
Redis之过期策略及内存淘汰机制
朝生暮死-过期策略
设置了有效期的key到期了怎么删除呢?
Redis会将每个设置了过期时间的key放入一个独立的字典中,以后会定时遍历这个字典来删除到期的key。
除了定时遍历之外还会使用惰性策略来删除过期的key。所谓惰性删除就是在客户端访问这个key的时候,Redis对key的过期时间进行检查,如果过期了就会立即删除。
所以过期key的删除策略是:定时删除+惰性删除
定时删除:Redis默认每秒进行10次过期扫描,过期扫描不会遍历过期字典中所有的key,而是采用了一种简单的贪心策略,步骤如下:
1、从过期字典中随机选出20个key
2、删除这20个key中已经过期的key
3、如果过期的key的比例超过1/4,那就重复步骤1
同时,为了保证过期扫描不会出现循环过度,导致线程卡死的现象,算法还增加了扫描时间的上限,默认不会超过25ms。
假设一个大型的Redis实例中所有的key在同一时间过期了,会出现怎么样的结果呢?
毫无疑问,Redis会持续循环多次扫描过期字典,直到过期字典中过期的key变得稀疏,才会停止(循环次数明显下降)。这就会导致线上读写请求出现明显的卡顿现象。
导致这种卡顿的另外一种原因是内存管理器需要频繁回收内存页,这也会产生一定的CPU消耗。
如当客户端到来时,服务器正好进入过期扫描状态,客户端的请求将会等待至少25ms后才会进行处理,如果客户端将超时时间设置的比较短,如10ms,那么就会出现大量的请求因为超时而关闭。
业务端会出现很多异常,而且这是你还无法从Redis的slowlog中看到慢查询记录,因为慢查询指的是逻辑处理过程慢,而不包含等待时间。所以当客户端出现大量超时而慢查询日志无记录时,可能是当前时间段大量的key过期导致的。
所以在开发过程中一定要避免在同一时间内出现大量的key同时过期。尽量给key的过期时间设置一个随机范围,使其过期时间均匀分布。
从节点不会进行过期扫描,过期的处理是被动的,主节点在key到期时,会在AOF日志文件中增加一条del指令,同步到所有的从节点,从节点通过执行
这条del指令来删除过期的key。因为指令同步是异步的,所以会出现从节点的key删除不及时的情况。
惰性删除:
实际上Redis内部并不是只有一个主线程,它还有几个异步线程来处理一些耗时的操作。如果被删除的key是一个非常大的对象,那么del指令删除操作就
会导致单线程卡顿。所以4.0版本引入了unlink指令,可以对删除操作进行懒处理,丢给后台线程来异步回收内存。
在获取某个key的时候,Redis会检查一下这个key是否设置了过期时间以及这个是否到期了,如果到期了就交给后台线程去删除这个key,然后主线程什么也不会返回。
优胜劣汰-LRU内存淘汰机制
当Redis内存超过物理内存限制时,内存的数据会开始和磁盘产生频繁的交换swap,交换会让Redis的性能急剧下降,对于访问量比较大的Redis来说,会
导致响应时间过长。所以在生产环境中不允许有这种交换行为,为了限制最大内存,Redis提供了配置参数maxmemory参数来限制内存使用阀值,当超出这个
阀值时,Redis提供了几种可选的内存淘汰策略供用户选择以腾出空间以继续提供读写服务。
1、noeviction 不会继续服务写请求,del和读服务可以继续进行,这是默认的淘汰策略
2、volatile-lru 尝试淘汰设置了过期时间的最近最少使用的key
3、volatile-ttl 尝试淘汰了设置了过期时间的ttl(Time to live)最少的key
4、volatile-random 尝试从设置了过期时间的key中随机淘汰一部分key
5、allkeys-lru 尝试淘汰所有的key中最近最少使用的key
6、allkeys-random 尝试从所有的key中随机淘汰一部分key
LRU算法
实现LRU算法除了需要key/value字典外,还需要附加一个链表,链表中的元素按照一定的顺序进行排列。当字典中的某个元素被访问时,会将它从在链表中的某个位置移动到链表头部;
当空间满的时候,会踢掉链表尾部的元素。所以链表元素的排列顺序就是元素最近被访问的顺序。
Redis使用的是近似的LRU算法,因为LRU算法需要占用大量的额外内存,还需要对现有的数据结构进行比较大的改造。近似LRU算法很简单,在现有的数据结构的基础上使用随机采样法淘汰元素,通过给每个key增加一个额外的24bit的小字段存储最后一次被访问的时间戳。而且采用的是惰性策略,Redis在执行写操作时,发现内存超过maxmemory,就会执行一次近似LRU算法,随机采样出5(可以设置)个key,然后淘汰掉最旧的key,如果淘汰后内存仍大于maxmemory,继续采样淘汰,直到内存小于maxmemory为止。
手写一个LRU算法,有三种方案
1、数组,用数组来存储数据,并给每个数据项标记一个时间戳,每次插入新数据项的时候,先把数组中存在的数据项对应的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中新数据项的时候,将被访问的数据项的时间戳置为0。当数组空间满时,将时间戳最大的数据项淘汰。
2、链表,每次插入新数据的时候将新数据插入到链表的头部,每次访问数据也将被访问的数据移动到链表头部,当链表满时将链表尾部的数据淘汰
3、链表+hashMap,LinkedHashMap。当需要插入新的数据项的时候,如果新数据项在链表中存在(即命中),则把该节点移动到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1,这样链表尾部的节点就是最近最少访问的数据项。
分析:使用数组需要不停维护数据项的访问时间戳,并且在插入数据,访问和删除数据(不知道数组下标)的时候,时间复杂度都是O(n),仅使用链表的情况下,
在访问定位数据的时间复杂度为O(n),所以一般使用LinkedHashMap的方式。LinkedHashMap的底层就是使用HashMap加双向链表实现的,而且本身是有序的(插入和访问顺序相同),新插入的元素放入链表的尾部;且其有removeEldestEntry方法用于移除最老的元素,不过默认返回false,表示不移除,需要重写此方法当超过map容量时移除最老的元素即可。
LinkedHashMap:

/** * Returns <tt>true</tt> if this map should remove its eldest entry. * This method is invoked by <tt>put</tt> and <tt>putAll</tt> after * inserting a new entry into the map. It provides the implementor * with the opportunity to remove the eldest entry each time a new one * is added. This is useful if the map represents a cache: it allows * the map to reduce memory consumption by deleting stale entries. * * <p>Sample use: this override will allow the map to grow up to 100 * entries and then delete the eldest entry each time a new entry is * added, maintaining a steady state of 100 entries. * <pre> * private static final int MAX_ENTRIES = 100; * * protected boolean removeEldestEntry(Map.Entry eldest) { * return size() > MAX_ENTRIES; * } * </pre> * * <p>This method typically does not modify the map in any way, * instead allowing the map to modify itself as directed by its * return value. It <i>is</i> permitted for this method to modify * the map directly, but if it does so, it <i>must</i> return * <tt>false</tt> (indicating that the map should not attempt any * further modification). The effects of returning <tt>true</tt> * after modifying the map from within this method are unspecified. * * <p>This implementation merely returns <tt>false</tt> (so that this * map acts like a normal map - the eldest element is never removed). * * @param eldest The least recently inserted entry in the map, or if * this is an access-ordered map, the least recently accessed * entry. This is the entry that will be removed it this * method returns <tt>true</tt>. If the map was empty prior * to the <tt>put</tt> or <tt>putAll</tt> invocation resulting * in this invocation, this will be the entry that was just * inserted; in other words, if the map contains a single * entry, the eldest entry is also the newest. * @return <tt>true</tt> if the eldest entry should be removed * from the map; <tt>false</tt> if it should be retained. */ protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }
构造方法:
/** * Constructs an empty <tt>LinkedHashMap</tt> instance with the * specified initial capacity, load factor and ordering mode. * * @param initialCapacity the initial capacity * @param loadFactor the load factor * @param accessOrder the ordering mode - <tt>true</tt> for * access-order, <tt>false</tt> for insertion-order * @throws IllegalArgumentException if the initial capacity is negative * or the load factor is nonpositive */ public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
自定义LRU实现:
package lru; import java.util.LinkedHashMap; import java.util.Map; /** * LinkedHashMap 实现LRU算法 * 〈功能详细描述〉 * * @author 17090889 * @see [相关类/方法](可选) * @since [产品/模块版本] (可选) */ public class LRU<k, v> extends LinkedHashMap<k, v> { /** * 容量,实际能存储多少数据 */ private final int MAX_ENTRIES; /** * Math.ceil(cacheSize/0.75f)+1 HashMap的initialCapacity * 0.75f 负载因子 * accessOrder 排序模式,true:按照访问顺序进行排序,最近访问的放在尾部 false:按照插入顺序 * * @param maxEntries */ public LRU(int maxEntries) { super((int) (Math.ceil(maxEntries / 0.75f) + 1), 0.75f, true); MAX_ENTRIES = maxEntries; } /** * 重写移除最老元素方法 * 返回true,表示删除最老元素 false 表示不删除 * * @param eldest * @return */ @Override protected boolean removeEldestEntry(Map.Entry<k, v> eldest) { // 当实际容量大于指定的容量的时候就自动删除最老的元素,链表头部的元素 return size() > MAX_ENTRIES; } }
插入测试:
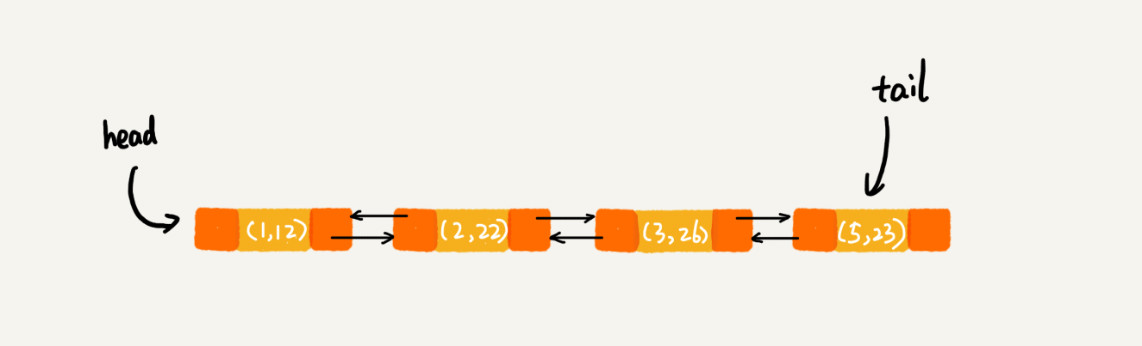
LRU<String, String> lru = new LRU<>(5); lru.put("3", "3"); lru.put("1", "1"); lru.put("5", "5"); lru.put("2", "22"); lru.put("3", "33"); lru.get("5");
遍历得到的结果:1 2 3 5
存储链表结构为:
LFU算法
Redis 4.0 引入了一个新的淘汰策略,LFU(Lasted Fequently Used) :最少频繁使用。按照最近的访问频率进行淘汰,比LRU更加精确地表示了一个key被访问的热度。
如果一个key长时间不被访问,只是偶尔被访问了一下,那么它在LRU算法中就被移动到了链表的头部,是不容易被淘汰的,因为LRU算法会认为它是一个热点key。
而LFU需要追踪最近一段时间内key的访问频率,只有最近一段时间内被访问多次的key,LFU才认为是热点key。
END.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类
2019-10-12 Spring整合Kafka