Linux Container
Docker官网对Container的定义是:Package Software into Standardized Units for Development, Shipment and Deployment
Container这个单词的本意是集装箱,一般翻译成容器。里面装了运行某个项目所需要的代码、语言运行环境、工具和引用库等所有东西
可以将Container理解为一个视图隔离、资源可限制、独立文件系统的进程集合
下图简单描述了一个Container的启动过程:
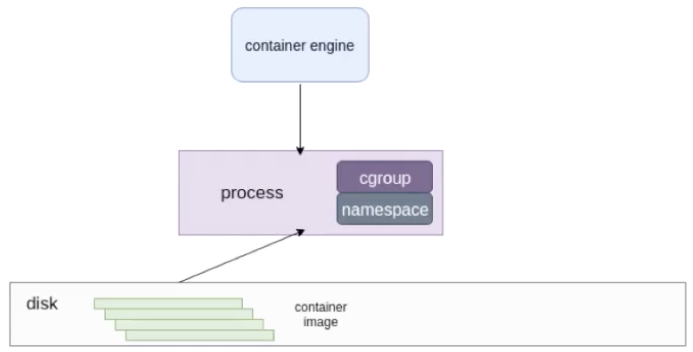
Container容器的本质是宿主机上的进程(容器进程),它的实现依赖于以下技术:
Linux Namespace
容器的资源隔离主要指进程资源的隔离。实现资源隔离的核心技术是Linux namespace。它和很多编程语言(如C++)的namespace的设计思想是一致的。
隔离意味着可以抽象出多个轻量级的内核(容器进程),这些进程可以充分利用宿主机的资源,宿主机有的资源容器进程都可以享有,但彼此之间是隔离的。同样,不同容器进程之间使用资源也是隔离的,容器间进行相同的操作,都不会互相干扰,安全性得到保障。
| 命名空间 | 系统调用参数 | 隔离内容 | 效果 |
| UTS | CLONE_NEWUTS | 主机名、NIS域名 |
容器在网络上就可以被视为一个独立的节点, 在容器中对hostname 的修改不会对宿主机造成任何影响 |
| IPC | CLONE_NEWIPC |
vSystem V IPC、
POSIX message queues
|
容器进程间通信(信号量、消息队列和共享内存)被隔离 |
| PID | CLONE_NEWPID | 进程编号 |
ps/top等命令底层读取的是/proc文件夹内的内容,
如果/proc文件系统没有挂载到一个与原/proc不同的位置,
仍然会显示与隔离前相同的内容
|
| Network | CLONE_NEWNET |
网络设备、IPv4和IPv6协议栈、 端口、IP 路由表、防火墙、 /proc/net目录、 /sys/class/net目录、socket等 |
跨容器通信需要通过veth pair; 或先建立一个Bridge, 将veth pair的两端分别绑定到 Bridge和容器中。 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
容器有独立的挂载点列表(文件系统视图)
实现效果类似chroot(change root directory)
|
| User | CLONE_NEWUSER | 用户 ID、用户组 ID |
用户创建的容器进程, 可属于与自己不同的用户、用户组(甚至是超级用户) |
| Cgroup | CLONE_NEWCGROUP | Cgroup根目录 | 容器拥有独立的Cgroup根目录 |
| Time | CLONE_NEWTIME |
CLOCK_BOOTTIME
CLOCK_MONOTONIC
|
容器可以看到不同的系统时间 |
为了支持这些特性,Linux namespace实现了8项资源隔离,基本上涵盖了一个小型操作系统的运行要素Namespace API提供了三种系统调用接口:
● clone():创建新的进程
● setns():允许指定进程加入特定的namespace
● unshare():将指定进程移出指定的namespace,加入一个新创的namespace
使用clone系统调用创建进程时,传入上表中的参数,就可以实现资源隔离,建立一个可以自己控制隔离内容的容器。
一个容器进程也可以再clone()出一个容器进程,这是容器的嵌套。
Linux命令unshare就是使用了unshare系统调用,例如:
[root@jfzwzxapp06 ~]# sudo unshare --mount-proc --pid --fork /bin/bash
[root@jfzwzxapp06 ~]# ps
PID TTY TIME CMD
1 pts/0 00:00:00 bash
48 pts/0 00:00:00 ps
可以看到这个bash进程的PID为1 ,说明它已经是在一个新的pid namespace里面。
如果想要查看当前进程下有哪些namespace隔离,可以查看文件/proc/[pid]/ns。每一项namespace都附带一个编号,这是唯一标识namespace的。如果两个进程指向的namespace编号相同,则表示它们同在该namespace下。
例如,查看Docker以默认运行时runC启动的容器进程
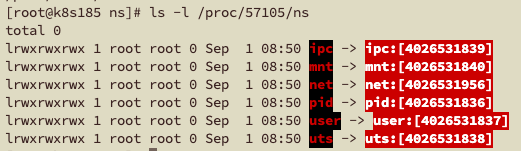
可以看到,runC只实现了6种namespace。这6种namespace实际上没有完全隔离Linux的资源,比如SElinux、cgroup以及/sys、/proc等目录下的资源。
例如,容器中执行free、top等命令,获得的信息与宿主机完全一致。docker top查看到的进程信息与ps -ef查询到的PID、执行命令等是一样的,只是筛选出来容器中的进程。
Cgroup
Cgroups的全称是Linux Control Groups,主要作用是限制、记录和隔离进程组(process groups)使用的物理资源(cpu、memory、IO等)
cgroup内核功能没有提供任何的系统调用接口,而是通过linux vfs(虚拟文件系统)向用户层提供接口,因此可以用类似文件系统的方式进行操作,也可以通过systemd、lxc、docker这些封装了cgroups的软件定义的接口控制cgroups的内容
docker容器有两种可使用的cgroup driver:
-
cgroupfs:要限制进程的内存多少、CPU等,可以直接把pid、对应需要限制的资源也写入相应的memory cgroup文件、CPU cgroup文件等
-
systemd:如果用systemd做cgroup驱动,所有写cgroup操作都必须通过systemd的接口来完成,不能手动更改cgroup的文件。
kubelet使用的cgroup driver驱动必须和docker相同
例如,在/etc/docker/daemon.json中指定docker使用的cgroup driver为systemd:
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
在kubelet启动的环境变量中指定--cgroup-driver=systemd
Linux内核本身提供了很多种cgroup,但是docker容器用到的只有下面六种:
1、CPU cgroup,一般会设置cpu share和cupset,控制CPU的使用率
2、memory ,控制了进程内存的使用量
3、device cgroup,控制了可以在容器中看到的设备
4、freezer cgroup。停止容器的时候,会把当前的进程全部都写入cgroup,然后把所有的进程都冻结掉。防止在停止的时候,有进程做fork逃逸到宿主机上
5、blkio cgroup,用于限制块设备I/O速率
docker run -it --rm --blkio-weight 100 ubuntu-stress:latest /bin/bash docker run -it --rm --blkio-weight-device "/dev/sda:100" ubuntu-stress:latest /bin/bash docker run -it --rm --device-write-bps /dev/sda:1mb ubuntu-stress:latest /bin/bash docker run -it --rm --device-write-iops /dev/sda:5 ubuntu-stress:latest /bin/bash
--blkio-weight设定容器io操作优先级,在10~1000之间,linux io schedule必须设置为CFQ(Completely Fair Queueing)
--blkio-weight-device指定某个设备的权重大小
--device-read-bps、--device-write-bps设定每秒读写块设备的数据量设定上限,单位是kb、mb、gb
--device-read-iops、--device-write-iops设定每秒读写操作次数设定上限
6、pid cgroup,限制容器里面可以用到的最大进程数量
使用--ulimit nproc=1:3参数进行限制,第一个数字是soft limit,第二个是hard limit
docker不支持的cgroup有net_cls rdma cgroup、net_prio cgroup、hugetlb cgroup、perf_event cgroup、rdma cgroup。
PS:除了rdma cgroup,其它的cgroup在runC里面其实都是支持的
容器流程示例
容器start的流程:
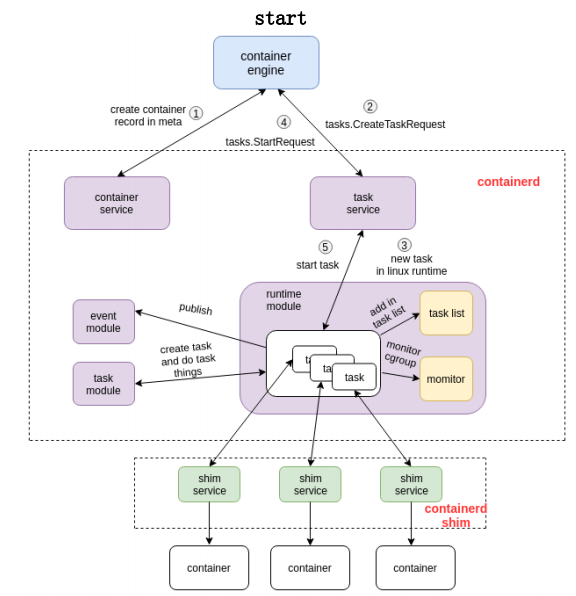
创建容器的过程:首先创建一个matadata,然后发创建容器的请求给task service。通过中间一系列的组件,最终把请求下发到一个shim。containerd通过GRPC把创建请求发给shim之后,shim调用runtime创建一个容器出来。
容器exec的流程:

exec的操作还是发给containerd-shim的。对容器来说,start和exec其实并没有本质的区别。
区别在于,是否对容器中跑的进程做namespace的创建:
exec需要把这个进程加入到一个已有的namespace里面
start时,容器进程的namespace需要去专门创建。
总结:Container和虚拟机的区别
Container的核心思想是利用内核机制,来实现类似VM的功能,从而利用更加节省的硬件资源提供给用户更多的计算资源。
它比VM少了hypervisor层(一种运行在物理服务器和操作系统之间的中间层软件,可以允许多个操作系统和应用共享一套基础物理硬件),被设计用来运行单进程,无法很好地模拟一个完整的环境。
使用Container时必须做出的最大思维变化之一就是:Container应该是短暂和一次性的。
例如,虚拟机中,CentOS的进程发送syscall内核调用,该请求会被虚拟机内的CentOS的内核接到,然后CentOS内核访问虚拟硬件时,由虚拟机的服务软件截获,并使用宿主系统,也就是Ubuntu的内核及userland的库去执行。而且,Linux和Windows在这点上非常不同。Linux的进程是直接发syscall的,而Windows则把syscall隐藏于一层层的DLL服务之后,因此Windows的任何一个进程如果要执行,不仅仅需要Windows内核,还需要一群服务来支撑,所以如果Windows要实现类似的机制,容器内将不会像Linux这样轻量级,而是非常臃肿。
例如,时间是从epoch到当前的秒数或者毫秒数,全球都一样,这是绝对值;而时区则是由于地理位置差异、行政区划导致各地显示时间的差异。对于容器而言,根本不存在宿主和容器的时间差异问题,因为他们使用的是同一个内核、同一个时钟,二者完全一样,所以根本不存在同步问题。
所以,容器只是一个进程而已,只不过利用镜像提供的rootfs提供了调用所需的userland库支持,使得进程可以在受控环境下运行而已,它并没有虚拟出一个机器出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号