

Elasticsearch索引和搜索
一、索引:
手动创建索引:curl -XPUT 'localhost:9200/new_index'
创建索引的时候一个完整的格式应该是指定分片和副本数以及Mapping的定义,如下:



PUT my_index { "settings" : { "number_of_shards" : 5, "number_of_replicas" : 1 } "mappings": { "_doc": { "properties": { "title": { "type": "text" }, "name": { "type": "text" }, "age": { "type": "integer" }, "created": { "type": "date", "format": "strict_date_optional_time||epoch_millis" } } } } }
1、映射
1)获取目前的映射
GET my_index/_mapping?pretty
2)拓展现有的映射
PUT
如果在现有映射的基础上再设置一个新的字段映射,Elasticsearch会将两者进行合并
2、文档字段类型
1)字符串类型
当索引“last night with elasticsearch”时,默认的分析器将所有的字符转化为小写,然后将字符串分解为单词。分析过程生成了四个词条:late、night、with、elasticsearch
如果索引 latenight,默认的分析器只创建了一个此条——latenight,搜索late并不会命中,因为它不包含词条late
映射会对分析过程起到作用。可以在映射中指定许多分析的选项,指定自定义的分词器等。
3、 Elasticsearch预定义字段:
Elasticsearch提供了一些预定义字段,可以使用它们来增加新的功能,预定义字段的特点:
①:预定义的字段总是以下划线(_)开头。这些字段为文档添加新的元数据,Elasticsearch将这些元数据用于不同的特性,从存储原始的文档,到存储用于自动过期的时间戳信息
②:通常,不用部署预定义的字段,Elasticsearch会做这个事情。
如可以使用 _timestamp字段来记录文档索引的日期
③:它们揭示了字段相关的功能
如 _ttl (存活时间,time to live)字段使得Elasticsearch可以在指定的时间过后删除某些文档
预定义字段可以分为以下几种类别:
①:控制如何存储和搜索你的文档
_source在索引文档的时候,存储原始的JSON文档
_all将所有的字段一起索引
②:唯一识别文档
有些特别的字段,包含了文档索引位置的数据:_uid、_id、_type、_index
③:为文档增加新的属性
可以使用 _size来索引原始JSON内容的大小
可以使用 _timestamp来索引文档入索引的时间
使用 _ttl来告知Elasticsearch在一定时间后删除文档(实际上,将这个索引设置为过期成本更低)
④:控制文档路由到哪些分片
相关的字段是 _routing和parent
| 预定义字段 | 说明 |
| _source |
存储所有的信息,从内部来看,_source只是另一个Luceue中的存储字段。Elasticsearch将原始的JSON存储于其中,然后按需抽取字段的内容 _source字段在版本2.0之后不允许关闭,因为很多功能都依赖于_source字段 |
| _all |
索引全部的信息,当搜索_all字段的时候,ES将在不考虑是哪个字段匹配成功的情况下,返回命中的文档。 从URI上运行搜索时如果不指定字段名称,系统默认情况下将会在_all上搜索,如: curl 'localhost:9200/index_name/type_name1/_search?q=xxx&pretty' 如果总是在特定的字段上搜索,可以通过设置enabled为false来关闭_all,这样设置会使得索引的规模变得更小,而且索引操作变得更快: "events":{"_all":{"enabled":false}} |
| _uid | _uid字段是由 _id 和_type字段组成,用于识别同一个索引中的具体某篇文档 |
| _id |
该字段没有被索引,也没有被存储,如果搜索它,实际上使用的是 _uid 索引的文档ID 索引的时候自己指定 依靠Elasticsearch生成ID |
| _type | 该字段是被索引的,并且生成一个单一的词条。Elasticsearch用它来过滤指定类型的文档。也可以搜索这个字段 |
操作相关预定义字段:
| _search | 代表搜索操作,后面跟着搜索条件 |
| _setting | 查询或修改索引的设置 |
| _mapping | 查询或更改索引字段的映射 |
4、更新现有文档
更新流程:
①:检索现有的文档,必须打开_source字段
②:进行指定的修改
③:删除旧的文档,并在其原有位置上索引新的文档(包括修改的内容)
5、删除数据
TODO
6、索引数据
写索引只能写在主分片上,然后同步到副本分片。
写索引分片的选择:
shard = hash(routing) % number_of_primary_shards
routing是一个可变值,默认是文档的_id,也可以设置成一个自定义的值。
因此在创建索引的时候就要确定好主分片的数量并且永远不会改变这个数量:否则数量变化了,那么之前存量数据的路由值都会失效,文档再也找不到了
在一个写请求被发送到某个节点后,该节点即为协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。
bulk API
二、搜索:
1、在哪里搜索
①:在多个类型中搜索
指定类型:curl 'localhost:9200/index_name/type_name1,type_name2/_search?q=xxx&pretty'
在索引下的全部类型:curl 'localhost:9200/index_name/_search?q=xxx&pretty'
②:在多个索引中搜索
指定索引:curl 'localhost:9200/index_name1,index_name2/_search?q=xxx&pretty'
在所有索引:curl 'localhost:9200/_search?q=xxx&pretty'
全部索引的一个单独类型中:curl 'localhost:9200/_all/type_name/_search?q=xxx&pretty'
③:轻量搜索
轻量的查询字符串方式,要求在查询字符串中传递所有的参数
如下这些参数可以使用统一资源标识符在搜索操作中传递
如查询在my_type类型中tweet字段包含elasticsearch单词的所有文档:
curl -X GET "localhost:9200/_all/my_type/_search?q=tweet:elasticsearch&pretty"
查询在 name 字段中包含 john 并且在 tweet 字段中包含 mary 的文档
curl -X GET "localhost:9200/_search?q=+name:john++tweet:mary&pretty"
+ 前缀表示必须与查询条件匹配。类似地, - 前缀表示一定不与查询条件匹配。没有 + 或者 - 的所有其他条件都是可选的——匹配的越多,文档就越相关
| 参数 | 说明 |
|---|---|
| q | 此参数用于指定查询字符串 |
| pretty | 默认情况下,API返回的JSON对象忽略换行符,在请求(Request)中加上pretty参数,强制ElasticSearch引擎在响应(Response)中加上换行符,使返回的结果集JSON可读 |
| fields | 此参数用于在响应中选择返回字段 |
| sort | 可以通过使用这个参数获得排序结果,这个参数的可能值是fieldName,fieldName:asc和fieldname:desc |
| from | 从命中的索引开始返回。默认值为0 |
| size | 它表示要返回的命中数。默认值为10 |
| lenient | 基于格式的错误可以通过将此参数设置为true来忽略。默认情况下为false。 |
| timeout | 使用此参数限定搜索时间,响应只包含指定时间内的匹配。默认情况下,无超时。 |
| terminate_after | 可以将响应限制为每个分片的指定数量的文档,当到达这个数量以后,查询将提前终止。 默认情况下不设置terminate_after。 |
④:请求体搜索
在请求体中使用JSON格式和更丰富的查询表达式(DSL)作为搜索语言
2、回复的内容
{ "took" : 7, 请求耗时多久 "timed_out" : false, 请求是否超时 "_shards" : { "total" : 10, 查询中参与分片的总数 "successful" : 10, 多少分片查询成功 "skipped" : 0, "failed" : 0 多少分片查询失败 }, "hits" : { 所有匹配文档的统计数据 "total" : { "value" : 2, 该搜索请求所有匹配结果的数量 "relation" : "eq" }, "max_score" : 1.0, 匹配文档的最高得分,得分默认是通过TF-IDF(词频-逆文档频率)算法进行计算的 "hits" : [ 命中关键词的文档数组 { "_index" : "mib_tv_appstore_app_info_test@1-000001", 结果文档的索引 "_type" : "_doc", 结果文档的Elasticsearch类型 "_id" : "11", 结果文档ID "_score" : 1.0, 结果的相关性得分 "_source" : { Elasticsearch使用_sourcec存储原始的JSON文档,当没有指定返回哪些字段时会展示_source字段 "_class" : "com.xiaomi.mitv.appstore.search.document.AppInfo", "id" : 11, "app_name" : "视频头条", "update_time" : 1648798088043 } }, { "_index" : "mib_tv_appstore_app_info_test@1-000001", "_type" : "_doc", "_id" : "13", "_score" : 1.0, "_source" : { "id" : 12, "app_name" : "电视商店", "update_time" : 1648902052413 } } ] } }
Elasticsearch预定义字段:
| _index | 索引名称,用于在文档中存储索引的名称 |
| _type | 文档所属类型名,默认为_doc |
| _id |
文档ID,doc的主键,可以在索引的时候指定或者依靠Elasticsearch生成唯一的ID |
| _score | 得分,即相关性,在查询时ES会根据一些规则计算得分,并根据得分进行倒排。除此之外,ES支持通过Function score query在查询时自定义score的计算规则 |
| _source | 文档的原始JSON数据 |
3、搜索什么以及如何搜索
中文文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/search-in-depth.html
1、结构化搜索(Structured search)
结构化数据:也成为行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式和长度规范,主要通过关系型数据库进行存储和管理。指具有固定格式或有限长度的数据,如数据库、元数据等。对应的搜索称为结构化搜索
非结构化数据:又可称为全文数据,不定长或无固定格式,不适于由数据库二维表来表现,包括所有格式的办公文档、HTML、图片、音频视频等
是指有关探询那些具有内在结构数据的过程。比如日期、时间和数字都是结构化的:它们有精确的格式,我们可以对这些格式进行逻辑操作。比较常见的操作包括比较数字或时间的范围,或判定两个值的大小
在结构化查询中,我们得到的结果 总是 非是即否,要么存于集合之中,要么存在集合之外,对于结构化文本来说,一个值要么相等,要么不等。结构化查询不关心文件的相关度或评分;它简单的对文档包括或排除处理
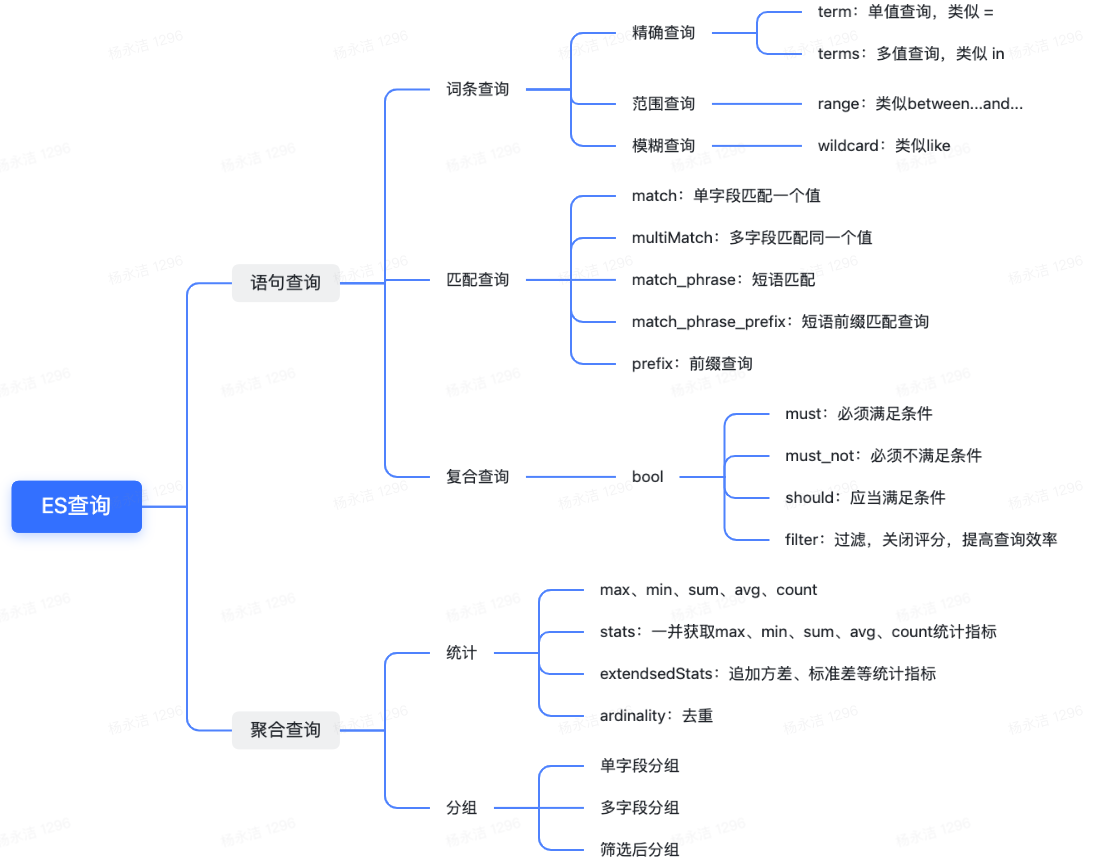
1):精确值查找
当进行精确值查找时, 会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。因此,请尽可能多的使用过滤式查询。
①:term查询
最为常用的 term 查询, 可以用它处理数字(numbers)、布尔值(Booleans)、日期(dates)以及文本(text)
term 查询会查找我们指定的精确值。作为其本身, term 查询是简单的。它接受一个字段名以及我们希望查找的数值
通常当查找一个精确值的时候,我们不希望对查询进行评分计算。只希望对文档进行包括或排除的计算,所以我们会使用 constant_score 查询以非评分模式来执行 term 查询并以一作为统一评分。
最终组合的结果是一个 constant_score 查询,它包含一个 term 查询:
curl -X GET "localhost:9200/my_store/products/_search?pretty" -H 'Content-Type: application/json' -d' { "query" : { "constant_score" : { "filter" : { "term" : { "price" : 20 } } } } } '
类似于SQL:
SELECT document FROM products WHERE price = 20;②:terms 查找多个精确值:
比如要查找某个字段的值等于 20 或 30的文档
不需要使用多个多个term查询,我们只要用单个terms查询,terms查询好比term查询的复数形式。
使用方式与term一样,只要将term字段的值改为数组即可
curl -X GET "localhost:9200/my_store/products/_search?pretty" -H 'Content-Type: application/json' -d' { "query" : { "constant_score" : { "filter" : { "terms" : { "price" : [20, 30] } } } } } '
注意:term 和 terms 是 包含(contains) 操作,而非 等值(equals) (判断)
如果我们有一个 term(词项)过滤器 { "term" : { "tags" : "search" } } ,它会与以下两个文档 同时 匹配:
{ "tags" : ["search"] }
{ "tags" : ["search", "open_source"] }
尽管第二个文档包含除 search 以外的其他词,它还是被匹配并作为结果返回
2):复合过滤器
如果查询条件中有多个字段,并且需要组合作为条件,如 and 或 or
这种情况下,我们需要 bool (布尔)过滤器。 这是个 复合过滤器(compound filter) ,它可以接受多个其他过滤器作为参数,并将这些过滤器结合成各式各样的布尔(逻辑)组合
一个 bool 过滤器由以下三部分组成:
{
"bool" : {
"must" : [], 所有的语句都必须匹配,与AND等价
"filter" : [], 所有的语句都必须匹配,与AND等价,与must的区别是filter不以评分、过滤模式来进行。
"should" : [], 至少有一个语句要匹配,与OR等价
"must_not" : [], 所有的语句都不能匹配,与NOT等价
}
}使用示例:
curl -X GET "localhost:9200/my_store/products/_search?pretty" -H 'Content-Type: application/json' -d' { "query" : { "filtered" : { "filter" : { "bool" : { "should" : [ { "term" : {"price" : 20}}, { "term" : {"productID" : "XHDK-A-1293-#fJ3"}} ], "must_not" : { "term" : {"price" : 30} } } } } } } '
bool查询包括:
must、filter、should、must_not
must和filter:
must:返回的文档必须满足must子句的条件,并且参与计算分值
filter:返回的文档必须满足filter子句的条件。但是跟Must不一样的是,不会计算分值, 并且可以使用缓存
must和filter是一样的。区别是场景不一样。如果结果需要算分就使用must,否则可以考虑使用filter,使查询更高效
3)范围
Elasticsearch 有 range 查询,可以用它来查找处于某个范围内的文档
range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:
gt: > 大于(greater than)
lt: < 小于(less than)
gte: >= 大于或等于(greater than or equal to)
lte: <= 小于或等于(less than or equal to)
curl -X GET "localhost:9200/my_store/products/_search?pretty" -H 'Content-Type: application/json' -d' { "query" : { "constant_score" : { "filter" : { "range" : { "price" : { "gte" : 20, "lt" : 40 } } } } } } '
4)处理NULL值
①:存在查询 exists
这个查询会返回那些在指定字段有任何值(字段存在,且值不为null)的文档
curl -X GET "localhost:9200/my_index/posts/_search?pretty" -H 'Content-Type: application/json' -d' { "query" : { "constant_score" : { "filter" : { "exists" : { "field" : "tags" } } } } } '
②:缺失查询 missing
与exists相反,返回某个特定无值(字段不存在或为null)字段的文档
2、全文搜索(full-text search)
即怎样在全文字段中搜索到最相关的文档。
全文搜索两个最重要的方面是:
①:相关性(Relevance)
它是评价查询与其结果间的相关程度,并根据这种相关程度对结果排名的一种能力,这种计算方式可以是 TF/IDF 方法、地理位置邻近、模糊相似,或其他的某些算法
②:分析(Analysis)
它是将文本块转换为有区别的、规范化的 token 的一个过程,目的是为了(a)创建倒排索引以及(b)查询倒排索引
1)匹配查询(布尔匹配)
匹配查询 match 是个核心查询,无论需要查询什么字段,match查询都应该会是首选的查询方式。
match查询是一个高级的全文查询,它既能处理全文字段,又能处理精确字段。
匹配查询共有三种类型,分别是布尔(bool)、短语(phrase)和短语前缀(phrase_prefix)
①:单个词查询
match查询搜索全文字段中的单个词示例:
curl -X GET "localhost:9200/my_index/my_type/_search?pretty" -H 'Content-Type: application/json' -d' { "query": { "match": { "title": "QUICK!" } } } '
Elasticsearch执行上面这个 match 查询的步骤是:
①:检查字段类型
标题 title 字段是一个 string 类型( analyzed )已分析的全文字段,这意味着查询字符串本身也应该被分析
②:分析查询字符串
将查询的字符串 QUICK! 传入标准分析器中,输出的结果是单个项 quick 。因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询
③:查找匹配文档
用 term 查询在倒排索引中查找 quick 然后获取一组包含该项的文档,本例的结果是文档:1、2 和 3
④:为每个文档评分
用 term 查询计算每个文档相关度评分 _score ,这是种将词频(term frequency,即词 quick 在相关文档的 title 字段中出现的频率)和反向文档频率(inverse document frequency,即词 quick 在所有文档的 title 字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式
②:多词查询
curl -X GET "localhost:9200/my_index/my_type/_search?pretty" -H 'Content-Type: application/json' -d' { "query": { "match": { "title": "BROWN DOG!" } } } '
一次搜索多个词,match 查询必须查找两个词( ["brown","dog"] ),它在内部实际上先执行两次 term 查询,然后将两次查询的结果合并作为最终结果输出。为了做到这点,它将两个 term 查询包入一个 bool 查询中。多个词之间的匹配规则为 OR
即任何文档只要 title 字段里包含 指定词项中的至少一个词 就能匹配,被匹配的词项越多,文档就越相关
①:多词查询提高精度:
用 任意 查询词项匹配文档可能会导致结果中出现不相关的长尾。这是种散弹式搜索。可能我们只想搜索包含 所有 词项的文档,也就是说,不去匹配 brown OR dog ,而通过匹配 brown AND dog 找到所有文档。
match 查询还可以接受 operator 操作符作为输入参数,默认情况下该操作符是 or 。我们可以将它修改成 and 让所有指定词项都必须匹配
curl -X GET "localhost:9200/my_index/my_type/_search?pretty" -H 'Content-Type: application/json' -d' { "query": { "match": { "title": { "query": "BROWN DOG!", "operator": "and" } } } } '
②:多词查询控制精度
match 查询支持 minimum_should_match 最小匹配参数,这让我们可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数
③:如何使用布尔匹配
多词match查询只是简单地将生成的term查询包裹在一个bool查询中。
①:如果使用默认的 or 操作符,每个term 查询都被当做 shoud 语句,所以至少要匹配一条语句,以下两个查询是等价的:
{ "match": { "title": "brown fox"} } 等价于: { "bool": { "should": [ { "term": { "title": "brown" }}, { "term": { "title": "fox" }} ] } }
②:如果使用 and 操作符,所有的term查询都被当做must语句,所以所有语句都必须要匹配,以下两个查询是等价的:
{ "match": { "title": { "query": "brown fox", "operator": "and" } } } 等价于: { "bool": { "must": [ { "term": { "title": "brown" }}, { "term": { "title": "fox" }} ] } }
③:如果指定参数minimum_should_match ,它可以通过 bool 查询直接传递,使以下两个查询等价:
{ "match": { "title": { "query": "quick brown fox", "minimum_should_match": "75%" } } } 等价于: { "bool": { "should": [ { "term": { "title": "brown" }}, { "term": { "title": "fox" }}, { "term": { "title": "quick" }} ], "minimum_should_match": 2 // 因为只有三条语句,match 查询的参数 minimum_should_match 值 75% 会被截断成 2 。即三条 should 语句中至少有两条必须匹配 } }
④:查询语句提升权重
我们知道should语句匹配的越多,则表示文档的相关度越高。
如果我们想提高包含词 word1 的权重,并且包含 word2的权重比包含 word1的权重更高,该怎么办?
我们可以通过指定 boost 来控制任何查询语句的相对的权重,boost的默认值为1,大于1会提升一个语句的相对权重。boost值越高,查询的评分 _score越高。
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d' { "query": { "bool": { "must": { "match": { // 使用默认的 boost 值 1 "content": { "query": "full text search", "operator": "and" } } }, "should": [ { "match": { "content": { "query": "Elasticsearch", "boost": 3 // 这条语句更为重要,因为它有最高的 boost 值 } }}, { "match": { "content": { "query": "Lucene", "boost": 2 // 这条语句比使用默认值的更重要,但它的重要性不及 Elasticsearch 语句 } }} ] } } } '
3、近似匹配(短语匹配)
1)短语匹配(精确短语匹配)
当想找到彼此临近搜索词的查询方法时,就可以使用 match_phrase查询
类似 match 查询, match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索,但只保留那些包含 全部 搜索词项,且 位置 与搜索词项相同的文档。
即,结果文档必须匹配短语中的所有分词,并且保证各个分词的相对位置相同,才能匹配。
如:文档为 hello world elasticsearch,短语匹配查询必须为hello、hello world、hello world elasticsearch或者 world elasticsearch时才能匹配到这条文档,查询条件为hello elaticsearch则不能匹配。
2)灵活短语匹配
精确短语匹配 或许是过于严格了。也许我们想要包含 “hello world elasticsearch” 的文档也能够匹配 “hello elaticsearch”
可以通过使用slop参数将灵活度引入短语匹配中。 slop参数告诉match_phrase查询此条相隔多远时仍然能将文档视为匹配。相隔多远的意思是为了让查询和文档匹配需要移动查询此条多少次
4、部分匹配(前缀匹配)
截至目前的查询都是针对整个词的操作。为了能匹配,只能查找倒排索引中存在的词,最小的单元为单个完整词
但是,如果想匹配部分而不是全部的词怎么办?类似于RDBMS关系型数据库中的模糊查询。
部分匹配允许用户指定查询词的一部分并找出所有包含这一部分片段的词
在以下场景,部分匹配会比较有用:
①:匹配邮编、产品序列号或其他 not_analyzed 未分析值,这些值可以是以某个特定前缀开始,也可以是与某种模式匹配的,甚至可以是与某个正则式相匹配的
②:输入即搜索(search-as-you-type) ——在用户键入搜索词过程的同时就呈现最可能的结果
③:匹配如德语或荷兰语这样有长组合词的语言,如: Weltgesundheitsorganisation (世界卫生组织,英文 World Health Organization)
1)prefix 前缀查询
为了找到所有以 W1 开始的邮编,可以使用简单的 prefix 查询:
curl -X GET "localhost:9200/my_index/address/_search?pretty" -H 'Content-Type: application/json' -d' { "query": { "prefix": { "postcode": "W1" } } } '
prefix 查询是一个词级别的底层的查询,它不会在搜索之前分析查询字符串,它假定传入前缀就正是要查找的前缀。
默认状态下, prefix 查询不做相关度评分计算,它只是将所有匹配的文档返回,并为每条结果赋予评分值 1 。它的行为更像是过滤器而不是查询
注意:前缀越短所需访问的词越多。如果我们要以 W 作为前缀而不是 W1 ,那么就可能需要做千万次的匹配。
因此,prefix 查询或过滤对于一些特定的匹配是有效的,但使用方式还是应当注意。当字段中词的集合很小时,可以放心使用,但是它的伸缩性并不好,会对我们的集群带来很多压力。可以使用较长的前缀来限制这种影响,减少需要访问的量。
2)通配符与正则表达式查询
①:与 prefix 前缀查询的特性类似, wildcard 通配符查询也是一种底层基于词的查询,与前缀查询不同的是它允许指定匹配的正则式。它使用标准的 shell 通配符查询: ? 匹配任意字符, * 匹配 0 或多个字符
GET mib_tvb_content_log_preview/_search
{
"query": {
"wildcard": {
"message":"*44185008"
}
}
}②:设想如果现在只想匹配 W 区域的所有邮编,前缀匹配也会包括以 WC 开头的所有邮编,与通配符匹配碰到的问题类似,如果想匹配只以 W 开始并跟随一个数字的所有邮编, regexp 正则式查询允许写出这样更复杂的模式:
GET /my_index/address/_search
{
"query": {
"regexp": {
"postcode": "W[0-9].+" // 这个正则表达式要求词必须以 W 开头,紧跟 0 至 9 之间的任何一个数字,然后接一或多个其他字符
}
}
}
3)短语匹配前缀查询(查询时输入即搜索)
用户已经渐渐习惯在输完查询内容之前,就能为他们展现搜索结果,这就是所谓的 即时搜索(instant search) 或 输入即搜索(search-as-you-type) 。不仅用户能在更短的时间内得到搜索结果,我们也能引导用户搜索索引中真实存在的结果。
在 短语匹配 中,我们引入了 match_phrase 短语匹配查询,它匹配相对顺序一致的所有指定词语,对于查询时的输入即搜索,可以使用 match_phrase 的一种特殊形式, match_phrase_prefix 查询。
match_phrase_prefix 查询的行为与 match_phrase 查询一致,不同的是它将查询字符串的最后一个词作为前缀使用(注意:只有查询字符串的最后一个词才能当作前缀使用)
与 match_phrase 一样,它也可以接受 slop 参数(参照 slop )让相对词序位置不那么严格:
注意:短语前缀查询与prefix查询一样存在严重的资源消耗问题,如前缀 a 可能会匹配成千上万的词,这不仅会消耗很多系统资源,而且结果的用处也不大。
可以通过设置 max_expansions 参数限制前缀扩展的影响,一个合理的值可能是50。
参数 max_expansions 控制着可以与前缀匹配的词的数量,它会先查找第一个与前缀 bl 匹配的词,然后依次查找搜集与之匹配的词(按字母顺序),直到没有更多可匹配的词或当数量超过 max_expansions 时结束。
不要忘记,当用户每多输入一个字符时,这个查询又会执行一遍,所以查询需要快,如果第一个结果集不是用户想要的,他们会继续输入直到能搜出满意的结果为止。
一个完整的 match_phrase_prefix 查询语句应该是这样:
{ "match_phrase_prefix" : { "brand" : { "query": "johnnie walker bl", "max_expansions": 50 } } }
collapse
折叠,实现sql中的distinct功能:
GET index_name/_search
{
"query": {
"wildcard": {
"traceId":"*3187htmn"
}
},
"collapse": {
"field": "traceId.keyword"
}
}
分页查询,排序:
GET mib_tvb_content_log/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 100,
"sort":{
"timestamp":{
"order":"desc"
}
}
}fields指定字段返回
"_source":false 不返回 _source
GET mib_tvb_content_log/_search
{
"query": {
"match_all": {}
},
"fields": [
"timestamp","message"
],
"_source":false
}只返回 _source中指定的timestamp和message字段:
"_source":[
"timestamp","message"
],也可用include包含和exclude排除某些字段:
"_source": {
"includes": ["tel.*","user.*"],
"excludes": [ "*.description" ]
},
查询总数
默认的查询总数为10000,当记录总数超过这个阀值之后,显示的total只为10000,要想查询全部记录,需使用track_total_hits
GET index_name/_search
{
"query": {
"match_all": {}
},
"track_total_hits":true
}
参考:https://mp.weixin.qq.com/s/pS33v4DdfhEYt8xmqly90g
END.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!