深入理解k8s调度器与调度框架核心源码
k8s调度器kube-scheduler的核心实现在pkg/scheduler下
algorithmprovider:调度算法的注册与获取功能,核心数据结构是一个字典类的结构
apis:k8s集群中的资源版本相关的接口,和apiversion、type相关的一些内容
core:调度器实例的核心数据结构与接口以及外部扩展机制的实现
framework:定义了一套调度器内部扩展机制
internal:调度器核心实例依赖的内部数据结构
metrics:指标度量
profile:基于framework的一套调度器的配置,用于管控整个调度器的运行框架
testing:一些测试代码
util:一些通用的工具
在pkg/scheduler/scheduler.go,定义了Scheduler:
type Scheduler struct {
SchedulerCache internalcache.Cache
Algorithm core.ScheduleAlgorithm
NextPod func() *framework.QueuedPodInfo
Error func(*framework.QueuedPodInfo, error) //默认的调度失败处理方法
StopEverything <-chan struct{}
SchedulingQueue internalqueue.SchedulingQueue //Pod的调度队列
Profiles profile.Map //调度器配置
client clientset.Interface
}
pkg/scheduler/internal/queue/scheduling_queue.go中定义了调度队列的接口SchedulingQueue:
type SchedulingQueue interface {
framework.PodNominator
Add(pod *v1.Pod) error
AddUnschedulableIfNotPresent(pod *framework.QueuedPodInfo, podSchedulingCycle int64) error
SchedulingCycle() int64
Pop() (*framework.QueuedPodInfo, error)
Update(oldPod, newPod *v1.Pod) error
Delete(pod *v1.Pod) error
MoveAllToActiveOrBackoffQueue(event string)
AssignedPodAdded(pod *v1.Pod)
AssignedPodUpdated(pod *v1.Pod)
PendingPods() []*v1.Pod
Close()
NumUnschedulablePods() int //不可调度的Pod数量
Run()
}
AssignedPodAdded、AssignedPodUpdated、MoveAllToActiveOrBackoffQueue底层都会调用 movePodsToActiveOrBackoffQueue方法,主要用来设置资源(Pod、Node等)更新时的回调方法。即资源更新时,之前无法被调度的Pod,会有重试的机会。
PriorityQueue是接口的具体实现:
type PriorityQueue struct {
framework.PodNominator //调度的结果(Pod和Node的对应关系)
stop chan struct{} //外部控制队列的channel
clock util.Clock
podInitialBackoffDuration time.Duration //backoff pod 初始的等待重新调度时间
podMaxBackoffDuration time.Duration //backoff pod 最大的等待重新调度时间
lock sync.RWMutex
cond sync.Cond //并发场景下实现控制pop的阻塞
activeQ *heap.Heap
podBackoffQ *heap.Heap
unschedulableQ *UnschedulablePodsMap
schedulingCycle int64 //计数器,每pop一共pod,增加一次
moveRequestCycle int64
closed bool
}
其核心数据结构主要包含三个队列,高优先度的Pod排在前面。
(1)activeQ:存储所有等待调度的Pod的队列
默认是基于堆来实现,其中元素的优先级则通过对比Pod的创建时间和Pod的优先级来进行排序。
kube-scheduler发现某个Pod的nodeName是空后,就认为这个Pod处于未调度状态,将其放到调度队列里:
(2)podBackoffQ:存储运行失败的Pod的队列
func (p *PriorityQueue) podsCompareBackoffCompleted(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
bo1 := p.getBackoffTime(pInfo1)
bo2 := p.getBackoffTime(pInfo2)
return bo1.Before(bo2)
}
// getBackoffTime returns the time that podInfo completes backoff
func (p *PriorityQueue) getBackoffTime(podInfo *framework.QueuedPodInfo) time.Time {
duration := p.calculateBackoffDuration(podInfo)
backoffTime := podInfo.Timestamp.Add(duration)
return backoffTime
}
// 计算backoff时间
func (p *PriorityQueue) calculateBackoffDuration(podInfo *framework.QueuedPodInfo) time.Duration {
duration := p.podInitialBackoffDuration
for i := 1; i < podInfo.Attempts; i++ {
duration = duration * 2
if duration > p.podMaxBackoffDuration {
return p.podMaxBackoffDuration
}
}
return duration
}
(3)unschedulableQ:其实是一个Map结构,存储暂时无法调度的Pod
type UnschedulablePodsMap struct {
podInfoMap map[string]*framework.QueuedPodInfo
keyFunc func(*v1.Pod) string
metricRecorder metrics.MetricRecorder //有Pod从Map中新增、删除时就会增加1
}
// 构造函数
func newUnschedulablePodsMap(metricRecorder metrics.MetricRecorder) *UnschedulablePodsMap {
return &UnschedulablePodsMap{
podInfoMap: make(map[string]*framework.QueuedPodInfo),
keyFunc: util.GetPodFullName,
metricRecorder: metricRecorder,
}
}
新建Scheduler的方法:
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
stopEverything := stopCh
if stopEverything == nil {
stopEverything = wait.NeverStop
}
options := defaultSchedulerOptions //获取默认的调度器选项,里面会给定默认的algorithmSourceProvider
for _, opt := range opts {
opt(&options)
}
schedulerCache := internalcache.New(30*time.Second, stopEverything) //初始化调度缓存
registry := frameworkplugins.NewInTreeRegistry() //registry是一个字典,里面存放了插件名与插件的工厂方法
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
snapshot := internalcache.NewEmptySnapshot()
configurator := &Configurator{ //基于配置创建configurator实例
client: client,
recorderFactory: recorderFactory,
informerFactory: informerFactory,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
percentageOfNodesToScore: options.percentageOfNodesToScore,
podInitialBackoffSeconds: options.podInitialBackoffSeconds,
podMaxBackoffSeconds: options.podMaxBackoffSeconds,
profiles: append([]schedulerapi.KubeSchedulerProfile(nil), options.profiles...),
registry: registry,
nodeInfoSnapshot: snapshot,
extenders: options.extenders,
frameworkCapturer: options.frameworkCapturer,
}
metrics.Register()
var sched *Scheduler
source := options.schedulerAlgorithmSource
switch {
case source.Provider != nil:
// Create the config from a named algorithm provider.
sc, err := configurator.createFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
sched = sc
case source.Policy != nil:
// Create the config from a user specified policy source.
policy := &schedulerapi.Policy{}
switch {
case source.Policy.File != nil:
if err := initPolicyFromFile(source.Policy.File.Path, policy); err != nil {
return nil, err
}
case source.Policy.ConfigMap != nil:
if err := initPolicyFromConfigMap(client, source.Policy.ConfigMap, policy); err != nil {
return nil, err
}
}
// Set extenders on the configurator now that we've decoded the policy
// In this case, c.extenders should be nil since we're using a policy (and therefore not componentconfig,
// which would have set extenders in the above instantiation of Configurator from CC options)
configurator.extenders = policy.Extenders
sc, err := configurator.createFromConfig(*policy)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler from policy: %v", err)
}
sched = sc
default:
return nil, fmt.Errorf("unsupported algorithm source: %v", source)
}
// Additional tweaks to the config produced by the configurator.
sched.StopEverything = stopEverything
sched.client = client
addAllEventHandlers(sched, informerFactory)
return sched, nil
}
addAllEventHandlers方法会启动所有资源对象的事件监听,例如,新生成的Pod,spec.nodeName为空且状态是pending。kube-Scheduler会watch到这个Pod的生成事件。
kube-scheduler的调度流程为:
(1)Cobra命令行参数解析
通过options.NewOptions函数初始化各个模块的默认配置,例如HTTP或HTTPS服务等。
通过options.Validate函数验证配置参数的合法性和可用性
kube-scheduler启动时通过--config <filename>指定配置文件
对默认配置启动的调度器,可以用 --write-config-to把默认配置写到一个指定文件里面。
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
percentageOfNodesToScore: 0
schedulerName: default-scheduler
bindTimeoutSeconds: 600
clientConnection:
acceptContentTypes: ""
burst: 100
contentType: application/vnd.kubernetes.protobuf
kubeconfig: ""
qps: 50
disablePreemption: false
enableContentionProfiling: false
enableProfiling: false
hardPodAffinitySymmetricWeight: 1
healthzBindAddress: 0.0.0.0:10251
leaderElection:
leaderElect: true
leaseDuration: 15s
lockObjectName: kube-scheduler
lockObjectNamespace: kube-system
renewDeadline: 10s
resourceLock: endpoints
retryPeriod: 2s
metricsBindAddress: 0.0.0.0:10251
profiles:
- schedulerName: default-scheduler
- schedulerName: no-scoring-scheduler
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
algorithmSource:算法提供者,即调度器配置(过滤器、打分器等一些配置文件的格式),目前提供三种方式:
Provider(DefaultProvider优先打散、ClusterAutoscalerProvider优先堆叠)、file、configMap
percentageOfNodesToscore:控制Node的取样规模;
SchedulerName:调度器名称,默认名称是default-scheduler;
bindTimeoutSeconds:Bind阶段的超时时间
ClientConnection:配置跟kube-apiserver交互的一些参数配置。比如contentType是用来跟kube-apiserver交互的序列化协议,这里指定为protobuf;
disablePreemption:关闭抢占协议;
hardPodAffinitySymnetricweight:配置PodAffinity和NodeAffinity的权重是多少。
profiles:可以定义多个。Pod通过spec.schedulerName指定使用的调度器(默认调度器是default-scheduler)
将cc对象(kube-scheduler组件的运行配置)传入cmd/kube-scheduler/app/server.go中的Run函数,Run函数定义了kube-scheduler组件启动的逻辑,它是一个运行不退出的常驻进程
(1)Configz registration
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(cc.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
(2)运行EventBroadcaster事件管理器。
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
(3)运行HTTP服务
/healthz:用于健康检查
var checks []healthz.HealthChecker // 设置健康检查
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
if cc.InsecureServing != nil {
separateMetrics := cc.InsecureMetricsServing != nil
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, separateMetrics, checks...), nil, nil)
if err := cc.InsecureServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start healthz server: %v", err)
}
}
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
/metrics:用于监控指标,一般用于Prometheus指标采集
if cc.InsecureMetricsServing != nil {
handler := buildHandlerChain(newMetricsHandler(&cc.ComponentConfig), nil, nil)
if err := cc.InsecureMetricsServing.Serve(handler, 0, ctx.Done()); err != nil {
return fmt.Errorf("failed to start metrics server: %v", err)
}
}
(4)运行HTTPS服务
if cc.SecureServing != nil {
handler := buildHandlerChain(newHealthzHandler(&cc.ComponentConfig, false, checks...), cc.Authentication.Authenticator, cc.Authorization.Authorizer)
// TODO: handle stoppedCh returned by c.SecureServing.Serve
if _, err := cc.SecureServing.Serve(handler, 0, ctx.Done()); err != nil {
// fail early for secure handlers, removing the old error loop from above
return fmt.Errorf("failed to start secure server: %v", err)
}
}
(5)实例化所有的Informer,运行所有已经实例化的Informer对象
包括Pod、Node、PV、PVC、SC、CSINode、PDB、RC、RS、Service、STS、Deployment
cc.InformerFactory.Start(ctx.Done()) cc.InformerFactory.WaitForCacheSync(ctx.Done()) // 等待所有运行中的Informer的数据同步到本地
(6)参与选主:
if cc.LeaderElection != nil { //需要参与选主
cc.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
close(waitingForLeader)
sched.Run(ctx)
},
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
}
leaderElector, err := leaderelection.NewLeaderElector(*cc.LeaderElection) //实例化LeaderElector对象
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx) //调用client-go中tools/leaderelection/leaderelection.go中的Run()参与领导选举
return fmt.Errorf("lost lease")
}
LeaderCallbacks中定义了两个回调函数:
OnStartedLeading函数是当前节点领导者选举成功后回调的函数,定义了kube-scheduler组件的主逻辑;
OnStoppedLeading函数是当前节点领导者被抢占后回调的函数,会退出当前的kube-scheduler协程。
(7)运行sched.Run调度器。
sched.Run(ctx)
其运行逻辑为:
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}
首先调用了pkg/scheduler/internal/queue/scheduling_queue.go中PriorityQueue的Run方法:
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulableQLeftover, 30*time.Second, p.stop)
其逻辑为:
每隔1秒,检测backoffQ里是否有pod可以被放进activeQ里
每隔30秒,检测unschedulepodQ里是否有pod可以被放进activeQ里(默认条件是等待时间超过60 秒)
然后调用了sched.scheduleOne,它是kube-scheduler组件的调度主逻辑,通过wait.Until定时器执行,内部会定时调用sched.scheduleOne函数,当sched.config.StopEverythingChan关闭时,该定时器才会停止并退出。

kube-scheduler首先从activeQ里pop一个等待调度的Pod出来,并从NodeCache里拿到相关的Node数据
NodeCache横轴为zoneIndex(即Node按照zone进行分堆,从而保证拿到的Node按zone打散),纵轴为nodeIndex。
在filter阶段,每pop一个node进行过滤,zoneIndex往后自增一个位置,然后从该zone的node列表中取一个Node出来(如果当前zone的无Node,就会从下一个zone拿),取出后nodeIndex也要往后自增一个位置。
根据取样比例判断Filter到的Node是否足够。如果取样的规模已经达到了设置的取样比例,Filter就会结束。
取样比例通过percentageOfNodesToScore(0~100)设置
当集群中的可调度节点少于50个时,调度器仍然会去检查所有的Node
若不设置取样比例,默认的比例会随着节点数量的增多不断降低(最低到5%)
Scheduling Framework是一种可插入的架构,在原有的调度流程中定义了丰富的扩展点(extention point)接口
开发者可以通过实现扩展点所定义的接口来实现插件,从而将自身的调度逻辑集成到Scheduling Framework中。
pkg/scheduler/framework/plugins/names/names.go中记载了所有自带插件的插件名
需要启用的在pkg/scheduler/algorithmprovider/registry.go中进行注册
Scheduling Framework在执行调度流程运行到相应的扩展点时,会调用用户注册的插件,影响调度决策的结果。
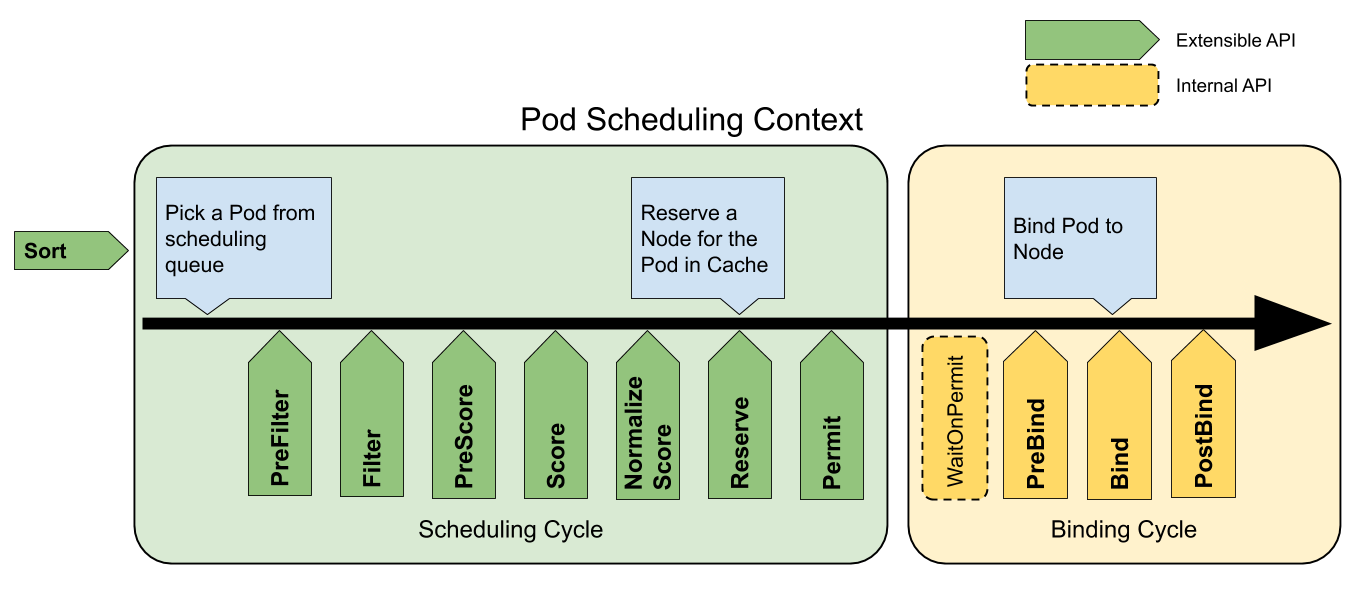
核心调度流程在pkg/scheduler/core/generic_scheduler.go:
func (g *genericScheduler) Schedule(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
trace := utiltrace.New("Scheduling", utiltrace.Field{Key: "namespace", Value: pod.Namespace}, utiltrace.Field{Key: "name", Value: pod.Name})
defer trace.LogIfLong(100 * time.Millisecond)
if err := g.snapshot(); err != nil {
return result, err
}
trace.Step("Snapshotting scheduler cache and node infos done")
if g.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
feasibleNodes, filteredNodesStatuses, err := g.findNodesThatFitPod(ctx, fwk, state, pod)
if err != nil {
return result, err
}
trace.Step("Computing predicates done")
if len(feasibleNodes) == 0 {
return result, &FitError{
Pod: pod,
NumAllNodes: g.nodeInfoSnapshot.NumNodes(),
FilteredNodesStatuses: filteredNodesStatuses,
}
}
// When only one node after predicate, just use it.
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(filteredNodesStatuses),
FeasibleNodes: 1,
}, nil
}
priorityList, err := g.prioritizeNodes(ctx, fwk, state, pod, feasibleNodes)
if err != nil {
return result, err
}
host, err := g.selectHost(priorityList)
trace.Step("Prioritizing done")
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(filteredNodesStatuses),
FeasibleNodes: len(feasibleNodes),
}, err
}
下面为Scheduling Framework全流程,灰色插件默认不启用:
1、scheduling cycle
scheduling cycle是调度的核心流程,主要进行调度决策,挑选出唯一的节点。
scheduling cycle是同步执行的,同一个时间只有一个scheduling cycle,是线程安全的
扩展点1:Sort
用于排序调度队列中的Pod,接口只定义了一个函数Less,用于堆排序待调度Pod时进行比较
type QueueSortPlugin interface {
Plugin
Less(*PodInfo, *PodInfo) bool
}
比较函数在同一时刻只有一个,所以Sort插件只能Enable一个,如果用户Enable了2个则调度器启动时会报错退出
-
PrioritySort:首先比较优先级,然后再比较timestamp:
type PrioritySort struct{}
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := corev1helpers.PodPriority(pInfo1.Pod)
p2 := corev1helpers.PodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}
func PodPriority(pod *v1.Pod) int32 {
if pod.Spec.Priority != nil {
return *pod.Spec.Priority
}
return 0
}
预选阶段先并发运行PreFilter,只有当所有的PreFilter插件都返回success 时,才能进入Filter阶段,否则Pod将会被拒绝掉,标识此次调度流程失败;再并发运行Filter的所有插件,每个Node只要被任一Filter插件认为不满足调度要求就会被滤除。
为了提升效率,执行顺序可以被配置,这样用户就可以将过滤掉大量节点的策略(例如NodeSelector的Filter)放到前边执行,从而减少后边Filter策略执行的次数
扩展点2:PreFilter
PreFilter是调度流程启动之前的预处理,可以进行Pod信息的加工、集群或Pod必须满足的预置条件的检查等。
-
NodeResourcesFit
-
NodePorts
-
PodTopologySpread
-
InterPodAffinity
-
VolumeBinding:检查Pod挂载的PVC,如果其对应SC的VolumeBindingMode是Immediate模式,该PVC必须已经是bound,否则需要返回UnschedulableAndUnresolvable
-
NodeAffinity
-
ServiceAffinity
扩展点3:Filter
-
NodeUnschedulable:Node是否不允许调度
-
NodeResourcesFit:检查节点是否有Pod运行所需的资源
-
Nodename:Node是否符合Pod在spec.nodeSelector中的要求
-
NodePorts:若Pod定义了Ports.hostPort属性,则检查其值指定的端口是否已经被节点上其他容器或服务占用
-
NodeAffinity:Pod和Node的亲和和反亲和调度
-
VolumeRestrictions:检查挂载该Node上的卷是否满足存储提供者的要求
-
TainttToleration:检查Pod Tolerates和Node Taints是否匹配
-
NodeVolumeLimits、 EBSLimits、 GCEPDLimits、 AzureDiskLimits、 CinderVolume:校验PVC指定的Provision在CSI plugin或非CSI Plugin(后三个)上报的单机最大挂盘数(存储插件提供方一般对每个节点的单机最大挂载磁盘数是有限制的)
-
VolumeBinding:检查Pod挂载的PVC,如果其是bound状态,检查节点是否满足PV的拓扑要求;如果还没有bound,检查节点是否能有满足拓扑、存储空间要求的PV
-
VolumeZone:检查检查PV的Label,如果定义了zone的信息,则必须和Node的zone匹配
-
PodTopologySpread:检查Pod的拓扑逻辑
-
InterPodaffinity:检查Pod间的亲和、反亲和逻辑
-
NodeLabel
-
ServiceAffinity
扩展点4:PostFilter
主要用于处理Pod在Filter阶段失败后的操作,如抢占、Autoscale触发等。
-
DefaultPreemption:当高优先级的Pod没有找到合适的Node时,会执行Preempt抢占算法,抢占的流程:
①一个Pod进入抢占的时候,首先会判断Pod是否拥有抢占的资格,有可能上次已经抢占过一次。
②如果符合抢占资格,会先对所有的节点进行一次过滤,过滤出符合这次抢占要求的节点。然后
③模拟一次调度,把优先级低的Pod先移除出去,再尝试能否把待抢占的Pod放置到此节点上。然后通过这个过程从过滤剩下的节点中选出一批节点进行抢占。
④ProcessPreemptionWithExtenders是一个扩展的钩子,用户可以在这里加一些自己抢占节点的策略。如果没有扩展的钩子,这里面不做任何动作。
⑤PickOneNodeForPreemption,从上面选出的节点里挑选出最合适的一个节点,策略包括:
优先选择打破PDB最少的节点;
其次选择待抢占Pods中最大优先级最小的节点;
再次选择待抢占Pods优先级加和最小的节点;
接下来选择待抢占Pods数目最小的节点;
最后选择拥有最晚启动Pod的节点;
通过过滤之后,会选出一个最合适的节点。对这个节点上待抢占的Pod进行delete,完成抢占过程。
扩展点5:PreScore
获取到通过Filter阶段的节点列表后,进行一些信息预处理、生成日志或者监控信息。
-
SelectorSpread
-
InterPodaffinity
-
PodTopologySpread
-
TaintToleration
扩展点6:Score
对Filter过滤后的剩余节点进行打分。
-
SelectorSpread
-
NodeResourcesBalancedAllocation:碎片率(CPU 的使用比例和内存使用比例的差值)={ 1 - Abs[CPU(Request / Allocatable) - Mem(Request / Allocatable)] } * Score。如果这个差值越大,就表示碎片越大,优先不分配到这个节点上。
-
NodeResourcesLeastAllocated:优先打散,公式是 (Allocatable - Request) / Allocatable * Score
-
ImageLocality:如果节点里面存在镜像的话,优先把Pod调度到这个节点上。这里还会去考虑镜像的大小,会按照节点上已经存在的镜像大小优先级亲和
-
InterPodaffinity
-
NodeAffinity
-
NodePreferAvoidpods
-
PodTopologySpread:权重为2(因为是用户指定的)
-
TaintToleration
-
NodeResourcesMostAllocated:优先堆叠,公式是Request / Allocatable * Score
-
RequestedToCapacityRatio:指定比率。用户指定配置参数可以指定不同资源使用比率的分数,从而达到控制集群上每个节点上pod的分布。
-
nodeLabel
-
ServiceAffinity:替换了曾经的SelectorSpreadPriority(因为Service代表一组服务,只要能做到服务的打散分配就足够了)。
扩展点7:NormalizeScore
标准化完成后,Scheduler会综合PreScore+Score所有插件的打分。
扩展点8:Reserve
分配Pod到Node的时候,需要进行账本预占(Reserve),将调度结果放到调度缓存(Schedule Cache)。预占的过程会把Pod的状态标记为Assumed(处于内存态)、在Node的状态中添加该Pod的数据账本。
-
volumebinding:调用AssumePodVolumes方法,更改调度缓存中已经Match的PV的annotation[pv.kubernetes.io/bound-by-controller]="yes"和未匹配到PV的PVC的 annotation[volume.kubernetes.io/selected-node]=所选节点。最后更改调度缓存中Pod的.spec.nodeName。
PS:未来可能会将UnReserve与Reserve统一到一起,即要求开发者在实现Reserve的同时定义UnReserve,保证数据能够有效的清理,避免留下脏数据
扩展点9:Permit
Pod在Reserve阶段完成资源预留后、Bind操作前,开发者可以定义自己的策略在Permit阶段进行拦截,根据条件对Pod进行 allow(允许Pod通过Permit阶段)、reject(Pod调度失败)和wait(可设置超时时间)这3种操作。
Schedule Theread周而复始的从activeQ拿出Pod,进入scheduling cycle的调度流水线。
scheduling cycle结束后,这个Pod会异步交给Wait Thread,Wait Thread如果等待成功了,就会交给binding cycle
2、Binding cycle
扩展点10:prebind
-
VolumeBinding:将之前Reserve阶段的volumebinding实际更新到apiserver中,等待PV Controller完成binding。最终所有PV都处于bound状态且NodeAffinity得到满足。
扩展点11:bind
进行最后实际的绑定,更新Pod和Node的数据
-
DefaultBinder
选中的节点在和待调度Pod进行Bind的时候,有可能会Bind失败,此时需要做回退,把Pod的Assumed状态退回Initial,从Node里面把Pod数据账本擦除掉,会把Pod重新丢回到unschedulableQ队列里面。在unschedulableQ里,如果一个Pod一分钟没调度过,就会重新回到activeQ。它的轮询周期是30s。
调度失败的Pod会放到backoffQ,在backoffQ里等待的时间会比在unschedulableQ里更短,backoffQ里的降级策略是2的指数次幂降级。假设重试第一次为1s,那第二次就是2s,第三次就是4s,但最大到10s。
最终,某个Node上的kubelet会watch到这个Pod属于自己所在的节点。kubelet会在节点上创建Pod,包括创建容器storage、network。等所有的资源都准备完成,kubelet会把Pod状态更新为Running
参考资料:
[1] https://kubernetes.io/docs/home/
[2] https://edu.aliyun.com/roadmap/cloudnative
[3] 郑东旭《Kubernetes源码剖析》
下一部分:k8s调度器扩展机制

