Solr搜索
一、搜索
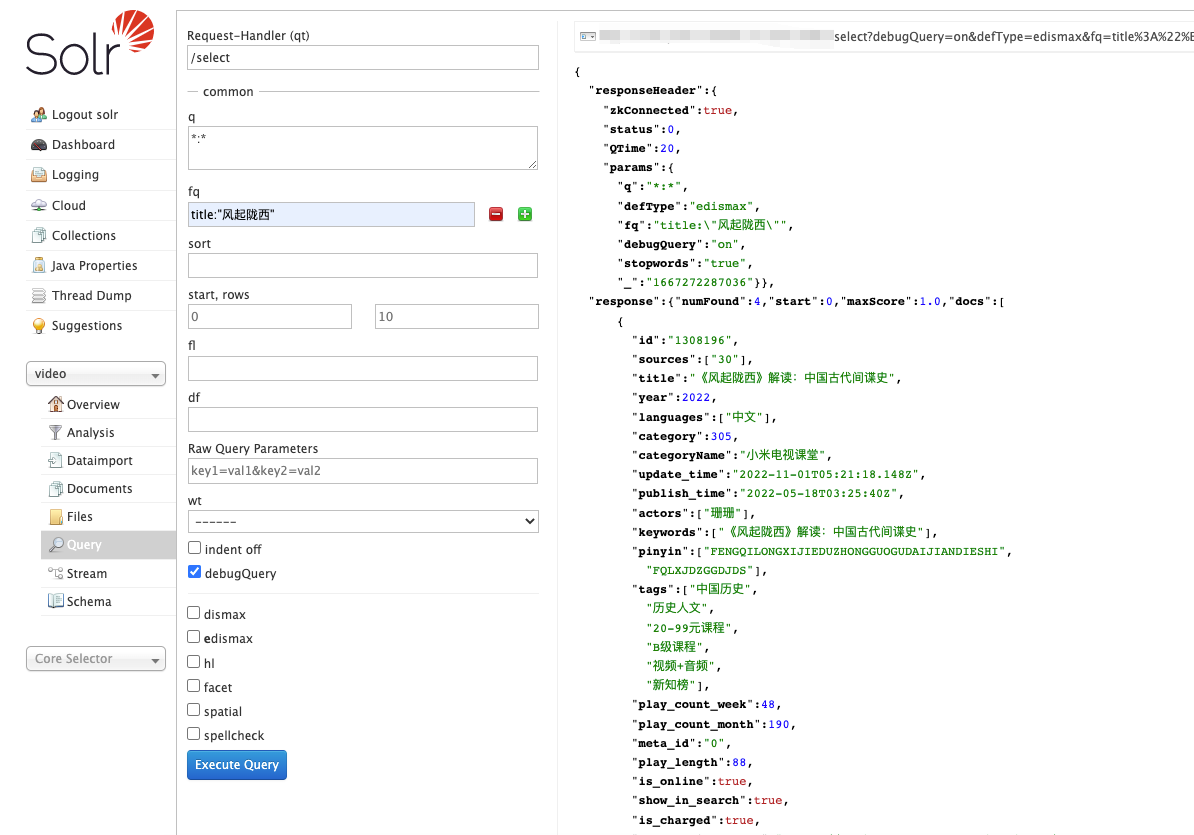
1、 向techproducts索引中添加数据 ,solr解压的example/exampledocs目录中有多种文档格式的示例数据,使用以下命令将其存在techproducts索引中
./bin/post -c techproducts example/exampledocs/*
2、基本搜索
实际上 Solr的管理界面是通过URL的方式请求数据的,如:http://localhost:8983/solr/techproducts/select?q=0812521390
①:查询语法
| 参数名 | 描述 |
| q |
查询关键字,例如,q=id:1,默认为q=*:*,类似于sql中的where 1=1 默认的排序是score desc |
| start | 结果集第一条记录的偏移位置,用于分页,默认为 0 |
| rows | 返回文档的记录数,用于分页,默认为 10 |
| sort | 排序,如如id desc 表示按照 “id” 降序。id desc, price asc先按id降序,再按price升序 |
| fl |
(field list)指定返回字段,多个字段用逗号或空格分隔,默认返回所有字段 默认搜索结果里没有score字段,要展示score字段,在fl里指定 *,score即可 |
| wt | (writer type)指定输出格式,例如xml、json等,默认json |
| fq |
(filter query)过滤查询。该参数可将查询的结果限定在某一范围,由于 Solr 会对过滤查询进行缓存,因此它可以显著提升复杂查询的效率 注意:fq不会按score倒序排序,fq和bq结合使用实现加权排序 |
| hl | 用于设置字段的高亮显示 |
| df | (default field)默认的查询字段,一般默认指定 |
| qt | (query type) 指定那个类型来处理查询请求,一般不用指定,默认是standard |
| indent | 返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数 |
| debug | 该debug参数可以多次指定,并支持以下参数,debug=query:仅返回有关查询的调试信息;debug=timing:返回有关查询花费多长时间处理的调试信息;debug=results:返回关于 score 结果的调试信息;debug=all:返回关于 request 请求的所有可用调试信息。(可替代地使用:debug=true) |
| cache | Solr默认缓存所有查询的结果并过滤查询。要禁用结果缓存,请设置cache=false |
| timeAllowed | 此参数指定允许搜索完成的时间量(以毫秒为单位)。如果此时间在搜索完成之前到期,任何部分结果将返回 |
| defType | 用来指定查询解析器,默认的defType=lucene,可选defType=edismax |
②:运算符
| 运算符 | 说明 |
| : | 指定字段目标值,等同于 SQL 中的 “=” 号,返回所有值 *:* |
| ? | 表示单个任意字符的通配 |
| * | 表示多个任意字符的通配(不能在检索的项开始使用*或者?符号) |
| ~ | 表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录 |
| AND | 表示且,等同于 “&&” |
| OR | 表示或,等同于 “||” |
| NOT | 表示否 |
| () | 用于构成子查询 |
| [] | 范围查询,包含头尾 |
| {} | 范围查询,不包含头尾 |
| + | 存在运算符,表示文档中必须存在 “+” 号后的项 |
| - | 不存在运算符,表示文档中不包含 “-” 号后的项 |
查询解析器:
1、Lucene
默认的查询解析器,也称为标准查询解析器。标准查询解析器的语法允许在搜索中更加精确
2、DisMax
即Maximum Disjunction,其定义为:一个查询,它生成由其子查询产生的文档的联合,该查询将为每个文档评分(由任何子查询生成的该文档的最高分数),并为任何其他匹配的子查询加一个并列中断增量
相比标准查询解析器,DisMax查询解析器更能容忍错误,其旨在提供类似于流行的搜索引擎(如Google)的体验
3、eDisMax
扩展的DisMax查询解析器是DisMax的改进版本,它处理完整的 Lucene 查询语法,同时仍然容忍语法错误。
除了支持所有的disMax查询解析器参数外,eDisMax解析器还有如下扩展:
1)支持完整的Lucene查询分析器语法,它与Solr的标准查询解析器具有相同的增强功能
①:支持AND、OR、NOT、-和+等查询
②:在 Lucene 语法模式下可选地将 “and” 和 “or” 视为 “AND” 和 “OR”
③:尊重 'magic 字段' 的名字:_val_ 和 _query_。这些在 Schema 中不是真实的字段,但是如果使用它,它可以帮助做特殊的事情(如 _val_ 的情况下的函数查询, 或者在 _query_ 中的嵌套查询)。如果 _val_ 用于术语或短语查询,则该值将作为函数进行分析
2)在语法错误的情况下包括改进的智能部分转义; 在此模式下仍然支持字段查询、+/- 和短语查询
3)通过使用单词 shingles 来提高接近度增强;在应用近似增强之前,不需要查询来匹配文档中的所有单词
4)包括高级的停用词处理:在查询的强制部分中不需要停用词,但仍用于近似增强部分。如果一个查询由所有的停用词组成,例如“to be or not to be”,那么所有的单词都是必需的
5)包括改进的 boost 功能:在 eDisMax 中,该 boost 功能是一个乘数而不是加数,提高了您的 boost 效果;DisMax的附加 boost 功能(bf 和 bq)也被支持
6)支持纯粹的消极嵌套查询:诸如 +foo (-foo) 的查询将匹配所有文档
7)让您指定允许最终用户查询哪些字段,并禁止直接派遣的搜索
edismax查询参数:
| 参数名 |
描述 |
| q |
该 q 参数定义了构成搜索本质的主要 “查询”。该参数支持用户提供的原始输入字符串,没有特殊的转义。术语中的 + 和 - 字符被视为“强制性”和“禁止”修饰符 用平衡的引号字符(例如,“San Jose”)包裹的文本被视为一个短语。包含奇数个引号字符的任何查询的计算方式就像根本没有引号字符一样 该 q 参数不支持通配符,如 * |
| q.alt | 如果指定,q.alt 参数定义一个查询(默认情况下将使用标准查询解析语法进行解析),当主 q 参数未指定或为空时。q.alt 当您需要一个类似于查询的东西来匹配所有的文档时(不要忘记 &rows=0),q.alt 参数就派上用场了,可以获得收集范围的 faceting 计数 |
| qf |
(Query Fields),qf参数引入了一个字段列表,每个字段都分配了一个boost(提升)因子来增加或减少该字段在查询中的重要性 如:qf="fieldOne^2.3 fieldTwo fieldThree^0.4" 分配 fieldOne 一个 2.3 的提升, fieldTwo 为默认提升(因为没有 boost 因素被指定,默认为1),并且 fieldThree 提高 0.4。这些 boost 因素使 fieldOne 中的匹配比 fieldTwo 的匹配更加重要,fieldTwo比 fieldThree 中的匹配更为重要, |
| mm | 最小匹配,如果我们不严格要求AND,可以配置mm来定义查询结果集的匹配程度 |
| pf | (Phrase Fields),
一旦使用 fq 和 qf 参数确定了匹配文档的列表,就可以使用 pf 参数“boost”文档的得分,因为 q 参数中的所有项都出现在非常接近的情况下。 该格式与 qf 参数所使用的格式相同:当从整个 q 参数中进行短语查询时,字段列表和“boosts”将与每个字段相关联 |
| ps | (Phrase Slop)ps 参数指定应用于使用 pf 参数指定的查询的 “短语 slop” 的数量。短语 slop 是一个标记需要相对于另一个标记移动以匹配查询中指定的短语的位置的数量 |
| qs | (Query Phrase Slop)qs 参数指定用 qf 参数明确包含在用户查询字符串中的短语查询所允许的倾斜量。如上所述,slop 是指为了匹配在查询中指定的短语,一个标记需要相对于另一个标记移动的位置的数量 |
| tie | (Tie Breaker)
tie 参数指定一个浮点值(应该远远小于1),以便在 DisMax 查询中用作 tiebreaker。 当来自用户输入的术语针对多个字段进行测试时,可能会有多个字段匹配。如果是这样,每个字段将根据该字段在该字段中的普遍程度(对于每个文档相对于所有其他文档)产生不同的 score。通过该 tie 参数,您可以控制查询的最终 score 与最高 score 字段相比,将会受较低评分字段影响的程度。 值为“0.0”(默认值)使查询成为纯粹的“分离最大查询”:也就是说,只有最大 scoring 子查询才有助于最终 score。值为“1.0”使查询成为一个纯粹的“分离总和查询”,因为最终 score 将是子查询 score 的总和,这与最大 scoring 子查询无关。通常,一个较低的值(如0.1)是有用的 |
| bq |
(Boost Query)bq 参数指定一个附加的可选查询子句,将添加到用户的主要查询中以影响 score 对某个field的value进行boost,例如brand:xq^5.0 如,title:风起陇西 ,会按结果score倒序排序 |
| bf | (Boost Functions)提升函数,通过数学公式来影响评分,而且不局限在qf中的字段 |
| boost |
分析为查询的字符串的多值列表,并将其分数乘以所有匹配文档的主查询的分数。此参数是使用 BoostQParserPlugin 来包装 eDisMax 生成的查询的简写 boost 翻译过来是增长推动的意思,这里可以理解为一个支持可配的加权参数 |
fq详解:
fq 参数定义了一个查询,可以用来限制可以返回的文档的超集,而不影响 score。这对于加快复杂查询非常有用,因为指定的查询 fq 是独立于主查询而被缓存的。当以后的查询使用相同的过滤器时,会有一个缓存命中,过滤器结果从缓存中快速返回。
使用该 fq 参数时,请记住以下几点:
①:该 fq 参数可以在查询中多次指定
②:filter 查询可能涉及复杂的 Boolean 查询
③:每个过滤器查询的文档集都是独立缓存的
④:还可以在 fq 内部使用 filter(condition) 语法来单独缓存子句, 以及在其他情况下,实现缓存的筛选器查询的联合
⑤:与所有参数一样:URL 中的特殊字符需要正确转义并编码为十六进制值。在线工具可以帮助您使用 URL 编码。例如:http : //meyerweb.com/eric/tools/dencoder/
bq详解:
bq只用于影响分数,不作为查询的过滤条件
bq参数指定一个附加的可选查询子句,该子句将作为影响分数的可选子句添加到用户的主查询中,如想为category中特定类别添加提升,可以使用:
q=cheese
bq=category:food^10
也可以指定多个bq参数,每个参数都将作为带有单独提升的单独子句
q=cheese
bq=category:food^10
bq=category:deli^5
Solr排序打分机制:
1、无特殊排序要求时,根据查询相关度来进行排序(solr自身规则),q查询
2、当涉及到一个字段来进行相关度排序时,可以直接使用solr的sort功能来实现
3、对多个字段进行维度的综合打分排序
①:定制Lucene的boost算法,加入自己希望的业务规则
技术难度高,需要读懂Lucene的boost打分算法,在代码层做定制.
②:使用Solr的edismax实现的方法,通过bf查询配置来影响boost打分
因为受限于edismax提供的方法,所以有些局限性
③:在建索引的schema时设置一个字段做排序字段,通过它来影响文档的总体boost打分
加权:
加权的目的是影响搜索出来的文档的score
^ 权重,也叫提升因子,在搜索条件的末尾加上 ^ 提升因子,提升因子越高,该条件的相关性就越高
如:jakarta^4 或 短语:"jakarta apache"^4
默认情况下,提升因子为1,虽然提升因子必须为正,但它可以小于1,如为0.2
加权搜索
fq:(filter query),查询条件,返回结果不会按照score排序,如title:风气陇西
bq:(boost query),对查询条件进行加权,如title:风起陇西^2
函数查询:
函数查询使您能够使用一个或多个数字字段的实际值生成相关性分数
函数查询使用函数。函数可以是常量(数字或字符串文字)、字段、另一个函数或参数替换参数。您可以使用这些功能来修改用户的结果排名。这些可用于根据用户的位置或其他一些计算来更改结果的排名
使用函数查询语法:
函数必须表示为函数调用(例如,sum(a,b) ,而不是简单的a+b)
在 Solr 查询中使用函数查询有多种方法:
①:通过需要函数参数的显式查询解析器,例如funcor frange。例如:q={!func}div(popularity,price)&fq={!frange l=1000}customer_ratings
②:在排序表达式中。例如:sort=div(popularity,price) desc, score desc
③:将函数的结果作为伪字段添加到查询结果中的文档中。例如,对于:&fl=sum(x, y),id,a,b,c,score&wt=xml,输出将是:
...
<str name="id">foo</str>
<float name="sum(x,y)">40</float>
<float name="score">0.343</float>
...④:在明确指定函数的参数中使用,例如 eDisMax 查询解析器的boost参数,或 DisMax 查询解析器的bf(提升函数)参数。(请注意,该bf参数实际上采用由空格分隔的函数查询列表,每个查询都带有可选的提升。确保在使用时消除单个函数查询中的任何内部空格bf)。例如:
q=dismax&bf="ord(popularity)^0.5 recip(rord(price),1,1000,1000)^0.3"
⑤:使用关键字在 Lucene 查询解析器中引入函数查询内联_val_。例如:q=_val_:mynumericfield _val_:"recip(rord(myfield),1,2,3)"
可用于函数查询的函数:
| 函数 | 说明 | 示例 |
| abs函数 | 返回指定值或函数的绝对值 | abs(x) abs(-5) |
| childfield(field) 函数 | 搜索时返回匹配子文档之一的给定字段的值{!parent}。它只能在sort参数中使用 |
|
| concat连接函数 | 连接给定的字符串字段、文字和其他函数 | concat(name," ",$param,def(opt,"-")) |
| “常数”函数 | 指定浮点常量 | 1.5 |
| def 函数 | def是默认的缩写。返回字段“field”的值,或者如果该字段不存在,则返回指定的默认值。产生第一个值 where exists()==true |
|
| div 函数 | 将一个值或函数除以另一个。 div(x,y)除以。x_y |
|
| docfreq(field,val) 函数 | 返回字段中包含该术语的文档数。这是一个常数(索引中所有文档的值相同) | docfreq(text,'solr') |
|
max函数 |
|
max(myfield,myotherfield,0) |
| maxdoc 函数 | 返回索引中的文档数,包括那些标记为已删除但尚未清除的文档。这是一个常数(索引中所有文档的值相同) | maxdoc() |
| min函数 |
|
min(myfield,myotherfield,0) |
| if函数 |
启用条件函数查询。在if(test,value1,value2):
表达式可以是任何输出布尔值的函数,甚至可以是返回数值的函数,在这种情况下,值 0 将被解释为假,或者是字符串,在这种情况下,空字符串被解释为假 |
if(termfreq (cat,'electronics'),popularity,42):此功能检查每个文档以查看其是否在cat字段中包含术语“电子”。如果是,则popularity返回该字段的值,否则返回 的值42 |
| pow 函数 |
将指定的基数提高到指定的幂 |
pow(x,y) |
| log函数 |
返回指定函数的以 10 为底的对数 |
log(x) log(sum(x,100)) |
| product函数 |
返回以逗号分隔的列表指定的多个值或函数的乘积。 mul(…)也可以用作此函数的别名 |
|
| 查询功能 |
返回给定子查询的分数,或与查询不匹配的文档的默认值。任何类型的子查询都可以通过参数取消引用或通过键在本地参数$otherparam中直接指定查询字符串来支持 |
|
| recip接收函数 |
recip(x,m,a,b)通过实现a/(m*x+b)where m,a,bare 常量执行倒数函数,并且x是任意复杂函数 当a和b相等时x>=0,这个函数的最大值1随着x增加而下降。增加 和 的值会a导致b整个函数移动到曲线的更平坦部分。当 x 为 时,这些属性可以使其成为提升更新文档的理想函数rord(datefield) |
|
| sum 函数 |
加法函数,返回以逗号分隔的列表中指定的多个值或函数的总和。 add(…)可以用作此函数的别名 |
sum(x,y,…) sum(sqrt(x),log(y),z,0.5) |
| sub函数 |
减法函数,从 sub(x,y) 返回 x-y |
sub(x,y) |
| and 且函数 |
当且仅当其所有操作数的计算结果为 true 时,才返回 true 值 |
and(not(exists(popularity)),exists(price)):返回在字段中有值但在字段中没有true值的任何文档 |
| or 或函数 |
或 |
or(value1,value2): true如果其中一个value1或value2为真 |
| xor异或函数 |
逻辑排他析取,或一个或另一个但不是两者兼而有之 |
xor(field1,field2)true如果其中一个field1或field2为真,则返回;如果两者都为真,则为假 |
| not非函数 |
包装函数的逻辑否定值 |
not(exists(author)):true只有当exists(author)是假的 |
| exists存在函数 |
true如果字段的任何成员存在,则返回 |
|
| 比较函数:gt, gte, lt, lte,eq |
5个比较函数:大于、大于等于、小于、小于等于、等于。 eq不仅适用于数字,而且基本上适用于任何值,如字符串字段 |
if(lt(ms(mydatefield),315569259747),0.8,1) 翻译成这个伪代码:if mydatefield < 315569259747 then 0.8 else 1 |
| dist 函数 |
返回 n 维空间中两个向量(点)之间的距离。获取幂,加上两个或更多 ValueSource 实例并计算两个向量之间的距离。每个 ValueSource 必须是一个数字 必须传入偶数个 ValueSource 实例,并且该方法假定前半部分表示第一个向量,后半部分表示第二个向量 |
dist(2, x, y, 0, 0):计算每个文档的 (0,0) 和 (x,y) 之间的欧几里得距离 |
| ms毫秒函数 |
返回其参数之间的毫秒差异。日期相对于 Unix 或 POSIX 时间纪元,即 UTC 1970 年 1 月 1 日午夜 Arguments may be the name of a DatePointField, TrieDateField, or date math based on a constant date or NOW.
|
|
| termfreq 函数 |
返回术语在该文档的字段中出现的次数 |
termfreq(text,'memory') |
https://solr.apache.org/guide/7_7/function-queries.html
bf:boost functions
提升函数,通过数学公式来影响评分,而且不局限在qf中的字段
该bf参数指定将用于构造 FunctionQueries的函数,这些函数将作为影响分数的可选子句添加到用户的主查询中
q=cheese
bf=div(1,sum(1,price))^1.5
使用 bf 参数指定函数本质上只是将bq参数与{!func}解析器结合使用的简写,例如bf下面列出的两个参数,就完全等价于bq下面的两个参数:
bf=div(sales_rank,ms(NOW,release_date))
bf=div(1,sum(1,price))^1.5
等价于:
bq={!func}div(sales_rank,ms(NOW,release_date))
bq={!lucene}( {!func v='div(1,sum(1,price))'} )^1.5
二、score
1、向量空间模型
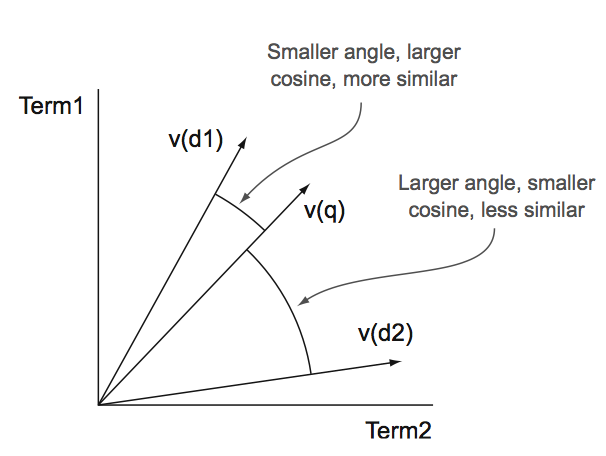
用v(d1)表示了term d1的term向量,向量空间模型中,两个term的相似程度是计算向量空间坐标系中两个term向量的夹角,如果夹角越小,说明相似程度越大,而角度的计算可以使用余弦定理计算
给定一个查询以及一个文档,计算相似值算法:

变量:
t = term, d = document, q = query , f = field
-
-
- q:查询词
- d:一个文档
- t:查询关键字,查询词分词后的每个字
-
函数:
-
- tf函数:词频, tf(t in d ) 表示该term 在 这个文档里出现的频率(即出现了几次)
- idf函数 :反转文档频率,出现该term的文档的个数。
- 文档总数/含有这个词的文档数,降低在所有文档中的高频词对搜索词含义的影响,举例:我、的、这类词出现的在所有文档都出现所以要降低它们在搜索查询词中的权重
- getBoost函数: 查询语句中每个词的权重,可以在查询中设定某个词更加重要。
- norm(t,d) 标准化因子d.getBoost() • lengthNorm(f) • f.getBoost() ,它包括三个参数:
- Document boost:此值越大,说明此文档越重要
- Field boost:此域越大,说明此域越重要
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms)):一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大
- coord(q,d):评分因子,是基于文档中出现查询词的个数。越多的查询词在一个文档中,说明些文档的匹配程序越高。默认是出现查询项的百分比,numTermsInDocumentFromQuery / numTermsInQuery:比如查询词被分词3个词,命中n个(n<=3),就是n/3
- qNorm(q)函数:查询因子,计算每个查询条目的方差和,此值并不影响排序,而仅仅使得不同的query之间的分数可以比较
2、评分机制
①:tf,表示term匹配文档的程度,如果在一篇文档中该term出现了次数越多,说明该term对该文章的重要性越大,因而更加匹配。相反的出现越少说明该term越不匹配文章。但是这里需要注意,出现次数与重要性并不是成正比的,比如term A出现10次,term B出现1次,对于该文章的重要性term A并不是term B的10倍,所以这里tf的值进行平方根计算
tf(t in d) = numTermOccurrencesInDocument½
②:idf, 表示包含该文章的个数,与tf不同,idf 越大表明该term越不重要。比如this很多文章都包含,但是它对于匹配文章帮助不大
idf(t) = 1 + log (numDocs / (docFreq +1))
③:t.getBoost,boost是人为给term提升权重的过程,我们可以在Index和Query中分别加入term boost,但是由于Query过程比较灵活,所以这里介绍给Query boost。term boost 不仅可以对Pharse进行,也可以对单个term进行,在查询的时候用^后面加数字表示
-
- title:(solr in action)^2.5 对solr in action 这个pharse设置boost
- title:(solr in action) 默认的boost时1.0
- title:(solr^2in^.01action^1.5)^3OR"solrinaction"^2.5
④:norm(t,d) 即field norm,它包含Document boost,Field boost,lengthNorm。
相比于t.getBoost()可以在查询的时候进行动态的设置,norm里面的f.getBoost()和d.getBoost()只能建索引过程中设置,如果需要对这两个boost进行修改,那么只能重建索引。他们的值是存储在.nrm文件中
norm(t,d) = d.getBoost() • lengthNorm(f) • f.getBoost()
-
- d.getBoost() document的boost,对document设置boost是通过对每一个field设置boost实现的
- f .getBoost() field的boost,这里需要提以下,Solr是支持多值域方式建索引的,即同一个field多个value。当一个文档里出现同名的多值域时候,倒排索引和项向量都会在逻辑上将这些域的词汇单元附加进去。当对多值域进行存储的时候,它们在文档中的存储顺序是分离的,因此当你在搜索期间对文档进行检索时,你会发现多个Field实例
- 当对多值域设置boost的时候,那么该field的boost最后怎么算呢?即为每一个值域的boost相乘。比如title这个field,第一次boost是3.0,第二次1,第三次0.5,那么结果就是3*1*0.5. Boost: (3) · (1) · (0.5) = 1.5
- lengthNorm, Norm的长度是field中term的个数的平方根的倒数,field的term的个数被定义为field的长度。field长度越大,Norm Field越小,说明term越不重要,反之越重要,这很好理解,在10个词的title中出现北京一次和在有200个词的正文中出现北京2次,哪个field更加匹配,当然是title
最后再说明下,document boost,field boost 以及lengthNorm在存储为索引是以byte形式的,编解码过程中会使得数值损失,该损失对相似值计算的影响微乎其微
⑤:queryNorm, 计算每个查询条目的方差和,此值并不影响排序,而仅仅使得不同的query之间的分数可以比较。也就说,对于同一词查询,他对所有的document的影响是一样的,所以不影响查询的结果,它主要是为了区分不同query了
-
- queryNorm(q) = 1 / (sumOfSquaredWeights )
- sumOfSquaredWeights = q.getBoost()2 • ∑ ( idf(t) • t.getBoost() )2
⑥:coord(q,d),表示文档中符合查询的term的个数,如果在文档中查询的term个数越多,那么这个文档的score就会更高
numTermsInDocumentFromQuery / numTermsInQuery
比如Query:AccountantAND("SanFrancisco"OR"NewYork"OR"Paris")
文档A包含了上面的3个term,那么coord就是3/4,如果包含了1个,则coord就是4/4
END.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号