
分库分表
什么是分库分表?
分库分表是为了解决由于库、表数据量过大,而导致数据库性能下降的问题。
当单表的数据量达到1000万以上,就应该考虑进行分库分表拆分了。
然后按照一定的规则,将原本数据量大的数据库拆分成多个单独的数据库,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。
分库分表的核心就是对数据进行切分(sharding)及切分后如何对数据的快速定位与查询结果整合。
分库分表都可以从垂直和水平两种维度进行切分。
一、分库
1、垂直分库
垂直分库核心 就是 专库专用 。
如按照业务类型对表进行分类,将业务相关的一类表放在一个库中
但是垂直分库很大程度上取决于业务的划分,有的时候业务划分不那么清晰的时候,分库就不那么简单了。而且分库仍没有解决单表数据库量过大的问题。
2、水平分库
把同一个表按照规则拆分到不同的数据库中,每个库可以位于不同的服务器上,以此实现水平扩展。
二、分表
1、垂直分表
拆分列。基于列进行。
根据业务耦合性,将关联度低的不同表存储在不同的数据库,与微服务类似,按照业务独立划分,每个微服务使用单独的一个数据库。也可将字段较多
的表拆分新建一张扩展表,将不常用或字段较大的字段拆分出去到扩展表中。
在字段很多的情况下(例如一个大表有100多个字段),通过"大表拆小表",更便于开发与维护,也能避免跨页问题,MySQL底层是通过数据页存储的,
一条记录占用空间过大会导致跨页,造成额外的性能开销。另外数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加
载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
优点:业务解耦清晰;高并发下,提升一定程度的IO,数据库连接数、单机硬件资源瓶颈。
缺点:部分表无法join,只能通过接口聚合,提升了开发复杂度;分布式事务处理复杂。
2、水平分表
拆分行。基于行进行。
分为库内分表,分库分表,根据表内数据内在的逻辑关系,将同一个表按条件分散到多个数据库或多个表中,每张表中包含一部分数据,从而使单张表的数
据量变小。
库内分表只解决了单一表数据量过大的问题,但没有将表分布到不同机器的库上,因此对于减轻MySQL数据库的压力来说,帮助不是很大,大家还是竞争同
一个物理机的CPU、内存、网络IO,最好通过分库分表来解决。
优点:不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力;应用端改造较小,不需要拆分业务模块。
缺点:跨分片的事务一致性难以保证;跨库的join关联性能较差;数据不易维护
如何分库分表?
如何选择路由key,如何对key进行路由?
①:路由key应该在每个表中都存在且唯一
②:路由策略应尽量保证数据能均匀进行分布
如对大数据量进行归档类的业务可以选择时间作为路由key。比如按数据的创建时间作为路由key,每个月或者每个季度创建一个表。按时间作为分库分表后的路由策略可以做到数据归档,历史数据访问流量较小,流量都会打到最新的数据库表中
即如何切分数据,又如何整合?
对于水平拆分数据常见的有取模算法和范围限定算法。
水平拆分数据分片规则:
1、根据数值取模
一般采用hash取模mod的切分方式,如将Order表根据userId字段的某几位的值切分到N个库中(mod N,N为数据库实例数或子表数量),余数为0的放到第一个库,余数为1的放到第二个库,依此类推。
好处:这样同一个用户的数据会分散到同一个库中。
2、范围限定算法
按照 时间区间 或 ID区间 来切分。
按照时间区间或者ID区间来切分。例如:按日期将不同月甚至是日的数据分散到不同的库中;将userId为1~9999的记录分到第一个库,10000~20000的分到第二个库,以此类推。
缺点是对id有较苛刻的要求。
分库分表带来的问题
1、分布式事务
由于表分布在不同库中,会带来跨库事务问题。可以采用阿里的分布式框架Seata来做分布式事务管理
Seata:https://github.com/seata/seata
2、分页、排序、跨库联合查询
3、分布式主键:分库分表之后就不能依赖单个数据库的自增主键来实现不同数据库之间的全局唯一主键,需要一个能够生成全局唯一ID的功能,这个全局唯一ID就叫分布式ID。
如雪花id:https://www.cnblogs.com/yangyongjie/p/14200747.html
4、读写分离:读库与写库都要做分库分表处理
分布分表工具
Sharding-JDBC(当当)、Cobar(阿里巴巴)、MyCAT(基于Cobar)
Sharding-JDBC:
Sharding-JDBC中文官网:https://shardingsphere.apache.org/document/current/cn/overview/
Sharding-JDBC:轻量级Java框架,在Java的JDBC层提供额外的服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。而相比之下,MyCAT是需要单独部署服务的服务端产品
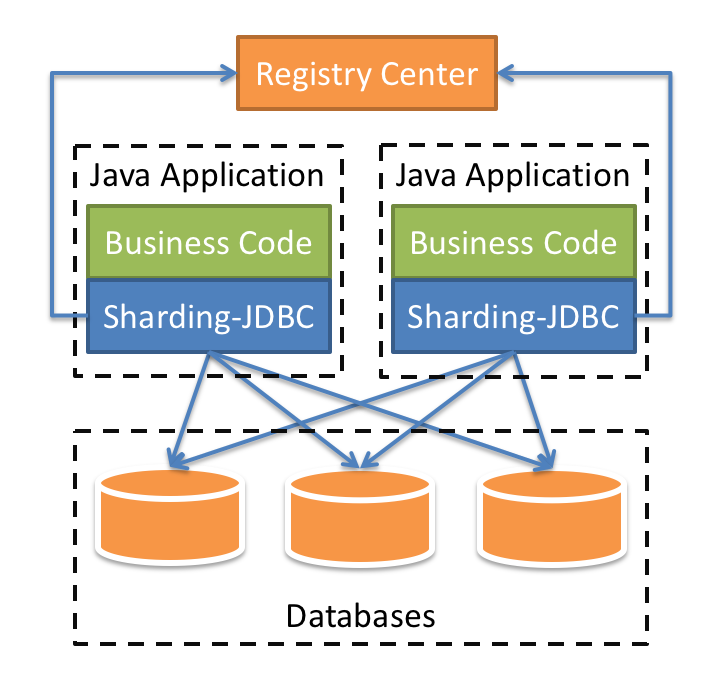
应用:
前提,有bus_0-bus_9,共10个库,每个库中有order_00-order_99、payment_00-payment_99,各100张表。分库分表是根据bus_id。分库是bus_id倒数第三位的值,分表是bus_id倒数两位的值。
1、引入依赖
<!-- https://mvnrepository.com/artifact/org.apache.shardingsphere/sharding-jdbc-core --> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>4.1.1</version> </dependency>
2、分片规则配置
ShardingSphere-JDBC 可以通过 Java,YAML,Spring 命名空间和 Spring Boot Starter 这 4 种方式进行配置,开发者可根据场景选择适合的配置方式
1)Java API配置
Java API 是 ShardingSphere-JDBC 中所有配置方式的基础,其他配置最终都将转化成为 Java API 的配置方式。
Java API 是最复杂也是最灵活的配置方式,适合需要通过编程进行动态配置的场景下使用。
(1)xxx/config.properties:
config.bus.jdbc.username=xxx config.bus.jdbc.password=xxx config.bus.jdbc.driver=com.mysql.jdbc.Driver config.bus.jdbc.url=jdbc:mysql://xxx/%s?useUnicode=true&characterEncoding=utf-8&autoReconnect=true
(2) application.properties:
#datasource ShardingSphere bus.jdbc.username=${config.bus.jdbc.username} bus.jdbc.password=${config.bus.jdbc.password} bus.jdbc.driver=${config.bus.jdbc.driver} bus.jdbc.url=${config.bus.jdbc.url}
(3) ShardingSphereProperties:

import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.stereotype.Component; /** * ShardingSphere数据源属性配置 * */ @Component @ConfigurationProperties(prefix = "bus.jdbc") public class ShardingSphereProperties { private String url; private String driver; private String username; private String password; // getter and setter }
(4) ShardingSphereDataSourceConfig:
import com.zaxxer.hikari.HikariDataSource; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.shardingsphere.api.config.sharding.ShardingRuleConfiguration; import org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration; import org.apache.shardingsphere.api.config.sharding.strategy.InlineShardingStrategyConfiguration; import org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory; import org.mybatis.spring.SqlSessionFactoryBean; import org.mybatis.spring.SqlSessionTemplate; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.io.support.PathMatchingResourcePatternResolver; import org.springframework.jdbc.datasource.DataSourceTransactionManager; import javax.sql.DataSource; import java.sql.SQLException; import java.util.Collection; import java.util.HashMap; import java.util.Map; import java.util.Properties; /** * ShardingSphere-JDBC数据源配置文件 * * @author yangyongjie * @date 2019/9/25 * @desc */ @Configuration public class ShardingSphereDataSourceConfig { private static final Logger LOGGER = LoggerFactory.getLogger(ShardingSphereDataSourceConfig.class); @Autowired private ShardingSphereProperties shardingSphereProperties; /** * ShardingSphereDataSources数据源 * * @return */ @Bean public DataSource shardingSphereDataSource() throws SQLException { // 构建数据源 Map<String, DataSource> dataSourceMap = new HashMap(16); // 库为bus0-bus9 for (int i = 0; i < 10; i++) { String databaseName = "bus_" + i; dataSourceMap.put(databaseName, createDataSource(databaseName)); } // 构建配置规则 ShardingRuleConfiguration shardingRuleConfiguration = new ShardingRuleConfiguration(); // 配置默认分库策略 shardingRuleConfiguration.setDefaultDatabaseShardingStrategyConfig( new InlineShardingStrategyConfiguration("bus_id", "bus_${(bus_id% 10000)/1000}")); // 分片表的规则配置 Collection<TableRuleConfiguration> tableRuleConfigurations = shardingRuleConfiguration.getTableRuleConfigs(); // 需要分片的表 TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("order","bus_${0..9}.order_0${0..9},bus_${0..9}.order_${10..99}"); TableRuleConfiguration paymentTableRuleConfig = new TableRuleConfiguration("payment","bus_${0..9}.payment_0${0..9},bus_${0..9}.payment_${10..99}"); // order表分片策略 orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("bus_id", "order_${(xiaomi_id%100/10)}${(xiaomi_id%10)}")); // payment表分片策略 paymentTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("bus_id", "payment_${(xiaomi_id%100/10)}${(xiaomi_id%10)}")); tableRuleConfigurations.add(orderTableRuleConfig); tableRuleConfigurations.add(paymentTableRuleConfig); // 构建属性配置 Properties props = new Properties(); DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfiguration, props); return dataSource; } private DataSource createDataSource(String dataSourceName) { HikariDataSource dataSource = new HikariDataSource(); String jdbcUrl = String.format( shardingSphereProperties.getUrl(), dataSourceName); dataSource.setJdbcUrl(jdbcUrl); dataSource.setDriverClassName(shardingSphereProperties.getDriver()); dataSource.setUsername(shardingSphereProperties.getUsername()); dataSource.setPassword(shardingSphereProperties.getPassword()); // 数据源其它配置 dataSource.setMinimumIdle(2); dataSource.setMaximumPoolSize(10); dataSource.setMaxLifetime(300000); return dataSource; } @Bean public SqlSessionFactory shardingSphereSqlSessionFactory() { SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean(); // 扫描相关mapper文件 PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(); SqlSessionFactory sqlSessionFactory = null; try { sqlSessionFactoryBean.setMapperLocations(resolver.getResources("classpath:/mapper/**/*Mapper.xml")); sqlSessionFactoryBean.setDataSource(shardingSphereDataSource()); // sqlSessionFactoryBean.setConfigLocation(); sqlSessionFactory = sqlSessionFactoryBean.getObject(); } catch (Exception e) { LOGGER.error("创建SqlSessionFactory:"+e.getMessage(),e); } return sqlSessionFactory; } @Bean public SqlSessionTemplate shardingSphereSqlSessionTemplate() { return new SqlSessionTemplate(shardingSphereSqlSessionFactory()); } /** * sharding数据源事务管理器 * * @return */ @Bean public DataSourceTransactionManager shardingSphereTransactionManager() throws SQLException { return new DataSourceTransactionManager(shardingSphereDataSource()); } }
使用:
@Autowired @Qualifier("shardingSphereSqlSessionTemplate") private SqlSessionTemplate shardingSphereSqlSessionTemplate; @Override public Order queryByBusId(long busId){ Map<String,Object> param=new HashMap<>(4); param.put("busId",busId); return shardingSphereSqlSessionTemplate.selectOne(NAMESPACE + ".queryByBusId", param); } <select id="queryByBusId" resultMap="OrderMap"> select id, bus_id from `order` where bus_id = #{busId} </select>
可以看出配置较为复杂,推荐使用YAML方式
2) YAML配置
(1) yml文件:
(2)ShardingSphereDataSourceConfig
import org.apache.ibatis.session.SqlSessionFactory; import org.apache.shardingsphere.shardingjdbc.api.yaml.YamlShardingDataSourceFactory; import org.mybatis.spring.SqlSessionFactoryBean; import org.mybatis.spring.SqlSessionTemplate; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.io.support.PathMatchingResourcePatternResolver; import org.springframework.jdbc.datasource.DataSourceTransactionManager; import org.springframework.util.ResourceUtils; import javax.sql.DataSource; import java.io.File; import java.io.IOException; import java.sql.SQLException; /** * ShardingSphere-JDBC数据源配置文件 * * @author yangyongjie * @date 2019/9/25 * @desc */ @Configuration public class ShardingSphereDataSourceConfig { private static final Logger LOGGER = LoggerFactory.getLogger(ShardingSphereDataSourceConfig.class); @Bean public DataSource shardingSphereDataSource() throws IOException, SQLException { // 指定 YAML 文件路径 File yamlFile = ResourceUtils.getFile("classpath:bus-0-9-db.yml"); DataSource dataSource = YamlShardingDataSourceFactory.createDataSource(yamlFile); return dataSource; } @Bean public SqlSessionFactory shardingSphereSqlSessionFactory() { SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean(); // 扫描相关mapper文件 PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(); SqlSessionFactory sqlSessionFactory = null; try { sqlSessionFactoryBean.setMapperLocations(resolver.getResources("classpath:/mapper/**/*Mapper.xml")); sqlSessionFactoryBean.setDataSource(shardingSphereDataSource()); // sqlSessionFactoryBean.setConfigLocation(); sqlSessionFactory = sqlSessionFactoryBean.getObject(); } catch (Exception e) { LOGGER.error("创建SqlSessionFactory:" + e.getMessage(), e); } return sqlSessionFactory; } @Bean public SqlSessionTemplate shardingSphereSqlSessionTemplate() { return new SqlSessionTemplate(shardingSphereSqlSessionFactory()); } /** * sharding数据源事务管理器 * * @return */ @Bean public DataSourceTransactionManager shardingSphereTransactionManager() throws SQLException, IOException { return new DataSourceTransactionManager(shardingSphereDataSource()); } }
配置项说明:
1 dataSources: # 省略数据源配置 2 3 rules: 4 - !SHARDING 5 tables: # 数据分片规则配置 6 <logic-table-name> (+): # 逻辑表名称 7 actualDataNodes (?): #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持行表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况 8 databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一 9 standard: # 用于单分片键的标准分片场景 10 shardingColumn: # 分片列名称 11 shardingAlgorithmName: # 分片算法名称 12 complex: # 用于多分片键的复合分片场景 13 shardingColumns: #分片列名称,多个列以逗号分隔 14 shardingAlgorithmName: # 分片算法名称 15 hint: # Hint 分片策略 16 shardingAlgorithmName: # 分片算法名称 17 none: # 不分片 18 tableStrategy: # 分表策略,同分库策略 19 keyGenerateStrategy: # 分布式序列策略 20 column: # 自增列名称,缺省表示不使用自增主键生成器 21 keyGeneratorName: # 分布式序列算法名称 22 autoTables: # 自动分片表规则配置 23 t_order_auto: # 逻辑表名称 24 actualDataSources (?): # 数据源名称 25 shardingStrategy: # 切分策略 26 standard: # 用于单分片键的标准分片场景 27 shardingColumn: # 分片列名称 28 shardingAlgorithmName: # 自动分片算法名称 29 bindingTables (+): # 绑定表规则列表 30 - <logic_table_name_1, logic_table_name_2, ...> 31 broadcastTables (+): # 广播表规则列表 32 - <table-name> 33 defaultDatabaseStrategy: # 默认数据库分片策略 34 defaultTableStrategy: # 默认表分片策略 35 defaultKeyGenerateStrategy: # 默认的分布式序列策略 36 37 # 分片算法配置 38 shardingAlgorithms: 39 <sharding-algorithm-name> (+): # 分片算法名称 40 type: # 分片算法类型 41 props: # 分片算法属性配置 42 # ... 43 44 # 分布式序列算法配置 45 keyGenerators: 46 <key-generate-algorithm-name> (+): # 分布式序列算法名称 47 type: # 分布式序列算法类型 48 props: # 分布式序列算法属性配置 49 # ... 50 51 props: 52 # ...
参考:https://developer.aliyun.com/article/773700?utm_content=g_1000188740
END.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类
2019-10-12 Spring整合Kafka