详解Linux中的awk命令
简介
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
一、选项参数说明
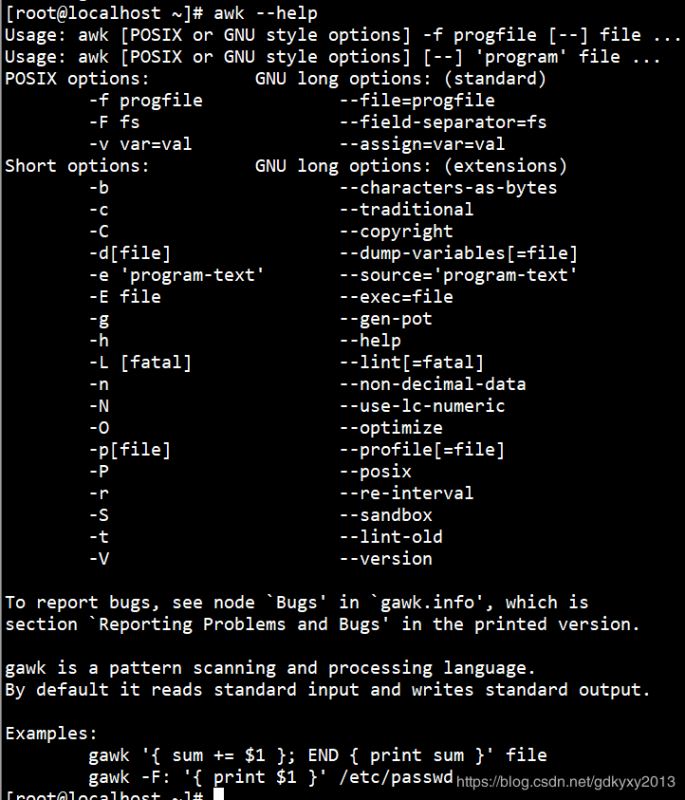
awk是一种处理文本文件的语言,我们可以使用awk --help查看一下它的选项参数,如下:
二、基本用法
1、行匹配语句,此处awk后只能跟单引号,格式如下:
|
1
|
awk '{匹配的内容}' 匹配的文件名称 |
例如:
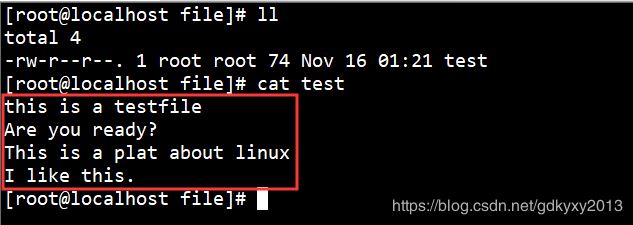
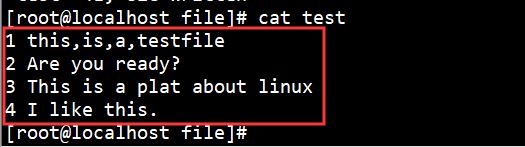
现有如下测试文件test:
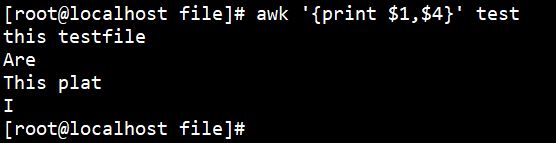
使用如下命令输出文中每行的1、4项内容:
|
1
|
awk '{print $1,$4}' test |
也可以添加如下内容使其格式化输出:
awk '{printf "%-8s %-10s\n",$1,$4}' test 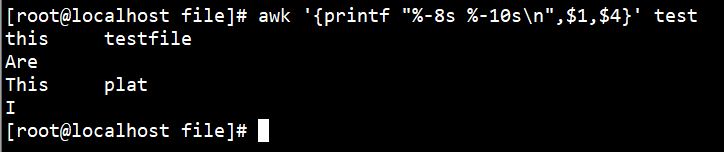
2、指定分隔符
|
1
|
awk '{printf "%-8s %-10s\n",$1,$4}' test |
例如:
有如下test文件:
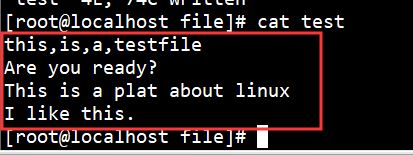
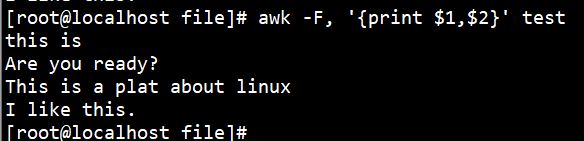
执行如下命令,使用逗号分割输出每行的第一、二项内容:
|
1
|
awk -F, '{print $1,$2}' test |
也可以使用内建变量,格式如下:
|
1
|
awk 'BEGIN{FS=","} {print $1,$2}' test |

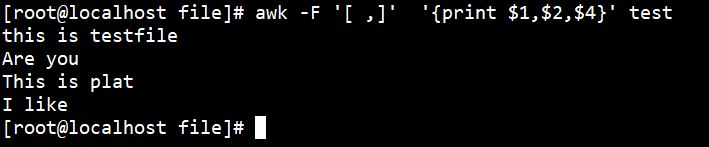
对于使用多个分隔符,首先使用空格分割,然后再使用其他分割符进行分割:
|
1
|
awk -F '[ ,]' '{print $1,$2,$4}' test |
3、设置变量
|
1
|
awk -v |
例如:
现有如下数据:
执行如下命令,每行第一项加1:
|
1
|
awk -va=1 '{print $1,$1+a}' test |

也可以使用如下命令设置多个变量:
|
1
|
awk -va=1 -vb=s '{print $1,$1+a,$1b}' test |

4、通过awk脚本来运行awk命令
|
1
|
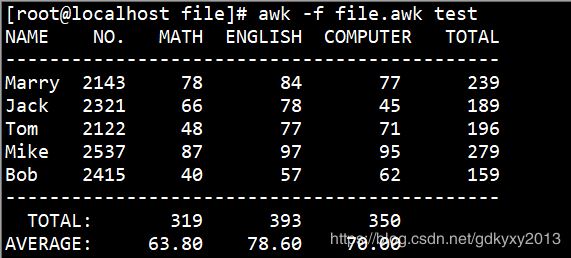
awk -f awk脚本 文件名 |
例如:
|
1
|
awk -f file.awk test |
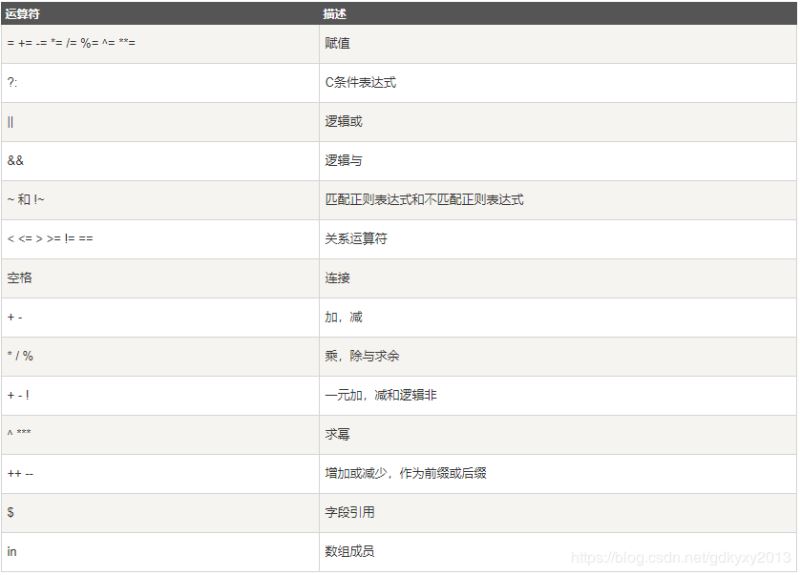
三、运算符
例如:
1、过滤第一列大于2的行
|
1
|
awk '$1>2' test |

2、过滤等于2的列
|
1
|
awk '$1==2 {print $1,$3}' test |
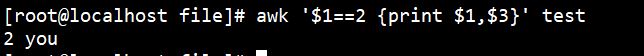
3、过滤第一列大于2并且第二列等于Are的行
|
1
|
awk '$1>2 && $2=="Are" {print $1,$2,$3}' test |
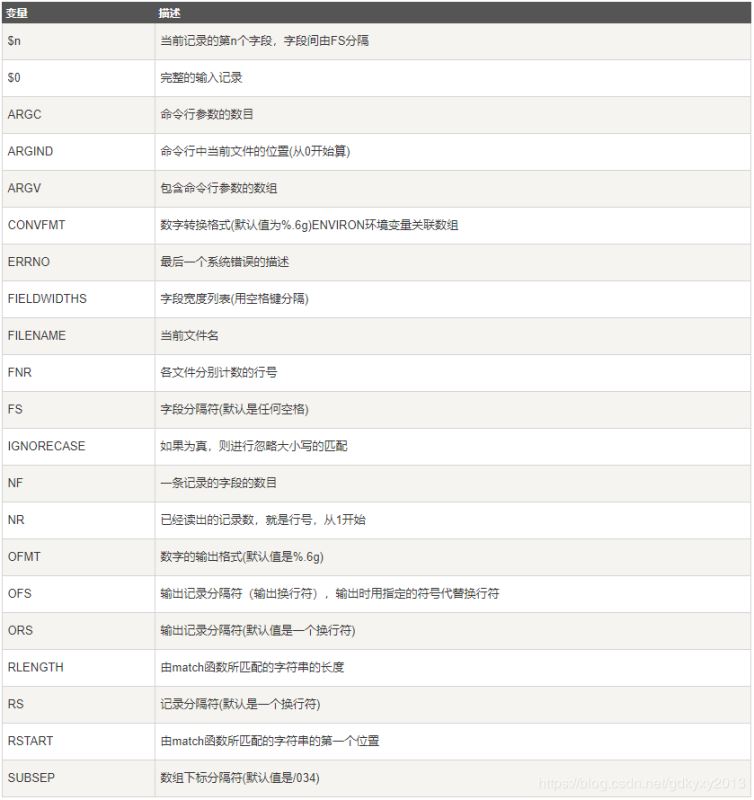
四、内建变量
例如:
|
1
|
awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' test |
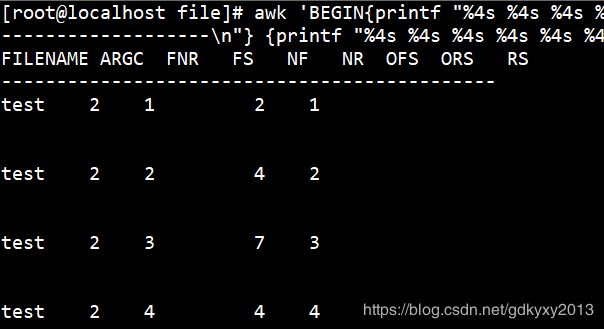
|
1
|
awk -F\' 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' test |
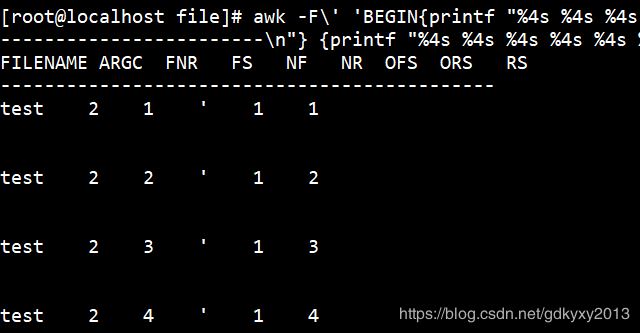
|
1
|
awk '{print NR,FNR,$1,$2,$3}' test |

|
1
|
awk '{print $1,$2,$5}' OFS=" $ " test |

五、使用正则,字符串匹配
例如:
1、输出第二列包含“th”并打印第二列与第四列。
|
1
|
awk '$2 ~ /th/ {print $2,$4}' test |

~表示模式开始,//中存放匹配的模式。
2、输出包含“re”的行
|
1
|
awk '/re/ ' test |

六、忽略大小写
|
1
|
awk 'BEGIN{IGNORECASE=1} /this/' test |

七、模式取反
|
1
|
awk '$2 !~ /th/ {print $2,$4}' test |

|
1
|
awk '!/th/ {print $2,$4}' test |

八、awk脚本
关于awk脚本,需要注意BEGIN和END两个关键词:
(1)BEGIN{存放执行前的语句};
(2)END{存放处理完所有的行后要执行的语句}。
例如:
现有数据如下:
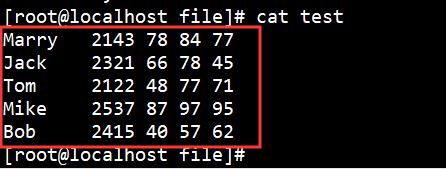
我们的awk脚本内容如下:
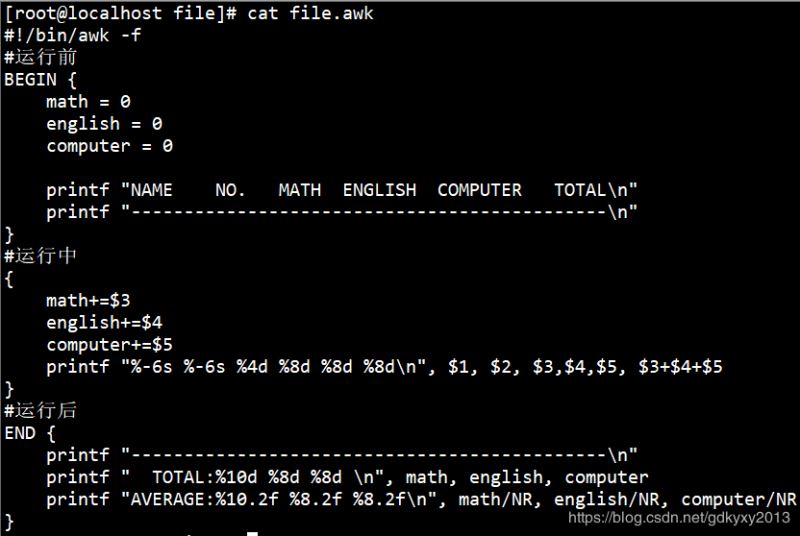
执行结果如下: