软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 阅读《构建之法》、学习使用git以及github、WordCount编程、撰写博客 |
| 其他参考文献 | CSDN、博客园、知乎...... |
目录
part1:阅读《构建之法》并提问
问题一
读了56~57页“专和精的关系”,我想问的是究竟该往哪个方向发展:是成为一个什么都会一点的全栈工程师,还是成为只精通某一种语言的工程师?哪个方面会更吃香?
我自己是觉得可以成为精通一门语言的工程师比较好,把这门语言学到深,真正去理解这门语言,使用的时候就会得心应手。当然,这不意味着不要去学习其他语言、技术,只是不需要学得那么深入,会基本语法,能够使用就行,自身是需要精通一门语言的,才有底气。
问题二
读了74页的注释规范,这里说“应该只用ASCILL码,不能用中文字符”我有点不大理解?
我的观点是认为注释的作用就是为了让其他程序员,甚至是自己看得懂代码写的是什么功能,是易读的。如果在欧美国家,用ASCII码当然没问题。但是在我们自己看来,英文注释反而大大阻碍了其可读性,我遇到英文注释,可能还需要借助翻译工具,这样就浪费了我的时间。而且写中文注释可以同英文代码更好的区分开来,哪个是注释,哪个是代码。
问题三
读了84~85页,我认识到结对编程的必要之处,那我想问如何进行有效的结对编程?若是其中一个人能力不足,或者总在偷懒,又因为项目要到时间了,另一个人只能被迫完成大部分内容,这样的结对编程反而无法带来好处,那么如何避免这种情况的出现呢?
我自己的能想到的解决方法是,找个能力相近的有责任心的人一起结对编程。不知道还有没有更好的解决方法?
问题四
敏捷开发的一个原则是“可用的软件是衡量项目进展的主要指标”,我想问的是“可用的软件”的具体含义指的是什么?指的是仅实现功能需求的软件,但是仍存在一些bug,还是指的是无bug的软件?如何判断一个软件是可用的?有没有什么具体的标准?
我的认知可用的软件是指实现功能需求且目前暂未发现bug的软件,有bug的软件虽然可能还是可用的,但是bug迟早是要解决的,我更愿意把无bug的软件称之为“可用的软件”。
问题五
读到第八章收集用户需求时,我有一个问题:软件开发时是满足大部分人所需要的需求,还是尽量满足所有用户各式各样的需求,即对小众用户的需求是否要满足?比如手机的旁白模式,这个对大多数人是用不到的,但市面上基本所有的手机都实现了这个功能,因为他对一些人来说这是非常必要的。
因此,我的观点是尽量满足用户的各种合理的需求,这无疑会增加编程的工作量,但是,这样的软件才能更好的服务用户。
Android并不是Google的亲儿子
在2003年,AndyRubin,Rich Miner,Nick Sears,和 Chris White 四人共同研发(Android就是用AndyRubin的昵称来命名)直到2005年Android被Google收购,从而改变了这个手机操作系统的命运。所以Android并不是Google自行开发的产品,而是收购得来的。
参考链接
part2:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 1320 | 1255 |
| • Analysis | • 需求分析 (包括学习新技术) | 210 | 240 |
| • Design Spec | • 生成设计文档 | 30 | 60 |
| • Design Review | • 设计复审 | 30 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 45 |
| • Design | • 具体设计 | 120 | 130 |
| • Coding | • 具体编码 | 720 | 600 |
| • Code Review | • 代码复审 | 30 | 50 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 100 |
| Reporting | 报告 | 120 | 115 |
| • Test Repor | • 测试报告 | 60 | 40 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 45 |
| 合计 | 1470 | 1410 |
解题思路描述
一开始看到题目时,发现是在命令行运行程序,有点懵。查找资料后才明白args就是命令行传入的参数,这么一来就知道文件的路径,那么问题就变得好解决了。
我的解题步骤如下:
1、读入文件并转为字符串,于是直接百度Java读取文件的操作,最后选择了一个字符一个字符的读文件。
2、统计总字符数:这个就很简单了,字符串的长度就是总字符数。
3、统计单词总数:在查找资料之后,发现正则表达式是个很不错的选择,于是花时间学习了一下正则表达式的用法。
4、统计有效行数:我选择的方法是一行一行的重新读文件,遍历每一行的字符,若是遇到不是空白字符的字符,说明这一行是有效行,行数+1。
5、统计单词频数:map无疑是个很好的选择,可以存储key、value,其本身还自带根据key、value进行排序的方法。
最后输出结果到文件则是查阅Java合适、且同时可把编码格式设为UTF-8的输出方法。
代码规范制定链接
设计与实现过程
程序一共有两个类:WordCount类:用于读取命令行的参数,并根据文件路径构造File,只有main函数
HandleTxt类:用于处理File的类,其中有Changestr方法:将文件内容转为String字符串;Returnnum方法:返回文件总字符数;Getwords方法:返回单词总数;Getlines方法:获取文章的有效行数;GetTen方法:排序,并取前十个频率最高的单词的Map;Ouputxt方法:输出结果至output.txt。
在WordCount创建一个HandleTxt的对象,在HandleTxt的构造函数中调用处理文件的方法。
Changestr实现
选择一个字符一个字符地读取文件,同时将得到的字符串转为小写。其中发现了Windows回车是\r\n,是两个字符。
关键代码
StringBuffer sb=new StringBuffer();
FileInputStream fileInputStream=new FileInputStream(in);
while ((n=fileInputStream.read())!=-1)
{
char ch=(char)n;
sb.append(ch);
}
txt=sb.toString();
txt=txt.toLowerCase();
Returnnum实现
由于在Changestr方法中得到了文件内容的字符串,因此只要获取字符串长度就得到了文件总字符数
关键代码
public int Returnnum()
{
return txt.length();
}
Getwords实现
返回单词总数选择用正则表达式进行匹配。
关键代码
Pattern pattern=Pattern.compile("(^|[^a-z0-9])([a-z]{4}[a-z0-9]*)");
Matcher matcher=pattern.matcher(txt);
while (matcher.find())
{
words++;
}
Getlines实现
选择重新一行一行读文件,若遇到行中存在为非空白字符的字符,行数加一
关键代码
String content=br.readLine();
StringBuilder sb=new StringBuilder();
while (content!=null)
{
for(int i=0;i<content.length();i++)
{
if(content.charAt(i)!='\t'&&content.charAt(i)!='\n'&&content.charAt(i)!=' '
&&content.charAt(i)!='\r')
{
line++;
break;
}
}
content=br.readLine();
}
GetTen实现
同样用正则表达式进行匹配,结果选择使用Map进行存储和排序,并取排序后的前10个
关键代码
while (matcher.find())
{
if (Legalchar(txt.charAt(matcher.start()-1)))
{
word=matcher.group();
if (WordsMap.containsKey(word))//Map中已含有此单词
{
WordsMap.put(word,WordsMap.get(word)+1);
}
else
{
WordsMap.put(word,1);
}
}
}
//排序结果取前十个存放到result中
WordsMap.entrySet().stream().sorted(Map.Entry.<String, Integer> comparingByValue().reversed()
.thenComparing(Map.Entry.comparingByKey())).limit(10)
.forEachOrdered(x->result.put(x.getKey(),x.getValue()));
Ouputxt实现
使用PrintWriter,设置编码为UTF-8,将字符串输出到b.txt
关键代码
PrintWriter pw=new PrintWriter(new OutputStreamWriter(new FileOutputStream(out),
"UTF-8"));
Iterator<Map.Entry<String, Integer>> it=GetTen().entrySet().iterator();
sb.append("characters: "+Returnnum()+"\n"+"words: "+Getwords()+'\n'
+"lines: "+Getlines()+'\n');
while(it.hasNext())
{
Map.Entry<String, Integer> entry=it.next();
sb.append(entry.getKey()+": "+entry.getValue()+"\n");
}
pw.print(sb.toString());
pw.flush();
pw.close();
性能改进
运行3,251,088 字节的文件,耗时7309ms。
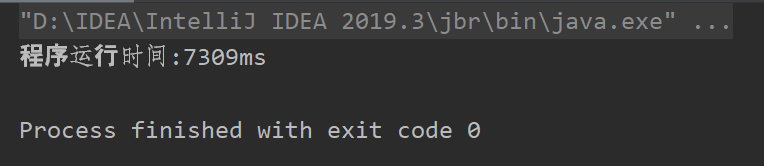
改进方法:在获取行数的方法中,一旦读到非空白字符,直接break,无需遍历整行。
if(content.charAt(i)!='\t'&&content.charAt(i)!='\n'&&content.charAt(i)!=' '
&&content.charAt(i)!='\r')
{
line++;
break;
}
单元测试
测试returnnum方法
测试能否正确读入\n\t@$等字符,字符数是否有错。
String str="dskjsh kf"+"\n\t\r"+"fdk233458884*@@$$^QJ BCJKL";
HandleTxt lib=new HandleTxt(str);
assertEquals(lib.Returnnum(),str.length());
测试getwords方法
测试其能否正确判断单词,其中只有"assd "、"\nfile123"为单词。
String str="assd "+"*1sded34"+" ws123"+"\nfile123";
HandleTxt lib=new HandleTxt(str);
assertEquals(lib.Getwords(),2);
测试getTen
测试函数能否正确存储单词,并排序。
String str=" asdd23 ASdd23 aSdd23 dfgrrrr ghjth cxccxd *zsdsds zsdsds zsdsds zsDsds\n"+" ddfg123 fgfdg234\n"+"\n" +
" Sfgh\n" +
"\n" +
"dsdaasdas asdd\n";
str=str.toLowerCase();
HandleTxt lib=new HandleTxt(str);
Map<String,Integer> map=new HashMap<>();
map.put("zsdsds",4);
map.put("asdd23",3);
map.put("asdd",1);
map.put("cxccxd",1);
map.put("ddfg123",1);
map.put("dfgrrrr",1);
map.put("dsdaasdas",1);
map.put("fgfdg234",1);
map.put("ghjth",1);
map.put("sfgh",1);
assertEquals(lib.GetTen(),map);
测试覆盖率截图
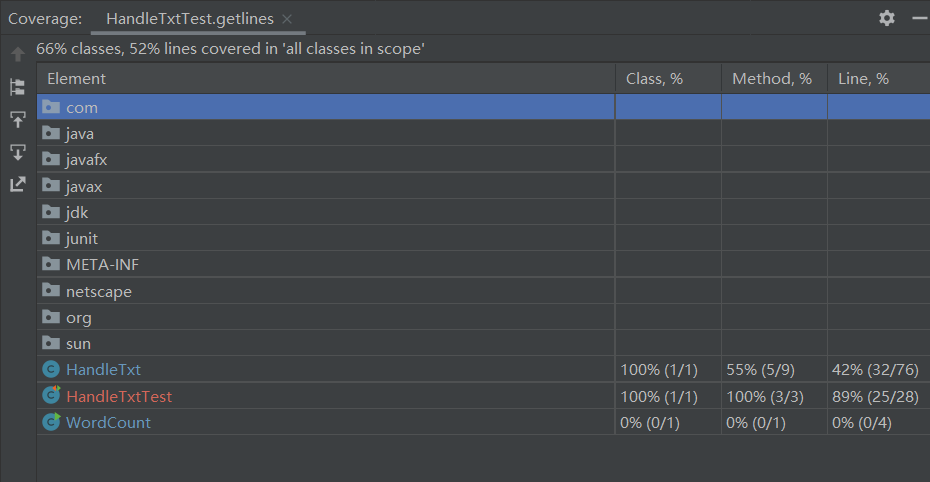
可以使用读入文件的方式,去测试Changestr、Getlines方法,从而优化覆盖率。
异常处理说明
只对WordCount读入的参数做了异常处理,其余部分选择直接throws Exception。
if(args.length==0)
{
System.out.println("没有参数");
}
else if(args.length==1)
{
System.out.println("输入参数只有一个");
}
else if(args.length==2)
{
File in=new File(args[0]);
File out=new File(args[1]);
if(!in.exists())
{
System.out.println("输入文件不存在");
}
else if(!out.exists())
{
System.out.println("输出文件不存在");
}
心路历程与收获
心路历程
- 一开始看过去觉得这个题目不难,之前写过类似的项目。直到做了才发现,它是从命令行读取参数,从哪里获取参数一开始就难到我了。之后的读取文件同样也是个考验,一开始我是选用readline读取文件,可是无法读入\n,于是我选择每读一行添加一个\n,这样导致的结果是最后一行必定会有一个\n,不符合要求。然后我选择了一个字符一个字符的读取,结果被Windows的回车埋伏了一手,因为Windows的回车是两个字符,导致我一直以为代码哪里出了问题。
- 同时还学习了新工具git、github的使用,从一开始的拒绝到最后发现这真是个好工具。
- 同时还认识到大任务其实不可怕,只要拆分成一个个的小任务,认真完成每一个小任务,当最后一个小任务完成时,大任务也便完成了。这次作业付出了许多精力和时间,但同样的收获也是满满的。
收获
- 学会了使用git、github
一开始看到要用git、github,我的内心是拒绝的。因为我从未使用过这两个工具,怕自己学不会。当看完教程,学会使用,并且在项目中使用后,才发现其功能的强大。能够有效的控制版本,进行代码管理,代码的修改一目了然,做了什么改动也有commit信息,我已经爱上了这两个工具了。
- 学会了单元测试
学会使用Junit进行测试,发现这个真方便,IDEA还能快捷键生成测试类。通过Junit,我就可以单独方便地对我写的某一个函数进行测试,排除bug。不需要再像往常一样需要运行整个程序,使我的工作完成得更轻松,大大减少我花在调试上面的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号