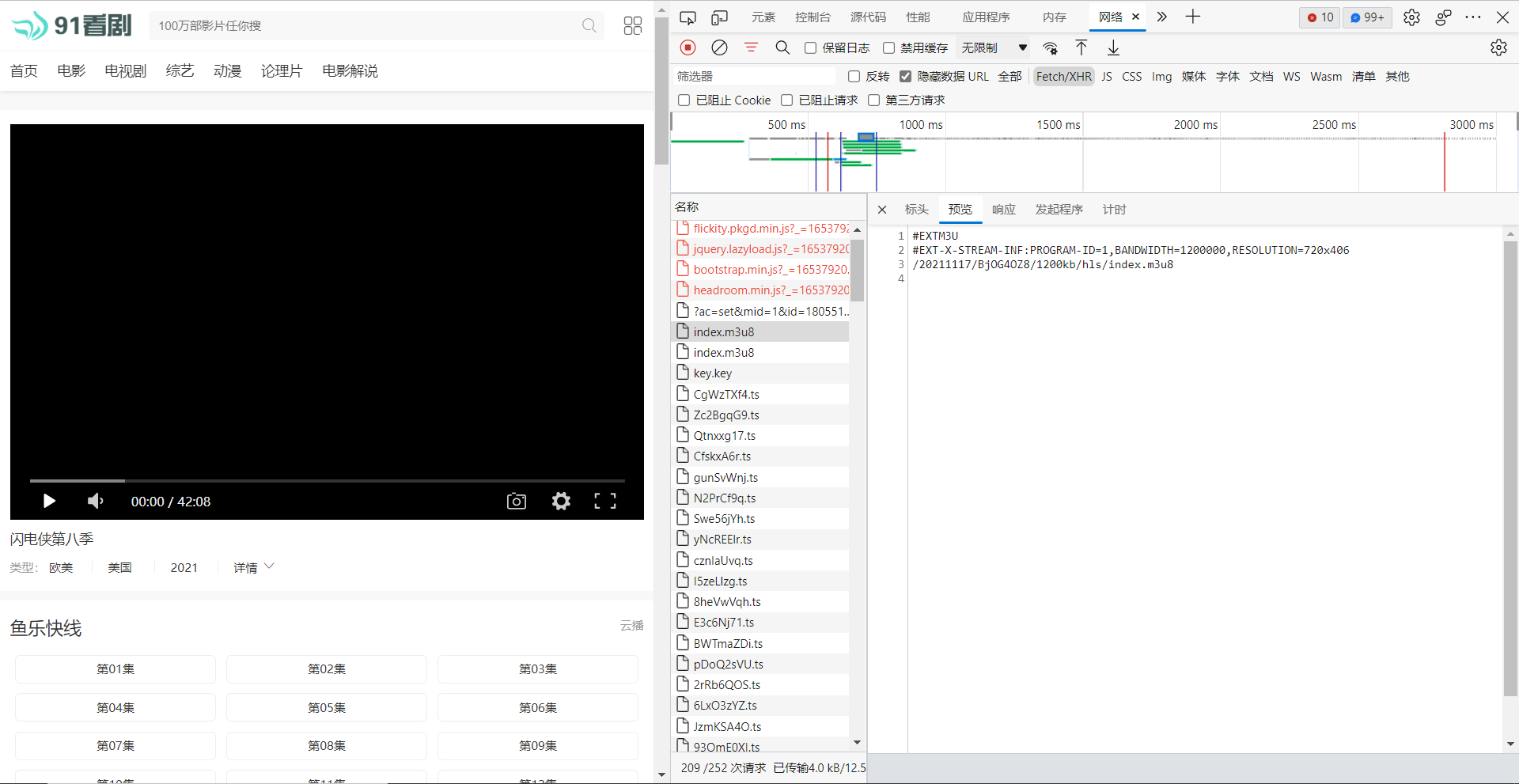
发现只要把这一部分url与第一个m3u8文件的url进行合并剪接可获得第二个么m3u8文件url。
访问该url发现找到了.ts下载路径
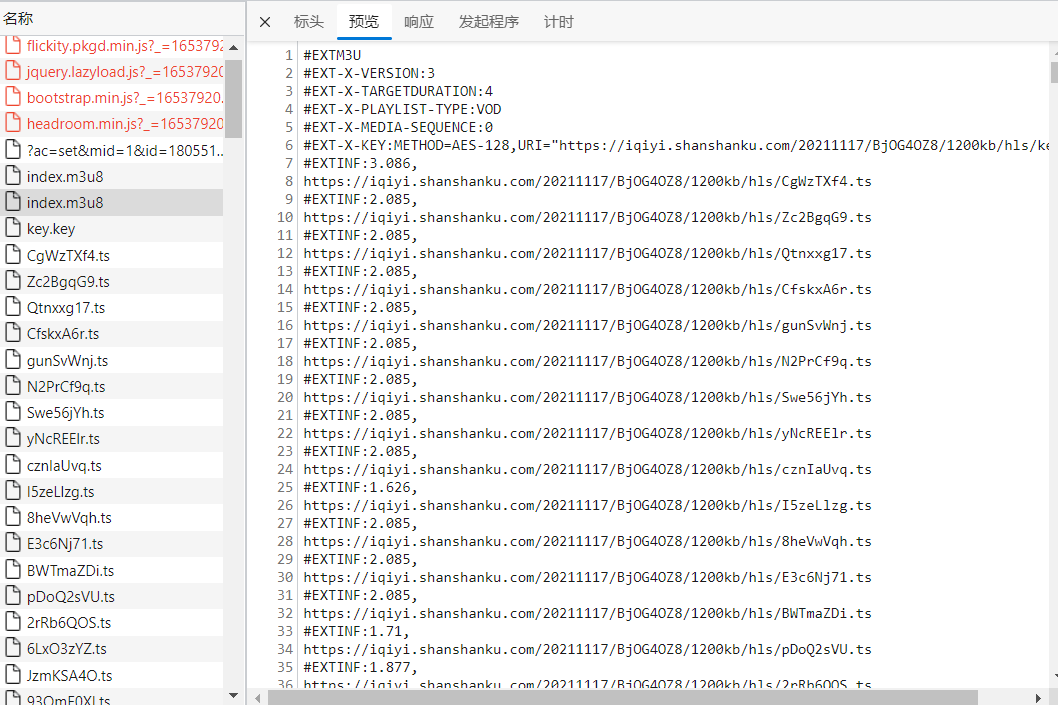
- 访问每一个url可获得一个小片段的.ts文件
如果仅使用单线程,由于需要上千次的oi操作会导致下载速度极慢,故需要用异步协程的方式加快下载速度。
又由于异步协程方式是乱序下载切所给url没有任何规律可言,故需重新命名排序,避免片段混乱无法合并。
- 流程图如下
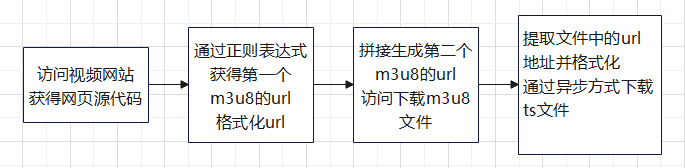
看似很简单,实则会碰到很多困难。
1.2代码实现
- 使用的库
import requests
import re
import aiohttp
import aiofiles
import asyncio
- 本次由于程序复杂,使用了函数进行包装,程序如下(点击打开):
主函数
if __name__=='__main__':
url = 'http://91kj.vip/vodplay/180551-4-1.html'
main(url)
def main(url):
m3u8_f_url=get_m3u8_url(url)
get_m3u8(m3u8_f_url)
m3u8url = dow_m3u8(m3u8_f_url)
asyncio.run(aio_download())
访问网址获得源代码,正则提取m3u8 url地址
def get_m3u8_url(url):
res = requests.get(url)
obj = re.compile(r'"},"url":"(?P<uur>.*?)","url_next":',re.S)
ul = obj.search(res.text).groups('uur')
ul=clean(ul)
return ul
下载第一个m3u8文件,保存在本地
def get_m3u8(url):
res = requests.get(url)
with open('first.m3u8',mode='wb') as f:
f.write(res.content)
拼接获取第二个m3u8 url,下载第二个文件
def dow_m3u8(url):
with open('first.m3u8',mode='r') as f:
for i in f:
if i.startswith("#"):
continue
else:
i.split()
url_hou=i.split('/',3)[3]
url_qian=url.split('index.m3u8')[0]
urlre= url_qian+url_hou
with open("second.m3u8",mode="wb") as f:
hed = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.62',
}
resp = requests.get(urlre,headers=hed)
f.write(resp.content)
return urlre
异步协程下载ts文件,并重新命名,生成名字目录list.txt
def modify_text():
with open('list.txt', "r+") as f:
f.seek(0)
f.truncate()
def write(list):
with open ("list.txt",mode="a+") as f:
f.write(list)
async def download_ts(url,name,session):
async with session.get(url) as resp:
async with aiofiles.open(f"lyb/{name}",mode='wb') as f:
await f.write(await resp.content.read())
print(f'{name}下载完毕')
async def aio_download():
"""执行异步操作 """
n = 1
tasks = []
async with aiohttp.ClientSession() as session:
async with aiofiles.open('second.m3u8',mode='r',encoding='utf-8') as f:
modify_text()
async for line in f:
line = line.strip()
if line.startswith('#'):
continue
name = f"{n}.ts"
names = name+"\n"
write(names)
n += 1
task = asyncio.create_task(download_ts(line,name,session))
tasks.append(task)
await asyncio.wait(tasks)
- 第一部分完成。
2、解密ts文件
2.1 分析
打开第二个m3u8文件可见:

ts文件被进行了加密
打开key的url可见:
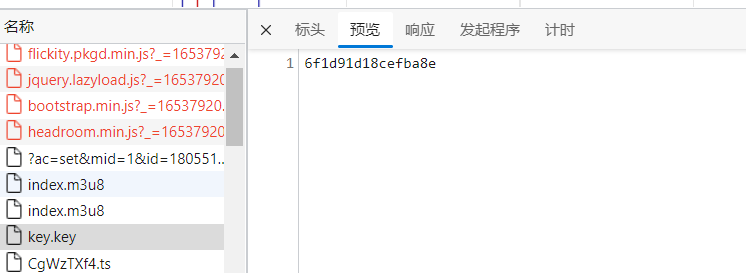
其中有密钥
- 流程图如下
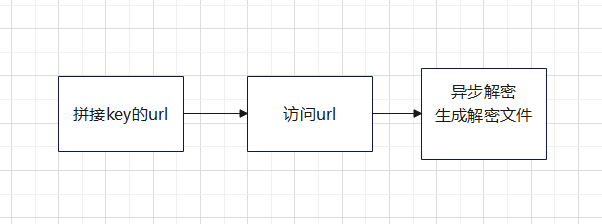
2.2代码实现
- 使用的库
import requests
import re
import aiohttp
import aiofiles
import asyncio
from Crypto.Cipher import AES
- AES用来解密
代码:
得到key的url
key_url = m3u8url.split('index.m3u8')[0]+"key.key"
(点击打开)
访问爬取key
def get_ket(url):
res = requests.get(url)
res.encoding="utf-8"
return res.text
异步解密
async def aio_dec(key):
tasks=[]
async with aiofiles.open("list.txt",mode="r") as f:
async for i in f:
i= i.strip()
task = asyncio.create_task(dec_ts(i,key))
tasks.append(task)
await asyncio.wait(tasks)
async def dec_ts(name,key):
aes = AES.new(key=key.encode('utf-8'), IV=b"0000000000000000",mode=AES.MODE_CBC)
async with aiofiles.open(f"lyb/{name}",mode="rb") as f1,\
aiofiles.open(f"temp_lyb/{name}",mode="wb") as f2:
bs = await f1.read()
await f2.write(aes.decrypt(bs))
print(f"{name}完成")
3、合并ts文件
这部分我是用的是windows的cmd命令进行合并
mac也可找到相应de命令
由于ts文件有上千个,如果一次合成会导致命令过长,运行不成功,经过测试发现在500左右的文件是刚好的。
进行分批合并后再进行合并,生成完整视频。
- 代码如下(点击打开):
代码
def make(list,name):
s = '+'.join(list)
os.system(f"cd temp_lyb & copy /b {s} {name}.mp4")
print(f"over{name}")
def merge_ts():
lst = []
lst2 = []
n=1
with open("list.txt",mode="r",encoding="utf-8") as f:
for i in f:
i = i.strip()
lst.append(f'{i}')
if len(lst)==650:
make(lst,n)
n+=1
lst = []
make(lst,n)
for j in range(n):
j+=1
lst2.append(f'{j}.mp4')
make(lst2,'over')
代码运行
调试华为云
- 1.创建新的华为云
- 2.在华为云上下载python3.9版本
- 3.安装对应的库
- 4.运行结果

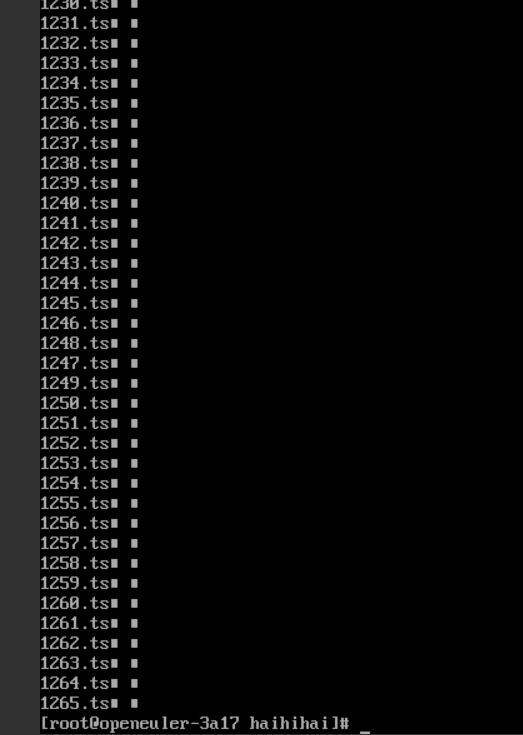
在华为云上的文件:
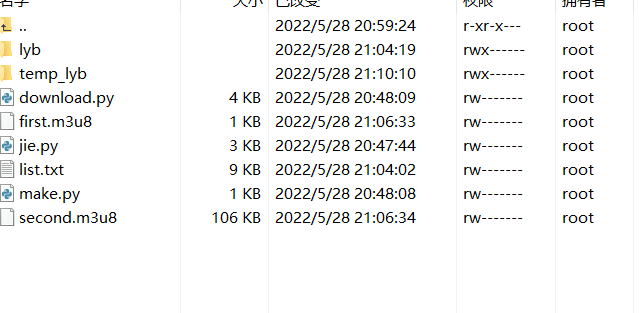
未解密的:
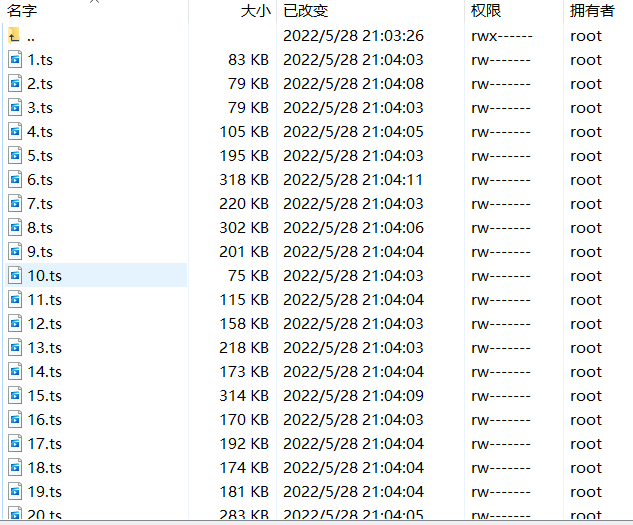
加密后的:
3.实验过程中的问题:
1.第二个m3u8文件中的url没有顺序,爬到的无法排序。
重新名命排序,生成命名后的文件进行传递。
2.在合并第二个m3u8文件时无法用re截取到对应的url
改变方法,用split()
3.在下载ts文件时,异步模块报错但能下载到所有ts文件
发现在Linux上面运行正常不报错,研究了两天,还不知道咋错了,但可以爬到内容,可能是库的问题,就这样了。
4.发现华为云上python是2.7版本,无法使用
网上找升级的教程,重新安装python3.9
5.在爬取别的一些视频时发现第二个m3u8文件的url正确但无法爬取
经过反复测试,不同源的视频有些无法爬到,闪电在线的源可完全正常使用。
6.合并视频的代码过长,无法运行。
进行分段合并让后再合并一次得到完整视频。
4.课程体会
在本学期的课上,老师教了python的基础语法:
- 变量赋值
- 运算符及其优先级
- 基本数据类型
- 循环语句
- 列表、元组、字典、集合
- 字符串与正则表达式
- 函数
- 面向对象程序设计
- 文件操作及异常处理
也学了一些对于python的应用: - Python操作数据库
- Python爬虫
- Socket套接字(TCP/UDP)进行通信
对于python的学习,我从上学期已经开始了,在假期也一直再学习python,也看了一些关于python的书,也按照书上的内容,自己制作了一个pygame的小游戏,在这过程中使我受益匪浅。也在开学之后的蓝桥杯python比赛中,获得了名次。
而这个课程对于我来说,课上的内容我已经都学完了,但这个课让我更一次巩固了我的python知识,这门课老师从由浅入深,逐步讲解,相较自学而言更加有系统和条理,能让新手知道从何入手,怎样学习。对于我而言,这门课使我更加深入的学习了爬虫的一些相关知识,学了re正则表达,bs4查找以及lxml的应用,并且初步尝试了异步操作,使我受益良多。
对于课堂的建议:
1.我觉得可以在增加课上测试,在讲完之后直接用云班课考察,及时知道自己的不足。
2.增加课下实践的此数,比如增加一些编程小作业,来增加编程的熟练度。
3.建议老师给一些学习路径,比如要学爬虫或机器学习等时,要从何学起,推荐一些基础的书籍来给新手入门,增加一些学习路径。
- 人生苦短,我用python
- 人生苦短,我用python
- 人生苦短,我用python

