ELK
什么是ELK?
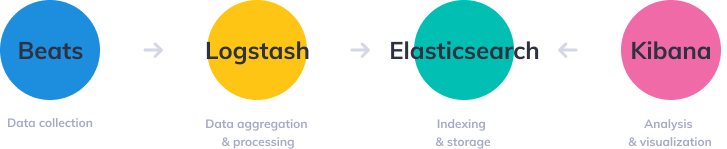
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
Elasticsearch 是一个搜索和分析引擎。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化

ELK Stack日志收集平台有多种组合方式:
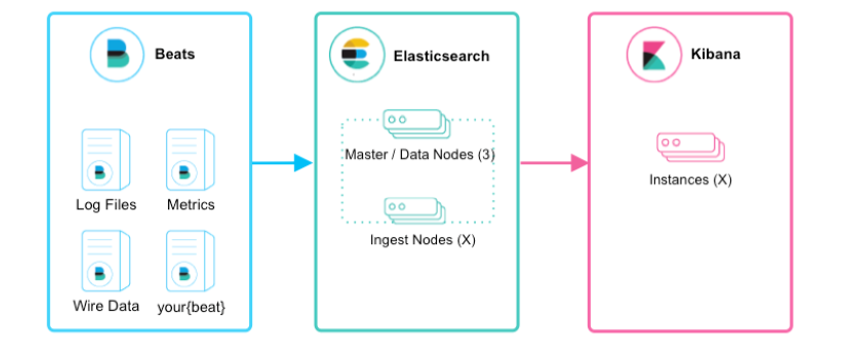
①:Beats+Elasticsearch+Kibana
②:Beats+Logstash+Elasticsearch+Kibana
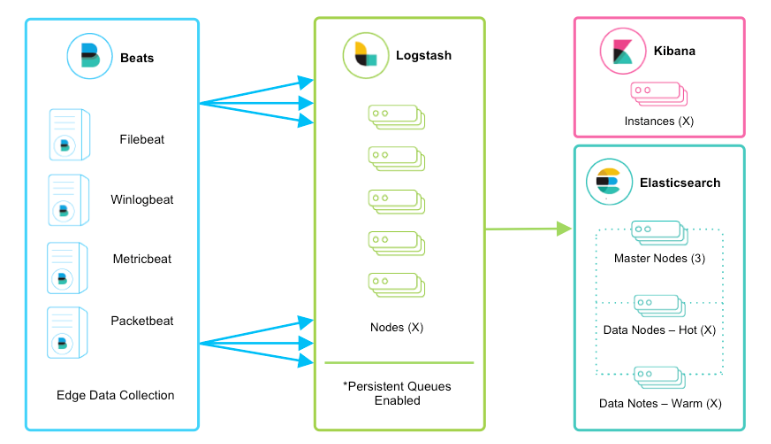
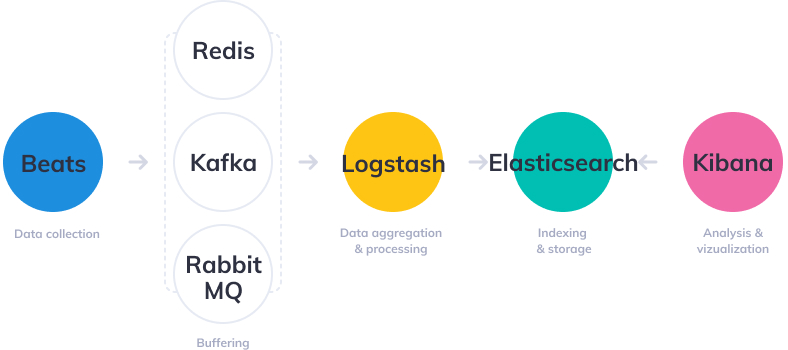
③:Beats+Kafka/Redis/RabbitMQ+Logstash+Elasticsearch+Kibana

④:Kafka+Logstash+Elasticsearch+Kibana
ELK Stack 的方式,这种方式对我们的代码无侵入,核心思想就是收集磁盘的日志文件,然后导入到 Elasticsearch。
比如我们的应用系统通过 logback 把日志写入到磁盘文件,然后通过这一套组合的中间件就能把日志采集起来供我们查询使用了
Beats+Logstash+Elasticsearch+Kibana
架构:
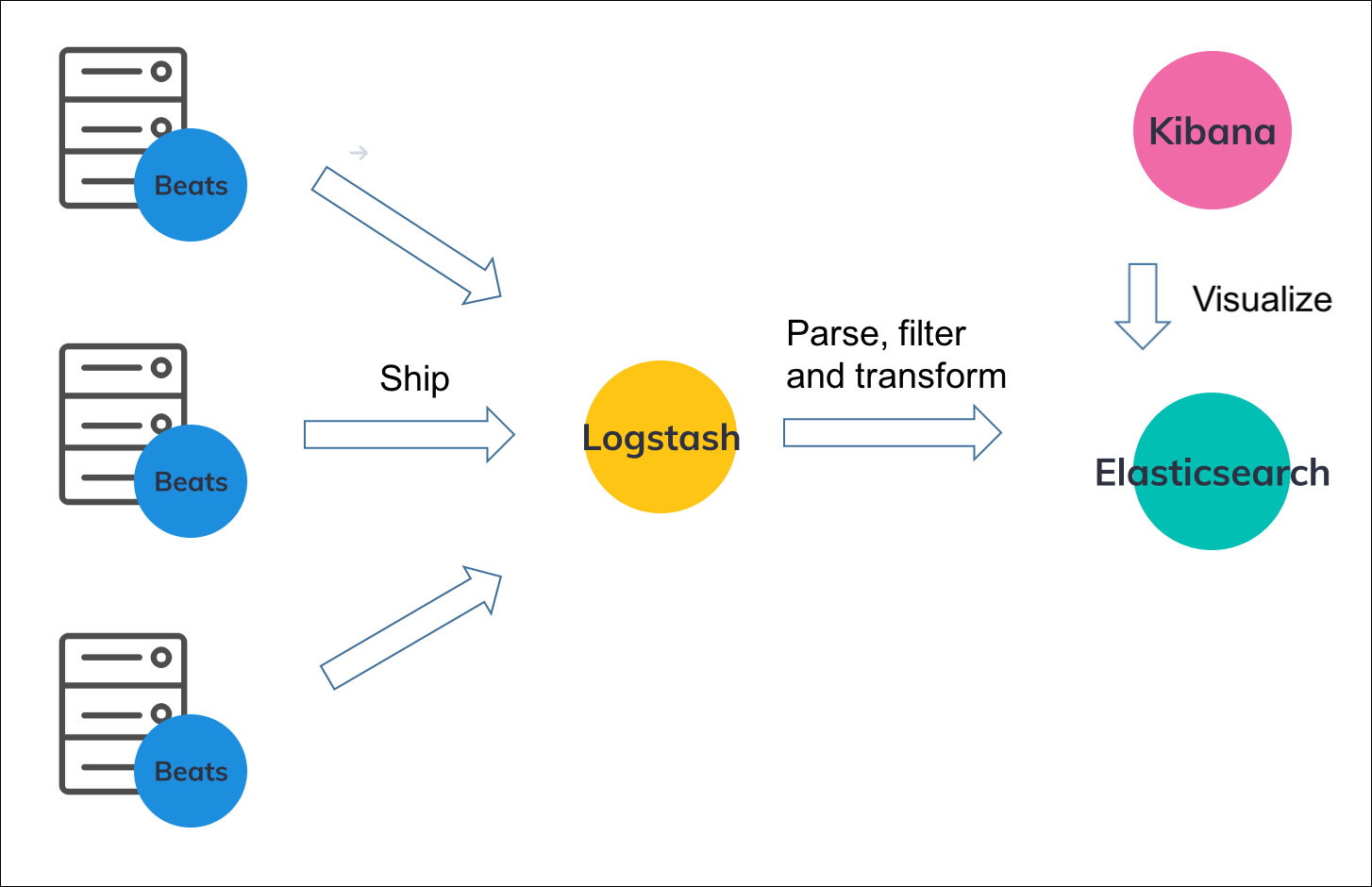
流程:
1、对于小型开发环境,经典流程如下:
①:FileBeat收集日志,发送给Logstash
②:Logstash对数据进行聚合、过滤、解析、转换等处理
③:将数据写入到Elasticsearch
④:Kibana可视化查询
2、对于生产中的大量数据,流程如下:
Filebeat:
文档:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-overview.html
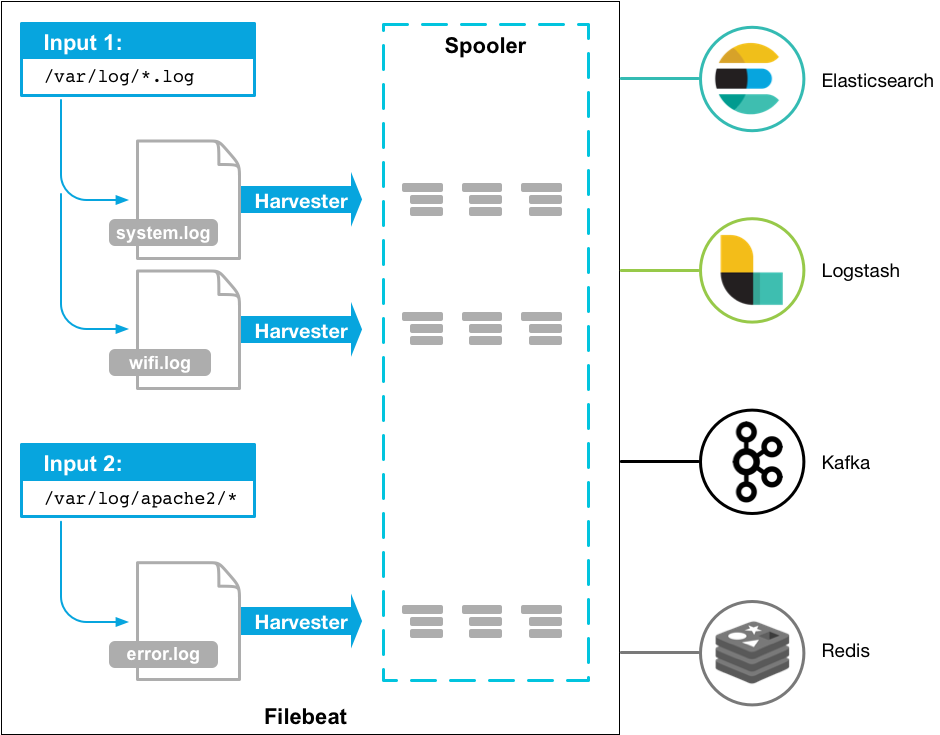
Filebeat 是一个用于转发和集中日志数据的轻量级传送器。作为代理安装在您的服务器上,Filebeat 监控您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash以进行索引
FileBeat工作原理:
当您启动 Filebeat 时,它会启动一个或多个输入,这些输入会在您为日志数据指定的位置中查找。对于 Filebeat 定位的每个日志,Filebeat 都会启动一个收割机。每个harvester 读取单个日志以获取新内容并将新日志数据发送到libbeat,libbeat 聚合事件并将聚合数据发送到您为Filebeat 配置的输出
FileBeat安装
前提:
部署运行Elasticsearch和Kibana
需要 Elasticsearch 来存储和搜索数据,需要 Kibana 来可视化和管理数据
1、安装:
在所有需要监控的服务器上安装Filebeat
下载页面:https://www.elastic.co/cn/downloads/beats/filebeat
Linux:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.2-linux-x86_64.tar.gz
tar xzvf filebeat-7.17.2-linux-x86_64.tar.gz2、连接到Elastic Stack
设置Filebeat连接到Elasticsearch和Kibana
3、收集日志数据
使用 Filebeat 收集日志数据的方法有多种
①:数据收集模块——简化常见日志格式的收集、解析和可视化
②:ECS 记录器 — 将应用程序日志结构化和格式化为 ECS 兼容的 JSON
③:手动 Filebeat 配置,Edit the filebeat.yml configuration file
4、后台运行:sudo ./filebeat -e -c filebeat.yml
FileBeat配置
inputs
paths:必选项,读取文件的路径,基于glob匹配语法
enabled:是否启用该模块
exclude_lines:排除匹配列表中的正则表达式
include_lines:包含匹配列表中的正则表达式
exclude_files:排除的文件,匹配正则表达式的列表
fields:可选的附加字段。这些字段可以自由选择,添加附加信息到抓取的日志文件进行过滤
multiline.pattern:多行合并匹配规则,匹配正则表达式
multiline.match:匹配可以设置为“after”或“before”。它用于定义是否应该将行追加到模式中在之前或之后匹配的,或者只要模式没有基于negate匹配。注意:在Logstash中,After等同于previous, before等同于next.
multiline.negate:定义模式下的模式是否应该被否定。默认为false。这个配置有点绕,其实就是负负得正,如果符合上面的就配置false,否则就配置true
FileBeat将日志直接写到Elasticsearch:
1、创建filebeat_es.yml,内容如下
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/yang/log/info.log
output:
elasticsearch:
hosts: ["localhost:9200"]2、./filebeat -e -c filebeat_es.yml
附,指定索引详细配置:
output.elasticsearch:
hosts: ["http://localhost:9200"]
indices:
- index: "warning-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
message: "WARN"
- index: "error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
message: "ERR"只指定索引:
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: "%{[fields.log_type]}-%{[agent.version]}-%{+yyyy.MM.dd}" filebeat配置去除多余的字段:
processors:
- drop_fields:
fields: ["input", "ecs", "host", "agent", "log"]需要注意: @timestamp 和 type 字段不能被删除,即使它们出现在 drop_fields 列表中
只想要message字段,可以在output中设置codec.format来决定输出的内容
# 只输出message
codec.format:
string: '%{[message]}'官方codec文档:https://www.elastic.co/guide/en/beats/filebeat/current/configuration-output-codec.html
完整配置示例:
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/work/log/info.log
- /home/work/log/error.log
processors:
- drop_fields:
fields: ["input", "ecs", "host", "agent", "log"]
output:
elasticsearch:
hosts: ["localhost:9200"]
username: "xxx"
password: "xxx"
index: "mib_tvb_content_log"
codec.format:
string: '%{[message]}'
setup.ilm.enabled: false
setup.template.name: "mib_tvb_content_log"
setup.template.pattern: "mib_tvb_content_log-*"
https://www.elastic.co/guide/en/beats/filebeat/current/elasticsearch-output.html
filebeat索引配置:https://www.elastic.co/guide/en/beats/filebeat/current/elasticsearch-output.html#index-option-es
filebeat详细配置:https://www.lmlphp.com/user/63156/article/item/673259/
When index lifecycle management (ILM) is enabled, the default index is "filebeat-%{[agent.version]}-%{+yyyy.MM.dd}-%{index_num}", for example, "filebeat-8.5.2-2022-11-22-000001".
Logstash
文档:https://www.elastic.co/guide/en/logstash/current/index.html
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程
Logstash 管道具有两个必需元素input和output和一个可选元素filter。输入插件使用来自源的数据,过滤器插件根据您的指定修改数据,输出插件将数据写入目标:
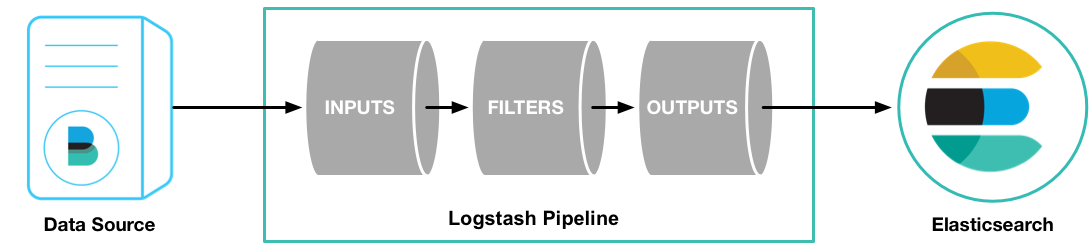
输入:
采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择,可以同时从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据
筛选:
实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便进行更强大的分析
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响
①:利用 Grok 从非结构化数据中派生出结构
②:从 IP 地址破译出地理坐标
③:将 PII 数据匿名化,完全排除敏感字段
④:简化整体处理,不受数据源、格式或架构的影响
输出:
选择存储库,导出数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例
可扩展:
Logstash 采用可插拔框架,拥有 200 多个插件。您可以将不同的输入选择、过滤器和输出选择混合搭配、精心安排,让它们在管道中和谐地运行
下载:wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.2-linux-x86_64.tar.gz
运行logstash:
bin/logstash -f logstash.conf
示例:bin/logstash -e 'input { stdin { } } output { stdout {} }' -e表示允许从命令行指定配置
启动之后,在命令行输入 hello logstash,命令行将展示:
{
"@timestamp" => 2022-07-07T09:54:21.329Z,
"message" => "hello logstash",
"host" => "yang-server",
"@version" => "1"
}
Logstash解析日志:
日志解析使用GROK(知识的图形表示,简而言之,grok 是一种将行与正则表达式匹配、将行的特定部分映射到专用字段并基于此映射执行操作的方法),解析后的数据更结构化,更易于搜索和执行查询。
Logstash在输入日志中搜索制定的GROK模式,并从日志中提取匹配的行。
http://grokdebug.herokuapp.com/ 此网站可以用来调试GROK模式
或者在kibana的Dev Tools也可以调试:
GROK语法:
GROK 过滤器的基本语法是 %{SYNTAX:SEMANTIC}。
SYNTAX 将指定每个日志文本中的模式。 SEMANTIC 将是你在已解析日志中实际给出该语法的识别标记。 换一种说法:
Logstash GROK 过滤器采用以下形式编写 %{PATTERN:FieldName}
这里,PATTERN 表示 GROK 模式,fieldname 是字段的名称,表示输出中的解析数据
如将日志解析成json数据的gork语法:
%{DATA:timestamp}\|%{DATA:thread}\|%{DATA:level}\|%{DATA:traceId}\|%{DATA:server}\|%{DATA:class}\|%{DATA:message}$日志原始数据:
2022-10-11 17:18:47.137|From UvcpsThreadFactory-consumer message-worker-3|INFO |1665479926541328pi_souhu3187htmn|uvcps-server|DataDispatcher#dispatch:47|consumer message is {"traceId":"1665479926541328pi_souhu3187htmn","media_type":"album","origin_data":"{\"cover_id\":\"3187\",\"title\":\"后天美女\",\"state\":\"0\",\"alias\":null,\"english_name\":null,\"focus\":null,\"description\":\"在第N次找工作失败之后,陈美又遇上了令人痛心的事情,大专时代暗恋的学长魏振国被她的死对头关丽莎抢走。这让陈美痛下决心,一定要改变自己平凡普通的外貌,摆脱先天不足,成为后天美女。失业又失恋的陈美陷入困境,正在这时,她中学时代好友、时尚杂志总经理秘书罗美玲仗义地挺身而\",\"category\":1,\"main_actors\":null,\"actors\":[\"何润东\",\"黄奕\",\"黄觉\",\"许绍洋\",\"钟欣凌\",\"林韦君\",\"刘仪伟\"],\"directors\":[\"张正国\"],\"create_time\":\"2010-02-11 13:42:38\",\"update_time\":\"2022-10-10 20:47:07\",\"publish_date\":\"2005-01-01 00:00:00\",\"area_name\":\"中国\",\"year\":\"2005\",\"is_finish\":0,\"tag\":[\"剧情\",\"喜剧\",\"青春\"],\"pay_status\":0,\"language\":\"普通话\",\"copyright_authorize\":null,\"licenses\":[\"广东南方新媒体股份有限公司\"],\"android_intent\":null,\"ios_intent\":null,\"content_type\":0,\"episode_count\":26,\"episode_updated\":0,\"variety_episode\":null,\"h_poster\":\"http://photocdn.tv.snmsohu.aisee.tv/img/20190313/vrs_hor_640_1552446377856_3187.jpg\",\"v_poster\":\"http://photocdn.tv.snmsohu.aisee.tv/img/20101200/vrsab3187_122SR_pic26.jpg\",\"is_excl\":0,\"cp_rate\":75,\"source_cp\":null,\"media_ext\":null,\"play_length\":null}","album_id":"3187","partnerId":"pi_souhu","type":"long"}结果:
{
"traceId": "1665479926541328pi_souhu3187htmn",
"server": "uvcps-server",
"level": "INFO ",
"thread": "From UvcpsThreadFactory-consumer message-worker-3",
"message": "consumer message is {\"traceId\":\"1665479926541328pi_souhu3187htmn\",\"media_type\":\"album\",\"origin_data\":\"{\\\"cover_id\\\":\\\"3187\\\",\\\"title\\\":\\\"后天美女\\\",\\\"state\\\":\\\"0\\\",\\\"alias\\\":null,\\\"english_name\\\":null,\\\"focus\\\":null,\\\"description\\\":\\\"在第N次找工作失败之后,陈美又遇上了令人痛心的事情,大专时代暗恋的学长魏振国被她的死对头关丽莎抢走。这让陈美痛下决心,一定要改变自己平凡普通的外貌,摆脱先天不足,成为后天美女。失业又失恋的陈美陷入困境,正在这时,她中学时代好友、时尚杂志总经理秘书罗美玲仗义地挺身而\\\",\\\"category\\\":1,\\\"main_actors\\\":null,\\\"actors\\\":[\\\"何润东\\\",\\\"黄奕\\\",\\\"黄觉\\\",\\\"许绍洋\\\",\\\"钟欣凌\\\",\\\"林韦君\\\",\\\"刘仪伟\\\"],\\\"directors\\\":[\\\"张正国\\\"],\\\"create_time\\\":\\\"2010-02-11 13:42:38\\\",\\\"update_time\\\":\\\"2022-10-10 20:47:07\\\",\\\"publish_date\\\":\\\"2005-01-01 00:00:00\\\",\\\"area_name\\\":\\\"中国\\\",\\\"year\\\":\\\"2005\\\",\\\"is_finish\\\":0,\\\"tag\\\":[\\\"剧情\\\",\\\"喜剧\\\",\\\"青春\\\"],\\\"pay_status\\\":0,\\\"language\\\":\\\"普通话\\\",\\\"copyright_authorize\\\":null,\\\"licenses\\\":[\\\"广东南方新媒体股份有限公司\\\"],\\\"android_intent\\\":null,\\\"ios_intent\\\":null,\\\"content_type\\\":0,\\\"episode_count\\\":26,\\\"episode_updated\\\":0,\\\"variety_episode\\\":null,\\\"h_poster\\\":\\\"http://photocdn.tv.snmsohu.aisee.tv/img/20190313/vrs_hor_640_1552446377856_3187.jpg\\\",\\\"v_poster\\\":\\\"http://photocdn.tv.snmsohu.aisee.tv/img/20101200/vrsab3187_122SR_pic26.jpg\\\",\\\"is_excl\\\":0,\\\"cp_rate\\\":75,\\\"source_cp\\\":null,\\\"media_ext\\\":null,\\\"play_length\\\":null}\",\"album_id\":\"3187\",\"partnerId\":\"pi_souhu\",\"type\":\"long\"}",
"class": "DataDispatcher#dispatch:47",
"timestamp": "2022-10-11 17:18:47.137"
} 
logstash配置:https://www.elastic.co/guide/en/logstash/current/event-dependent-configuration.html
filebeat->logstash:
filebeat.yml:
filebeat.inputs:
- type: log
paths:
- /path/to/file/logstash-tutorial.log
output.logstash:
hosts: ["localhost:5044"]启动filebeat:./filebeat -e -c filebeat.yml -d "publish"
logstash.conf:
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
filter {
grok {
match => ["message","%{DATA:timestamp}\|%{DATA:thread}\|%{DATA:level}\|%{DATA:traceId}\|%{DATA:server}\|%{DATA:class}\|%{DATA:message}$"]
overwrite => ["message"]
}
#删除无用字段
mutate {
# remove_field => "@timestamp" # 注意:%{+YYYY.MM.dd}这种时间是根根据@timestamp计算的,不要在filter中删除@timestamp
remove_field => "@version"
remove_field => "tags"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => mib_tvb_content_log-%{+YYYY.MM}
#user => "elastic"
#password => "changeme"
}
}启动logstash:bin/logstash -f config/logstash-es2.conf
注意:timestamp时间格式为:2022-10-13 10:49:47.742的情况,要修改映射字段设置格式为:yyyy-MM-dd HH:mm:ss.SSS

参考:https://juejin.cn/post/6862689962039443469
ELK Stack官网:https://www.elastic.co/cn/what-is/elk-stack
Elastic中文文档:https://www.elastic.co/guide/cn/index.html
logz.io文档:https://logz.io/learn/complete-guide-elk-stack/
END.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号