
Go基础学习
官方文档:https://golang.google.cn/doc/
中文文档:https://www.topgoer.cn/docs/golang
Go 语言被设计成一门应用于搭载 Web 服务器,存储集群或类似用途的巨型中央服务器的系统编程语言。
对于高性能分布式系统领域而言,Go 语言无疑比大多数其它语言有着更高的开发效率。它提供了海量并行的支持,这对于游戏服务端的开发而言是再好不过了
go语言的优点:
自带gc,自动垃圾回收
静态编译,编译好后,扔服务器直接运行
简单的思想,没有继承,多态,类等
丰富的库和详细的开发文档
速度快。几乎和C一样快
go适合做什么:
服务端开发
分布式系统,微服务
云平台
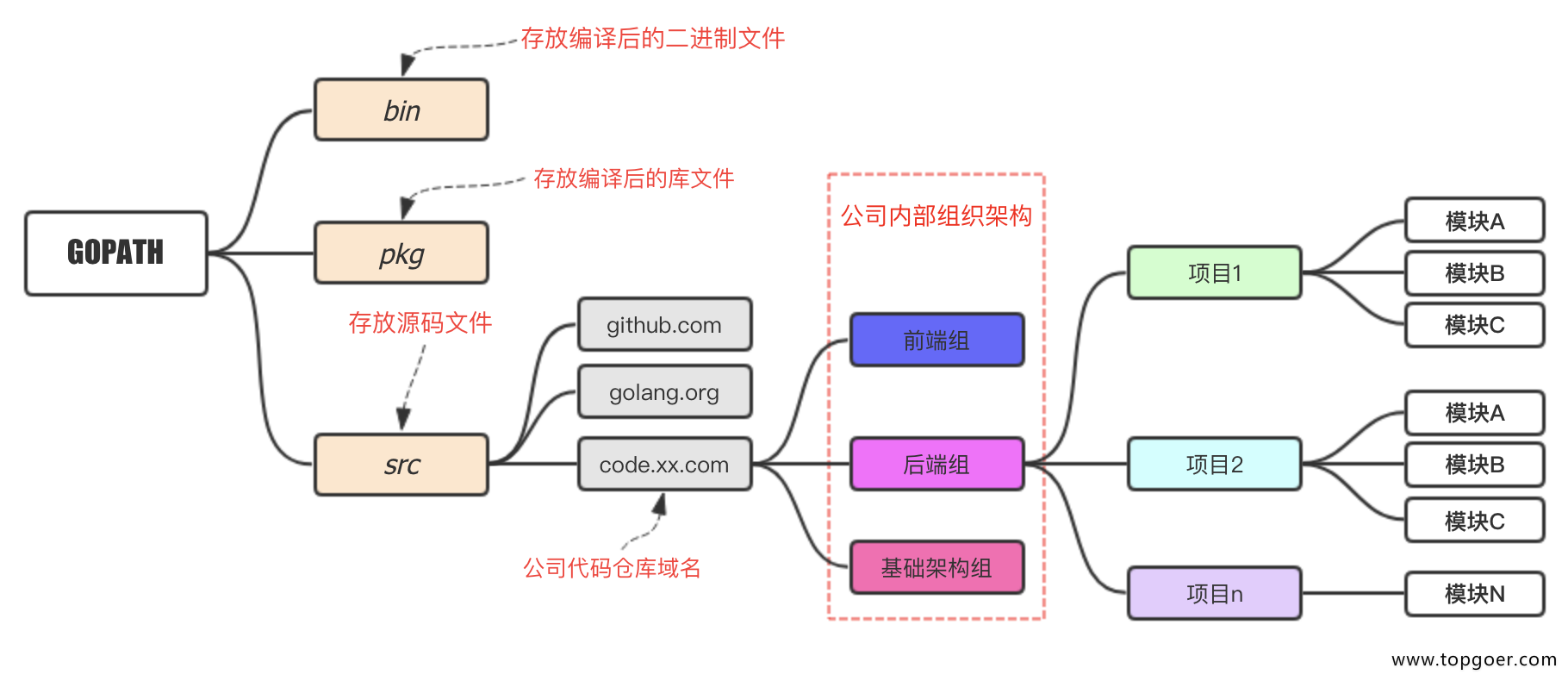
GOROOT和GOPATH的区别:
GOROOT是Go的安装路径
GOPATH:
GOPATH是一个环境变量,用来表明你写的go项目的存放路径。
GOPATH路径最好只设置一个,所有的项目代码都放到GOPATH的src目录下。
在进行Go语言开发的时候,我们的代码总是会保存在$GOPATH/src目录下。在工程经过go build、go install或go get等指令后,会将下载的第三方包源代码文件放在$GOPATH/src目录下, 产生的二进制可执行文件放在 $GOPATH/bin目录下,生成的中间缓存文件会被保存在 $GOPATH/pkg 下
(类似于maven仓库+工程目录)
1)存放sdk以外的第三方类库
2)自己收藏的可复用的代码
3)自己项目的源代码
# 配置GOROOT export GOROOT=/usr/local/go # 配置GOPATH export GOPATH=/Users/yangyongjie/GoProjects # 配置GOBIN export GOBIN=$GOPATH/bin # 配置PATH,mac多个之间:分隔 export PATH=$PATH:$GOROOT/bin:$GOBIN
编辑 ~/.bash_profile 或者 /etc/profile 添加以上配置,保存然后执行 source ~/.bash_profile 或 source /etc/profile 使配置立即生效即可
Go基础:
Go语言中的函数传参都是值拷贝,当我们想要修改某个变量的时候,我们可以创建一个指向该变量地址的指针变量。传递数据使用指针,而无须拷贝数据。类型指针不能进行偏移和运算。
Go语言中的指针操作非常简单,只需要记住两个符号:&(取地址)和*(根据地址取值)
1、环境安装
安装包下载地址为:https://golang.org/dl/。如果打不开可以使用这个地址:https://golang.google.cn/dl/。
截止2021年底,建议下载安装Go 1.16.12 版本
2、HelloWorld
package main // 包声明,package main表示一个可独立执行的程序,每个Go应用程序都包含一个名为main的包 import "fmt" // 引入包,引入多个包使用()括起来,引用其他go文件,也需要导入其所在包名 func main() { // 程序开始执行的函数,每一个可执行的程序必须包含main函数。注意,{ 不能单独放在一行 /* 这是我的第一个简单的程序 */ fmt.Println("Hello, World!") }
执行:
1)右键run即可。
2)或者将上面代码保存为hello.go,然后执行 go run hello.go
3)使用 go build命令生成二进制文件,然后执行二进制文件。 go build hello.go ./hello
Go语法:
命名:
1)文件命名
小写单词,下划线分割各个单词
2)包名称(全小写,与Java包命名规范一致)
保持包的名字和目录一致,尽量采取有意义的包名,简短,有意义,尽量和标准库不要冲突。
包名应该为小写单词,不要使用下划线或者混合大小写,不能包含-等特殊符号
3)结构体、变量、函数、方法、接口等的命名(驼峰,首字母大小写定义访问权限)
①:需要使用驼峰命名法,且不能出现下划线
②:根据首字母的大小写来确定可以访问的权限。无论是方法名、常量、变量名还是结构体、接口的名称,如果首字母大写,则可以被其他的包访问;如果首字母小写,则只能在本包中使用
可以简单的理解成:首字母大写是公有的,包外可访问;首字母小写是私有的,仅在包内可访问
③:变量为bool型,则名称应以 Is,Has、Can、Allow等开头
接口以 er 作为后缀
常量均需使用全部大写字母组成,并使用下划线分词
单元测试文件名命名规范为 example_test.go 测试用例的函数名称必须以 Test 开头
自定义包:
我们创建go文件时,可以自定义其包名,不过为了便于维护,建议与文件夹名称一致
一个包中可以有任意多个文件,文件的名字也没有任何规定(但后缀必须是 .go)
一个文件夹下的所有源码文件只能属于同一个包,同样属于同一个包的源码文件不能放在多个文件夹下
要调用其他go文件中的函数,必须导入其所在的包
对引用自定义包需要注意以下几点:
①:如果项目的目录不在 GOPATH 环境变量中,则需要把项目移到 GOPATH 所在的目录中,或者将项目所在的目录设置到 GOPATH 环境变量中,否则无法完成编译
②:使用 import 语句导入包时,使用的是包所属文件夹的名称
③:包中的函数要在外部被调用的话,则函数名第一个字母要大写,否则无法在外部调用
④:自定义包的包名不必与其所在文件夹的名称保持一致,但为了便于维护,建议保持一致
⑤:调用自定义包时使用 包名 . 函数名 的方式,如上例:demo.PrintStr()
1、注释
// 单行注释
/* 多行注释 */
2、数据类型
| 序号 | 类型和描述 |
|---|---|
| 1 | 布尔型 布尔型的值只可以是常量 true 或者 false。一个简单的例子:var b bool = true。 |
| 2 |
数字类型 Go语言中没有字符类型,字符只是整数的特殊用例。因为用于表示字符的byte和rune(字符默认类型)类型分别等于int8和int32。Go中字符用单引号('')包围 |
| 3 |
字符串类型: 字符串可以使用+拼接,fmt.Sprintf 格式化字符串并赋值给新串 |
| 4 | 派生类型: 包括:
|
值类型:
bool int(32 or 64), int8, int16, int32, int64 uint(32 or 64), uint8(byte), uint16, uint32, uint64 float32, float64 string complex64, complex128 array -- 固定长度的数组
引用类型:
slice -- 序列数组(最常用) map -- 映射 chan -- 管道
数字类型:
| 类型和描述 | 大小(字节) | 对应Java类型 |
|---|---|---|
| uint8 无符号 8 位整型 (0 到 255) |
1 | - |
| uint16 无符号 16 位整型 (0 到 65535) |
2 | - |
| uint32 无符号 32 位整型 (0 到 4294967295) |
4 | - |
| uint64 无符号 64 位整型 (0 到 18446744073709551615) |
8 | - |
| int8 有符号 8 位整型 (-128 到 127) |
1 | byte |
| int16 有符号 16 位整型 (-32768 到 32767) |
2 | short |
| int32 有符号 32 位整型 (-2147483648 到 2147483647) |
4 | int |
| int64 有符号 64 位整型 (-9223372036854775808 到 9223372036854775807) |
8 | long |
浮点型:
| 类型和描述 |
|---|
| float32 IEEE-754 32位浮点型数 |
| float64 IEEE-754 64位浮点型数 |
| complex64 32 位实数和虚数 |
| complex128 64 位实数和虚数 |
其他类型:
| 类型和描述 |
|---|
| byte type byte = uint8 |
| rune type rune = int32 |
| uint 32 或 64 位 |
| int 与 uint 一样大小 |
| uintptr 无符号整型,用于存放一个指针 |
Go类型转换:
type_name(expression)
type_name 为要转换成的类型,expression 为表达式
Go类型断言
类型断言(Type Assertion)是一个使用在接口值上的操作,用于检查接口类型变量所持有的值是否实现了期望的接口或者具体的类型
格式:value, ok := x.(T)
其中,x 表示一个接口的类型,T 表示一个具体的类型(也可为接口类型)
该断言表达式会返回 x 的值(也就是 value)和一个布尔值(也就是 ok),可根据该布尔值判断 x 是否为 T 类型:
如果 T 是具体某个类型,类型断言会检查 x 的动态类型是否等于具体类型 T。如果检查成功,类型断言返回的结果是 x 的动态值,其类型是 T。
如果 T 是接口类型,类型断言会检查 x 的动态类型是否满足 T。如果检查成功,x 的动态值不会被提取,返回值是一个类型为 T 的接口值。
无论 T 是什么类型,如果 x 是 nil 接口值,类型断言都会失败。
3、变量
Go 语言变量名由字母、数字、下划线组成,其中首个字符不能为数字。
声明变量一般使用var关键字:var identifier1,identifier2 type
声明变量没有初始化值,则为系统默认设置的值:
数值类型(包括complex64/128)默认值为 0
布尔类型默认值为 false
字符串为默认值为 ""(空字符串)
以下几种类型为 nil:
var a *int
var b []int
var a map[string] int
var c chan int
var a func(string) int
var b error // error 是接口
还可以使用 := 直接声明并初始化变量,编译器根据值自动判断类型(使用变量的首选方式)。如: identifier := 123
不过:= 这种方式只能被用在函数体内,而不能用于全局变量的声明和赋值。
如果变量已经使用 var 声明过了,再使用 := 声明变量,就产生编译错误
多变量声明:
package main
var x, y int
var ( // 这种因式分解关键字的写法一般用于声明全局变量
a int
b bool
)
var c, d int = 1, 2
var e, f = 123, "hello"
//这种不带声明格式的只能在函数体中出现
//g, h := 123, "hello"
func main(){
g, h := 123, "hello"
println(x, y, a, b, c, d, e, f, g, h)
}
值类型和引用类型:
值类型:所有像 int、float、bool 和 string 这些基本类型都属于值类型,使用这些类型的变量直接指向存在内存中的值,
当使用等号 = 将一个变量的值赋值给另一个变量时,如:j = i,实际上是在内存中将 i 的值进行了拷贝
可以通过 &i 来获取变量 i 的内存地址,例如:0xf840000040(每次的地址都可能不一样)。值类型的变量的值存储在栈中
引用类型:一个引用类型的变量 r1 存储的是 r1 的值所在的内存地址(数字),或内存地址中第一个字所在的位置。
这个内存地址称之为指针,这个指针实际上也被存在另外的某一个值中
当使用赋值语句 r2 = r1 时,只有引用(地址)被复制。如果 r1 的值被改变了,那么这个值的所有引用都会指向被修改后的内容
4、常量
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
常量不能用 := 语法声明
常量的定义格式:
const identifier [type] = value
可以省略类型说明符 [type],因为编译器可以根据变量的值来推断其类型。
显式类型定义: const b string = "abc"
隐式类型定义: const b = "abc"
多个相同类型的声明可以简写为:
const c_name1, c_name2 = value1, value2
const x string = "abc" const y = "abc" fmt.Println(x, y) // 多个常量也可以一起声明,常量还可以用作枚举: const ( Unknown = 0 Female = 1 Male = 2 )
iota,特殊常量,可以认为是一个可以被编译器修改的常量。
iota 在 const关键字出现时将被重置为 0(const 内部的第一行之前),const 中每新增一行常量声明将使 iota 计数一次(iota 可理解为 const 语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
5、运算符
Go语言没有三目运算符
1)算术运算符
下表列出了所有Go语言的算术运算符。假定 A 值为 10,B 值为 20。
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 相加 | A + B 输出结果 30 |
| - | 相减 | A - B 输出结果 -10 |
| * | 相乘 | A * B 输出结果 200 |
| / | 相除 | B / A 输出结果 2 |
| % | 求余 | B % A 输出结果 0 |
| ++ | 自增 | A++ 输出结果 11 |
| -- | 自减 | A-- 输出结果 9 |
2)关系运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 | (A == B) 为 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False。 | (A != B) 为 True |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 | (A > B) 为 False |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False。 | (A < B) 为 True |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 | (A >= B) 为 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 | (A <= B) 为 True |
3)逻辑运算符
下表列出了所有Go语言的逻辑运算符。假定 A 值为 True,B 值为 False。
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 | (A && B) 为 False |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 | (A || B) 为 True |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 | !(A && B) 为 True |
4)位运算符
Go 语言支持的位运算符如下表所示。假定 A 为60,B 为13:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符"&"是双目运算符。 其功能是参与运算的两数各对应的二进位相与。 | (A & B) 结果为 12, 二进制为 0000 1100 |
| | | 按位或运算符"|"是双目运算符。 其功能是参与运算的两数各对应的二进位相或 | (A | B) 结果为 61, 二进制为 0011 1101 |
| ^ | 按位异或运算符"^"是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| << | 左移运算符"<<"是双目运算符。左移n位就是乘以2的n次方。 其功能把"<<"左边的运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | A << 2 结果为 240 ,二进制为 1111 0000 |
| >> | 右移运算符">>"是双目运算符。右移n位就是除以2的n次方。 其功能是把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数。 |
5)赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
6)其他运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 返回变量存储地址 | &a; 将给出变量的实际地址。 |
| * | 指针变量。 | *a; 是一个指针变量 |
运算符优先级:
有些运算符拥有较高的优先级,二元运算符的运算方向均是从左至右。下表列出了所有运算符以及它们的优先级,由上至下代表优先级由高到低:
| 优先级 | 运算符 |
|---|---|
| 5 | * / % << >> & &^ |
| 4 | + - | ^ |
| 3 | == != < <= > >= |
| 2 | && |
| 1 | || |
当然,你可以通过使用括号来临时提升某个表达式的整体运算优先级
6、条件语句
1)if语句
和Java中的循环语句基本相同,if后的条件不加括号,也可以加括号
if 布尔表达式1 { /* 在布尔表达式1为 true 时执行 */ } else if 布尔表达式2{ /* 在布尔表达式2为 true 时执行 */ } else { /* 在布尔表达式都为 false 时执行 */ }
2)switch
switch 语句用于基于不同条件执行不同动作,每一个 case 分支都是唯一的,从上至下逐一测试,直到匹配为止
switch 语句执行的过程从上至下,直到找到匹配项,匹配项后面也不需要再加 break。
switch 默认情况下 case 最后自带 break 语句,匹配成功后就不会执行其他 case,如果我们需要执行后面的 case,可以使用 fallthrough
switch var1 { case val1: ... case val2: ... default: ... }
type switch
switch 语句还可以被用于 type-switch 来判断某个 interface 变量中实际存储的变量类型。
switch x.(type){
case type:
statement(s);
case type:
statement(s);
/* 你可以定义任意个数的case */
default: /* 可选 */
statement(s);
}
7、循环语句
go只有一种for循环
for init;condition;post{} 和Java中的for(int i=0;i<10;i++){} 相同
1、先对表达式1赋值
2、判别赋值表达式init是否满足给定条件,若其值为真,满足循环条件,则执行循环体内语句,然后执行post,进入第二次循环,再判别condition
3、若判断condition条件不满足,就终止for循环,执行循环体外语句
条件循环:
for condition { } 和Java中的while(condition){} 一样
无限循环:
for{...} 和Java中的for(;;){} 一样,即while(true){}
或 for true {...}
For-each range循环:
可以对字符串、数组、切片等进行迭代输出元素
for i,x:=rang numbers{} i表示索引(从0开始),x表示索引的值
| dataType | 1st value | 2nd value | |
| string | index | s[index] |
unicode, rune (range遍历得到的是rune类型的字符) |
| array/slice | index | s[index] | |
| map | key | value(m[key]) | |
| channel | element |
可忽略不想要的返回值,使用 "_" 这个特殊变量
另外,引用类型如map的遍历,for range 循环的时候会创建每个元素的副本,而不是元素的引用
需要注意:基本类型时range会复制对象,然后再进行迭代,迭代的元素都是从复制对象中输出的。使用引用类型则不会
for-range 和 for 循环的区别:
for-range 遍历会在遍历之前,先拷贝一份被遍历的数据,然后遍历拷贝的数据;for则不会
所以在for-range 遍历过程中去修改被遍历的数据,只是修改拷贝的数据,不会影响到原数据。
同时,因为for-range 会拷贝被遍历数据,因此在需要遍历内存占用比较大的数组时,建议使用普通遍历。如果必须使用范围遍历,我们可以遍历数组的地址或先将数组转换为切片(引用类型底层数据不会被复制),然后遍历。
// 死循环 for { fmt.Println("123") } for i := 0; i < 10; i++ { fmt.Println(i) } // for condition 类似于while(condition) j := 0 for j < 10 { fmt.Println(j) j++ } fmt.Println(j) // 声明切片 intSlice := []int{1, 2, 3, 4, 5} // for each循环 for k, n := range intSlice { fmt.Println(k, n) }
循环控制语句:
break:用于中断当前for循环或跳出switch语句
continue:跳过当前循环的剩余语句,然后继续下一轮循环
goto:将控制转移到被标记的语句,如连续跳出两层循环:
LOOP: for j, ch := range row { // 如果当前元素的值为0 if ch != 0 { continue } // 其一整行是否都为0 for k := 0; k < n; k++ { if trust[k][j] != 0 { goto LOOP } } }
8、变量作用域
作用域为已声明标识符所表示的常量、类型、变量、函数或包在源代码中的作用范围。
Go 语言中变量可以在三个地方声明:
函数内定义的变量称为局部变量(作用域只在函数体内,参数和返回值也是局部变量)
函数外定义的变量称为全局变量(可以在整个包甚至是外部包(被导出后)使用)
函数定义中的变量称为形式参数
9、数组
1)声明
var var_name [size] var_type 如:var a [10] int32
声明并初始化:var a = [5] int{1,2,3,4,5} ,初始化数组中 {} 中的元素个数不能大于 [] 中的数字
如果数组长度不固定,可以使用 ... 代替,编译期会根据元素个数自行推断数组的长度,如: var arr = [...]int{1, 2, 3, 4, 5}
如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小
2)访问
根据索引(从0开始)来读取值:var ar = arr[2]
3)向函数传递数组
void myFunction(param []int) {...}
10、切片(Slice,"动态数组")
Go语言切片是对数组的抽象(一般使用切片代替数组就行了)
Go数组的长度不可改变,在特定场景中这样的集合就不太适用。为此Go提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
1)定义切片(与数组定义类似,[]中省略了长度)
var identifier []type
切片不需要说明长度
或使用make()函数来创建切片:
var slice1 []type = make([]type, len) // 也可以简写为 slice1 := make([]type, len) // len表示数组的长度并且也是切片的初始长度
2)切片初始化
s :=[] int {1,2,3 } // 直接初始化,[]表示是切片类型 s:= arr[:] 初始化切片s,是数组arr[:]的引用 s:= arr[startIndex:endIndex] 将 arr中从下标 startIndex 到 endIndex-1 下的元素创建为一个新的切片(包左不包右) s:= arr[startIndex:] 默认 endIndex 时将表示一直到arr的最后一个元素 s:= arr[:endIndex] 默认 startIndex 时将表示从 arr 的第一个元素开始 s := s1[startIndex:endIndex] // 根据切片s1初始化 s :=make([]int,len,cap) // 通过内置函数 make() 初始化切片s
3)切片内置函数
len():获取切片长度
cap():获取切片最大可达长度
append():向切片中追加元素
copy():拷贝另一个切片的元素,如:/* 拷贝 numbers 的内容到 numbers1 */ copy(numbers1,numbers)
4)切片截取
可以通过设置下限及上限来设置截取切片 [lower-bound:upper-bound]
/* 创建切片 */ numbers := []int{0,1,2,3,4,5,6,7,8} // 截取切片从索引1(包含) 到索引4(不包含) numbers[1:4] // 默认下限为0 numbers[:3] // 默认上限为len(s) numbers[4:]
5)对切片数据排序
s := []int{1, 2, 3, 6, 7, 9, 3} // sort.Ints对整数进行排序,sort.Strings对字符串进行排序,sort.Float64s对浮点数进行排序,sort.Sort对接口类型排序 sort.Ints(s) for _, v := range s { fmt.Print(v) // 1233679 }
5)切片遍历
s := []string{"beijing", "shanghai", "guangzhou", "shenzheng"} // 普通for循环遍历 for i:=0;i<len(s);i++{ fmt.Printf(s[i]) } // range循环遍历 for i, v := range s { fmt.Printf("索引 %d 的值 = %s\n", i, v) }
11、Map(集合)
Map是一种无序的键值对的集合。
Map最重要的一点是通过key来快速检索数据,key类似于索引,指向数据的值
Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map 是无序的,我们无法决定它的返回顺序,这是因为 Map 是使用 hash 表来实现的
1)Map定义
/* 声明变量,默认 map 是 nil ,nil map 不能用来存放键值对*/ var map_variable map[key_data_type]value_data_type 如:var paramMap map[string]string /* 必须使用 make 函数分配内存后才能用来存放键值对 */ map_variable := make(map[key_data_type]value_data_type) 如:map_name:=make(map[string]string)
2)Map操作
// map中插入键值对: map_name[key_value]= value // 遍历map for k,v := range map_name {} // 遍历Map,只遍历key for key:=range map_name {} // 判断map中是否包含某个key value,ok:=map_name[key_name] 存在:if ok {} // 删除集合中的元素 delete()函数,用于删除集合中的元素,参数为map和其对应的key delete(map_name,key_name)
3)sync.Map
Map不是线程安全的,并发安全的map使用 sync.Map
// 线程安全的Map safeMap := &sync.Map{} // 插入键值对 safeMap.Store("name", "yangyongjie") safeMap.Store("age", "20") safeMap.Store("city", "nanjing") // 根据key获取value value1, ok := safeMap.Load("name") fmt.Println(value1) // 如果key存在,则返回value;如果不存在,则插入给定的value value2, ok := safeMap.LoadOrStore("age", 27) fmt.Println(value2) // 删除key safeMap.Delete("name") // 遍历 safeMap.Range(func(key, value interface{}) bool { fmt.Println(key) fmt.Println(value) return true })
12、range
Go 语言中 range 关键字用于 for 循环中迭代 字符串、数组(array)、切片(slice)、通道(channel)或集合(map)的元素
在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对
func main() {
// 定义Map
paramMap := make(map[string]string)
// 插入键值对
paramMap["name"] = "yangyongjie"
paramMap["age"] = "18"
// 只遍历 key
for key := range paramMap {
fmt.Println(key, paramMap[key])
}
// 遍历key,value
for key, value := range paramMap {
fmt.Println(key, value)
}
// 只遍历value
for _, value := range paramMap {
fmt.Println(value)
}
// 遍历字符串
str := "yangyongjie"
for i, s := range str {
fmt.Println(i, s) //得到的是unicode字符
}
}
13、其他
1)下划线
“_”是特殊标识符,用来忽略结果
①:下划线在import中
import 下划线(如:import hello/imp)的作用:当导入一个包时,该包下的文件里所有init()函数都会被执行,然而,有些时候我们并不需要把整个包都导入进来,仅仅是是希望它执行init()函数而已。这个时候就可以使用 import 引用该包。即使用【import _ 包路径】只是引用该包,仅仅是为了调用init()函数,所以无法通过包名来调用包中的其他函数
②:下划线在代码中
忽略这个变量,意思是把值赋给下划线,丢掉不要
for _, c := range s { // 忽略索引这个变量 }
END.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号