
MapReduce编程系列 — 1:计算单词
1、代码:
package com.mrdemo; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } //conf.set("fs.defaultFS", "hdfs://192.168.6.77:9000"); Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
2、准备测试数据。
在hdfs中新建一个input01文件夹,然后将/home/hadoop/Documents文件夹下新建的hello文件上传到hdfs中的input01文件夹中。
测试数据:
hello world!
hello hadoop
jobtracker
maptracker
reducetracker
task
namenode
datanode
block
beautiful world
hadoop:
HDFS
MapReduce
hello hadoop
jobtracker
maptracker
reducetracker
task
namenode
datanode
block
beautiful world
hadoop:
HDFS
MapReduce
3、命令
hadoop@hadoop-ThinkPad:~$ hadoop fs -mkdir input01
hadoop@hadoop-ThinkPad:~$ cd /home/hadoop/Documents
hadoop@hadoop-ThinkPad:~/Documents$ hadoop fs -copyFromLocal hello input01
hdfs://localhost:9000/user/yyq/input01
hdfs://localhost:9000/user/yyq/output01
hdfs://localhost:9000/user/yyq/output01
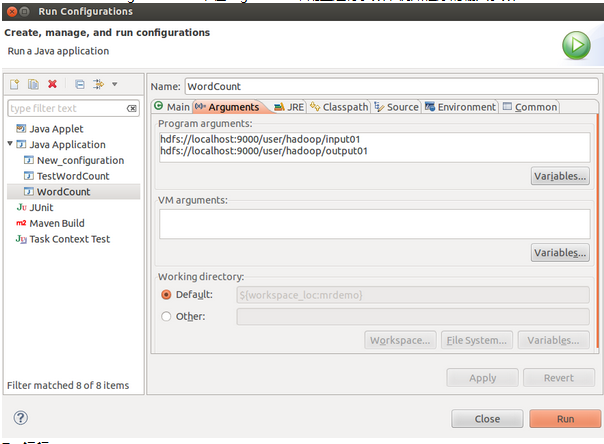
4、配置运行参数
Run As → Run Configurations… ,在Arguments中配置运行参数,例如程序的输入参数:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号