
ConcurrentHashMap1.7源码分析
HashMap不是线程安全的,其所有的方法都未同步,虽然可以使用Collections的synchronizedMap方法使其线程安全,但是针对的只是当前的map对象。
对此,JDK提供了线程安全的Hashtable,其所有的方法都是同步的,使用的是全局同步锁,即使用Synchronized关键字进行加锁,但是也导致了同一时刻只能有一个线程操作哈希表,影响性能;
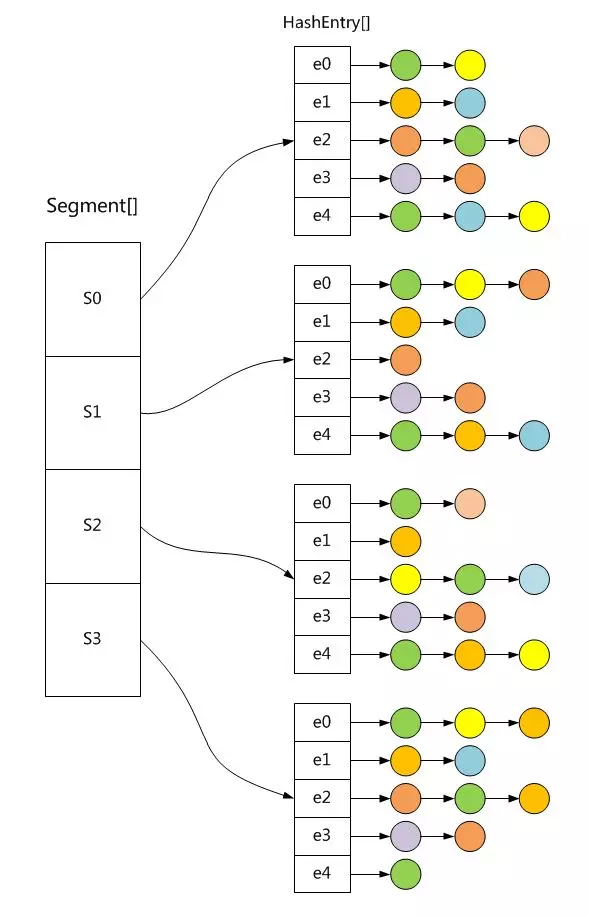
所以,又提供了效率较高的线程安全的哈希表ConcurrentHashMap,其内部使用分段锁将锁进行细粒度化,里面包含一个Segment数组,Segment继承于ReentrantLock,Segment则包含HashEntry的数组,HashEntry本身就是一个链表的结构,具有保存key、value的能力及指向下一个节点的指针。
实际上每个Segment都是一个HashMap,默认的Segment的个数是16,也就是支持16个线程的并发读写。每个Segment内部互不干扰,从而使多个线程能够同时操作哈希表,大大提高了性能。
不同Segment的写入可以并发执行,同一个Segment的写和读可以并发执行。
下面是其内部结构示意图:
Like {@link Hashtable} but unlike {@link HashMap}, this class does <em>not</em> allow {@code null} to be used as a key or value 和Hashtable一样,不允许null键和null值
Concurrent1.7和1.8的区别:
1.7中采用Segment+HashEntry的方式进行实现,并发控制使用ReentrantLock来实现。
每一个Segment元素存储的是HashEntry数组+链表,和HashMap的数据结构相同
1.8中放弃了Segment臃肿的设计,取而代之的是采用Node数组+链表+红黑树的数据结构来实现,当链表的长度大于8时会转化为红黑树。
并发控制使用 Synchronized+CAS来保证
JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言,总结如下思考
JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的(logn),代替一定阈值的链表,这样形成一个最佳拍档
JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock:
1、因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,
更加的灵活,而在低粒度中,Condition的优势就没有了
2、JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
3、在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
原文:https://blog.csdn.net/qq296398300/article/details/79074239
以下源码基于Java 1.7版本
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable { private static final long serialVersionUID = 7249069246763182397L;
其成员变量:

/** * The maximum number of segments to allow; used to bound * constructor arguments. Must be power of two less than 1 << 24.
* 分段锁的最大数量 */ static final int MAX_SEGMENTS = 1 << 16; /** * Number of unsynchronized retries in size and containsValue * methods before resorting to locking. This is used to avoid * unbounded retries if tables undergo continuous modification * which would make it impossible to obtain an accurate result.
* 分段锁的最小数量 */ static final int RETRIES_BEFORE_LOCK = 2; /** * Mask value for indexing into segments. The upper bits of a * key's hash code are used to choose the segment.
* 分段锁的掩码值 */ final int segmentMask; /** * Shift value for indexing within segments.
* 分段锁的移位值 */ final int segmentShift; /** * The segments, each of which is a specialized hash table.
* 分段锁数组 */ final Segment<K,V>[] segments;
Segment是ConcurrentHashpMap的一个静态内部类:
static final class Segment<K,V> extends ReentrantLock implements Serializable { static final int MAX_SCAN_RETRIES = Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1; transient volatile HashEntry<K,V>[] table; transient int count; transient int modCount; transient int threshold; final float loadFactor;
Segment继承了ReentrantLock ,所以其本质上是一个锁。
分段锁即是由Segment来实现的,它继承于ReentrantLock,用来管理它辖区内的各个HashEntry。ConcurrentHashMap被Segment分成了很多小区,Segment就相当于小区保安,
HashEntry列表相当于小区业主,小区保安通过加锁的方式,保证每个Segment内都不发生冲突。
put和remove方法,对于Segment内部元素和计数器的更新,全部处于锁的保护下,如Segment.put()方法的第一行:
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
参考:https://www.cnblogs.com/liuyun1995/p/8631264.html
END.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类