MongoDB 学习
MongoDB官网:https://www.mongodb.com/
一、什么是NoSQL?
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
NoSQL的优点/缺点:
优点:高可扩展性、分布式计算、低成本、架构的灵活性,半结构化数据、没有复杂的关系
缺点:没有标准化、有限的查询功能(到目前为止)、最终一致是不直观的程序
NoSQL数据库分类:
| 类型 | 部分代表 | 特点 |
| 列存储 |
Hbase Cassandra Hypertable |
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 |
MongoDB CouchDB |
文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 |
MemcacheDB Redis |
可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 |
Neo4J FlockDB |
图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 |
db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据 |
| xml数据库 |
Berkeley DB XML BaseX |
高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath |
二、什么是MongoDB?
菜鸟教程:https://www.runoob.com/mongodb/mongodb-tutorial.html
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
MongoDB 将数据存储为一个文档,数据结构由键值(key-value)键值对组成。MongoDB文档类似于JSON对象。字段值可以包含其他文档,数组及文档数组。
1、MongoDB概念/与SQL区别
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
示例:
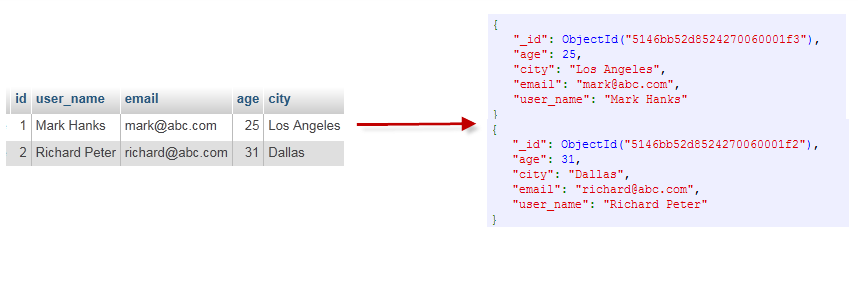
2、MongoDB连接
mongodb://[username:password@]host1[:port1] [,host2[:port2],...[,hostN[:portN]]][/[database][?options]]mongodb:// 这是固定的格式,必须要指定。
username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登录这个数据库
host1 必须的指定至少一个host, host1 是这个URI唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址。
portX 可选的指定端口,如果不填,默认为27017
/database 如果指定username:password@,连接并验证登录指定数据库。若不指定,默认打开 test 数据库。
?options 是连接选项。如果不使用/database,则前面需要加上/。所有连接选项都是键值对name=value,键值对之间通过&或;(分号)隔开
如:
使用用户名fred,密码foobar登录localhost的baz数据库:mongodb://fred:foobar@localhost/baz
连接 replica set 三台服务器 (端口 27017, 27018, 和27019):mongodb://localhost,localhost:27018,localhost:27019
3、常用的命令:
1、show dbs :显示所有数据库的列表
2、use [db名称]:指定一个数据库、如果没有则会创建此数据库
3、db:显示当前数据库对象或集合
4、show collections:显示当前库下所有的集合
5、db.dropshiyongDatabase():先使用use命令切换到要删除的库下,然后使用此命令删除当前库
6、db.collection.drop():删除集合
7、db.createCollection(name, options):创建集合,options可选参数(具体参考文档)。
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
8、db.COLLECTION_NAME.insert(document) :向集合中插入文档(一条记录),如果集合mycol2不存在,会自动创建
9、db.col.remove({'key1':'MongoDB 教程'}):删除
4、MongoDB查询文档
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)
db.col.find().pretty(): 使用pretty方法,使结果易读
db.col.find().count():查询总数
1)MongoDB与RDBMS WHERE语句比较
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {<key>:<value>} |
db.col.find({"key1":"value1"}).pretty() |
where key1 = 'value1' |
| 小于 | {<key>:{$lt:<value>}} |
db.col.find({"key1":{$lt:50}}).pretty() |
where key1 < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} |
db.col.find({"key1":{$lte:50}}).pretty() |
where key1 <= 50 |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"key1":{$gt:50}}).pretty() |
where key1 > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"key1":{$gte:50}}).pretty() |
where key1 >= 50 |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"key1":{$ne:50}}).pretty() |
where key1 != 50 |
2)AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。语法格式如下:
>db.col.find({key1:value1, key2:value2}).pretty()3)OR 条件
OR 条件语句使用了关键字 $or,语法格式如下:
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty() 表示查询键为key1,值为value1或键为key2,值为value2的文档4)AND 和 OR 联合使用
>db.col.find({"likes": {$gt:50}, $or: [{"by": "菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()5)排序 ,使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
>db.COLLECTION_NAME.find().sort({KEY:1})6)模糊查询
使用/,等价于MySQL中的%
/^开往/ :以"开往"开头
/地铁^/ :以"地铁"结尾
/abc/i :忽略大小写
db.collection_name.find({"origin_data":/开往春天的地铁/}).pretty();
5、索引
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
1) 创建索引:createIndex()
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
>db.collection.createIndex(keys, options)key为要创建索引的字段,1表示按升序创建索引,-1表示按降序创建索引。如:db.col.createIndex({"title":1,"description":-1}),表示创建title和description两个字段的索引,一个升序,一个降序
options 选项参考文档:
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
2)查看集合索引:db.col.getIndexes()
3)查看集合索引大小:db.col.totalIndexSize()
4)删除集合所有索引:db.col.dropIndexes()
5)删除集合指定索引:db.col.dropIndex("索引名称")
覆盖索引
①:所有的查询字段是索引的一部分
②:所有的查询返回字段在同一个索引中
最后,如果是以下的查询,不能使用覆盖索引查询:
①:所有索引字段是一个数组
②:所有索引字段是一个子文档
索引限制
1)额外开销
每个索引占据一定的存储空间,在进行插入,更新和删除操作时也需要对索引进行操作。因此要控制索引的数量
2)内存占用
①:由于索引是存储在内存(RAM)中,你应该确保该索引的大小不超过内存的限制
②:如果索引的大小大于内存的限制,MongoDB会删除一些索引,这将导致性能下降
3)查询限制
索引不能被以下的查询使用:
①:正则表达式及非操作符,如 $nin, $not, 等
②:算术运算符,如 $mod, 等
③:$where 子句
4)索引键限制
①:从2.6版本开始,如果现有的索引字段的值超过索引键的限制,MongoDB中不会创建索引
②:如果文档的索引字段值超过了索引键的限制,MongoDB不会将任何文档转换成索引的集合。与mongorestore和mongoimport工具类似
5)最大范围
①:集合中索引不能超过64个
②:索引名的长度不能超过128个字符
③:一个复合索引最多可以有31个字段
6、查询分析
MongoDB 查询分析可以确保我们所建立的索引是否有效,是查询语句性能分析的重要工具
MongoDB 查询分析常用函数有:explain() 和 hint()
1)explain
在查询中使用explain:db.users.find({gender:"M"},{user_name:1,_id:0}).explain()
返回:
indexOnly: 字段为 true ,表示我们使用了索引。
cursor:因为这个查询使用了索引,MongoDB 中索引存储在B树结构中,所以这是也使用了 BtreeCursor 类型的游标。如果没有使用索引,游标的类型是 BasicCursor。这个键还会给出你所使用的索引的名称,你通过这个名称可以查看当前数据库下的system.indexes集合(系统自动创建,由于存储索引信息,这个稍微会提到)来得到索引的详细信息。
n:当前查询返回的文档数量。
nscanned/nscannedObjects:表明当前这次查询一共扫描了集合中多少个文档,我们的目的是,让这个数值和返回文档的数量越接近越好。
millis:当前查询所需时间,毫秒数。
indexBounds:当前查询具体使用的索引
2)hint()
虽然MongoDB查询优化器一般工作的很不错,但是也可以使用 hint 来强制 MongoDB 使用一个指定的索引
这种方法某些情形下会提升性能。 一个有索引的 collection 并且执行一个多字段的查询(一些字段已经索引了)。
如下查询实例指定了使用 gender 和 user_name 索引字段来查询:db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})
7、ObjectId
MongoDB中存储的文档必须有一个"_id"键。这个键的值可以是任何类型的,默认是个ObjectId对象,如果在插入文档时没有指定 _id,则会自动生成
在一个集合里面,每个文档都有唯一的"_id"值,来确保集合里面每个文档都能被唯一标识。_id 字段会自动创建索引
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
①:前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
②:接下来的 3 个字节是机器标识码
③:紧接的两个字节由进程 id 组成 PID
④:最后三个字节是随机数
生成ObjectId:var newObjectId = ObjectId()
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段 newObjectId .getTimestamp()
8、与Java整合
1)引入依赖
<dependencies>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.5.0</version>
</dependency>
</dependencies>2)建立连接
MongoClientURI connectionString = new MongoClientURI("mongodb://localhost:27017,localhost:27018,localhost:27019");
// MongoClient实例表示与数据库的连接池。即使有多个线程,您也只需要一个MongoClient类的实例。
// 所以我们可以在给定的数据库集群创建一个MongoClient实例,并在整个应用程序中使用它
MongoClient mongoClient = new MongoClient(connectionString);
// 连接具体数据库
MongoDatabase database = mongoClient.getDatabase("mydb");3)增删改查操作


// 获取某个集合 MongoCollection<Document> collection = database.getCollection("test"); // 创建一条文档(JSON对象字符串) Document doc = new Document("name", "MongoDB") .append("type", "database") .append("count", 1) .append("info", new Document("x", 203).append("y", 102)); // 插入文档 collection.insertOne(doc); // 批量插入 List<Document> documents = new ArrayList<Document>(); collection.insertMany(documents); // 获取集合下文档数量 collection.count() // 查询集合中的第一条文档 Document myDoc = collection.find().first(); // 查询集合中的所有文档 MongoCursor<Document> cursor = collection.find().iterator(); try { while (cursor.hasNext()) { System.out.println(cursor.next().toJson()); } } finally { cursor.close(); } // 使用filter查询符合条件的记录,如查询field为age,值为26的文档记录 Document myDoc = collection.find(eq("age", 26)).first(); // 查询符合条件(50<i<100)的多条文档,并遍历 // now use a range query to get a larger subset Block<Document> printBlock = new Block<Document>() { @Override public void apply(final Document document) { System.out.println(document.toJson()); } }; collection.find(and(gt("i", 50), lte("i", 100))).forEach(printBlock); // 对i字段进行降序 Document myDoc = collection.find(exists("i")).sort(descending("i")).first(); // 查询到的文档排除掉 _id 字段 Document myDoc = collection.find().projection(excludeId()).first(); // 更新符合过滤器的最多一个文档,使用updateOne。如更新i字段等于10的第一条符合记录的文档,并将i更新为110 collection.updateOne(eq("i", 10), new Document("$set", new Document("i", 110))); // 更新符合过滤器的所有文档,使用updateMany。如更新字段i为10的所有所有文档,返回的UpdateResult 包含更新的文档数 UpdateResult updateResult = collection.updateMany(lt("i", 100), new Document("$inc", new Document("i", 100))); // 删除文档 collection.deleteOne(eq("i", 110)); DeleteResult deleteResult = collection.deleteMany(gte("i", 100));
附录:
Mongo连接工具类:
import com.mongodb.MongoClient; import com.mongodb.MongoClientURI; import com.mongodb.client.MongoDatabase; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.core.io.support.PropertiesLoaderUtils; import java.io.IOException; import java.util.Properties; /** * @author yangyongjie * @date 2021/1/25 * @desc */ public enum MongoUtil { /** * 定义一个枚举元素,代表此类的一个实例 */ INSTANCE; private static final Logger LOGGER = LoggerFactory.getLogger(MongoUtil.class); private MongoClient mongoClient; /** * 重写枚举类的构造方法,枚举类经编译后会在将其放在静态代码块中,在类加载的初始化阶段被调用 */ private MongoUtil() { Properties properties = null; try { properties = PropertiesLoaderUtils.loadAllProperties("application.properties"); } catch (IOException e) { e.printStackTrace(); } if (properties != null) { MongoClientURI connectionString = new MongoClientURI(properties.getProperty("mongo.url")); // MongoClient实例表示与数据库的连接池。即使有多个线程,您也只需要一个MongoClient类的实例。 // 所以我们可以在给定的数据库集群创建一个MongoClient实例,并在整个应用程序中使用它 this.mongoClient = new MongoClient(connectionString); } } /*private static MongoClient mongoClient; static { Properties properties = new Properties(); try { InputStream is = ClassLoader.getSystemResourceAsStream("application.properties"); properties.load(is); } catch (IOException e) { e.printStackTrace(); } if (properties != null) { MongoClientURI connectionString = new MongoClientURI(properties.getProperty("mongo.url")); // MongoClient实例表示与数据库的连接池。即使有多个线程,您也只需要一个MongoClient类的实例。 // 所以我们可以在给定的数据库集群创建一个MongoClient实例,并在整个应用程序中使用它 mongoClient = new MongoClient(connectionString); } }*/ public MongoDatabase getDB(String dbName) { if (dbName != null && !"".equals(dbName)) { MongoDatabase database = mongoClient.getDatabase(dbName); return database; } return null; } }
用法:MongoUtil.INSTANCE.getMiShopDB("db")
补充:客户端可视化工具
1、MongoDB Compass:https://docs.mongodb.com/compass/current/
2、mongobooster:https://www.mongobooster.com/downloads
END.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号