

---------------------不定时的更新叒叕开始了,且更且珍惜------------------------
我要每次都写一遍:前面的还没补完,以此催促不定时更新的我
-----------------------------------------------------------------------------------------------
主要内容
路由层
无名分组
有名分组
反向解析
路由分发
名称空间
伪静态网页
虚拟环境
视图层
JsonReponse
FBV与CBV
文件上传
🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒🍒
详细内容
路由层
路由匹配规则
urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^$',views.home), url(r'^test/$',views.test), url(r'^testadd/$',views.testadd), url(r'',views.error) ]
❗注意: 第一个参数是正则表达式(匹配规则按照从上往下一次匹配,匹配到一个之后立即匹配,
直接执行对应的视图函数);第二个参数是视图函数的函数名。
当浏览器中输入URL回车时,会按从上往下往下的顺序依次去匹配URL,如果匹配上了,
则自动调用执行相应的视图函数(函数名加括号,并且会默认传一个参数,
我们视图函数中用名为request的形参接收)。
如果所有正则都匹配不上该URL,则报错。
这时候我们可以设置下面两个来避免报错的情况:
网站首页路由(固定写法)
url(r'^$',views.home)
网站不存在页面(自定义找不到路由的报错信息)
❗注意:该路由需放在所有路由中的最下面,因为正则空‘’能匹配所有字符串
url(r'',views.error)
无名分组与有名分组
正则中有分组的语法,当我们给正则表达式加上分组时,
只会返回匹配结果中分组的内容
未分组
url(r'^test/\d+/',views.test), # \d+匹配一个或多个数字
def test(request):
return HttpResponse('test ok')
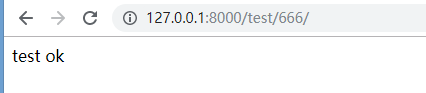
这时候在浏览器访问URL是可以正常访问的:
http://127.0.0.1:8000/test/666/ 结果如下
但是如果\d+加了括号再去访问还能行吗?
当你看到这个大黄页时,那么很明显是不能了。这就需要用到无名分组了
无名分组
将加括号的正则表达式匹配到的内容当做位置参数自动传递给对应的视图函数
推导🔊:
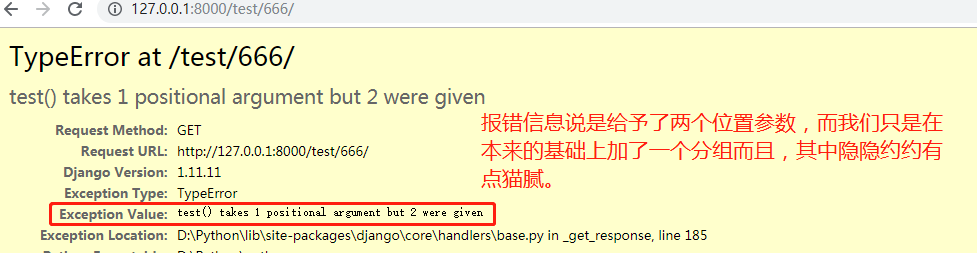
上面说只需要一个位置参数,但却给了两个位置实参,
那么我们就用两个形参接收来看看到底是何方妖孽
url(r'^test/(\d+)/',views.test), # 匹配一个或多个数字 def test(request,xxx): print(xxx) return HttpResponse('test')
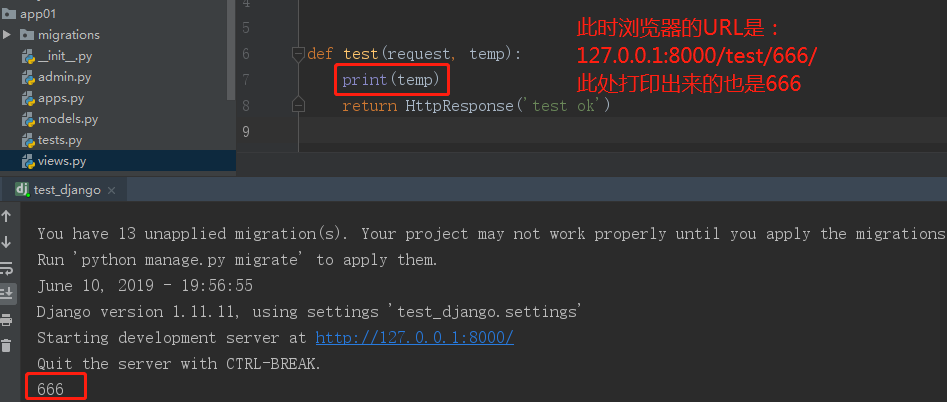
在多次修改URL后,得出了一个结论:我们将\d+作为一个分组,
视图函数中也会接收到一个实参,该实参就是分组中的内容。
这就意味着我们将url的正则表达式进行分组时,当路由匹配成功,
自动调用视图函数时会把分组中的内容也传过去,
所以分组时视图函数要定义额外的形参接收。
有名分组
将加括号的正则表达式匹配到的内容当做关键字参数自动传递给对应的视图函数
推导🔊:
url(r'^test/(?P<year>\d+)/',views.test), # 匹配一个或多个数字
def test(request,year):
print(year)
return HttpResponse('test')
浏览器访问URL:http://127.0.0.1:8000/test/666/ 的结果如下:
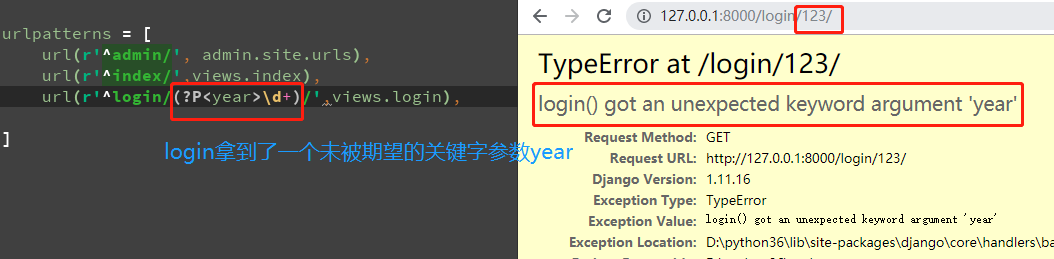
告诉我们这时候它需要的是一个关键字参数,那我们怎么办,
当然是选择原谅它,它要什么就给什么啦!谁让它是大宝贝呢!
视图函数也要随之定义一个和分组名字一样的形参。
如果名字不一样会怎么样:
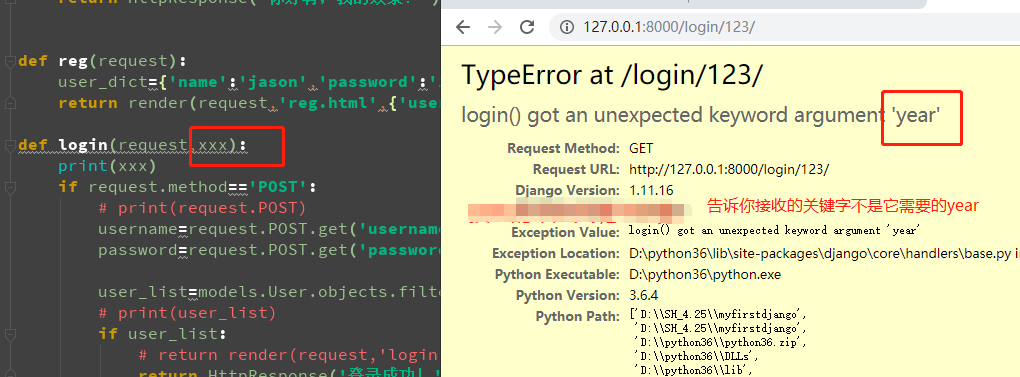
答案很明显,一个大黄页等着你。
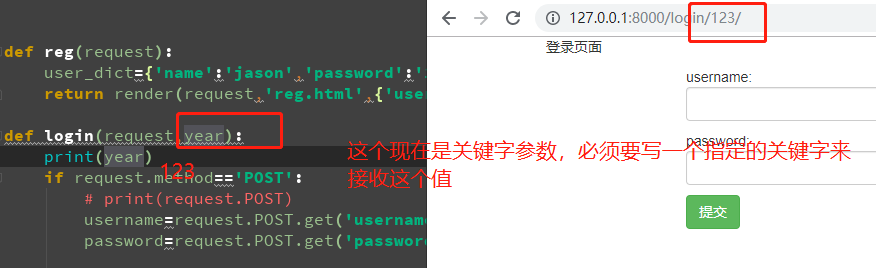
改成year之后就能成功访问了,哈哈哈
❗注意:无名分组和有名分组不能混着用!!!
url(r'^test/(\d+)/(?P<year>\d+)/',views.test) # 错误
但是支持用一类型多个形式匹配
无名分组多个
url(r'^test/(\d+)/(\d+)/',views.test),
有名分组多个
url(r'^test/(?P<year>\d+)/(?P<xxx>\d+)/',views.test),
反向解析
应用场景:
我们前面所写的路由实际上都把路由写死了,如果你的项目里面写了非常多
视图函数和HTML页面,它们都引用了同一个路由,这时候如果路由要改动,
那么你就要一个一个去修改视图函数和HTML页面中对应的路由的名字,这
一天天的也不用干别的了,就改吧,还容易出错,就没有什么好办法当路由
怎么变的时候,其他的东西都不会变吗?
当然是有的,就是我们接下来所要讲的反向解析
它实际上就是:根据名字动态获取到对应路径
反向解析的方法是给一个路由与视图函数的对应关系取别名,
然后视图函数与HTML都使用该别名来得到对应的路由,
由此实现动态获取路由。
from django.shortcuts import reverse url(r'^index6668888/$',views.index,name='index')
❗注意:
◾ 可以给每一个路由与视图函数对应关系起一个名字
◾ 这个名字能够唯一标识出对应的路径
◾ 这个名字不能重复是唯一的❗❗❗
使用反向解析的必备步骤

from django.shortcuts import reverse # 除了三剑客之外,再导入reverse
# url中用name属性给路由与视图函数对应关系取别名
url(r'index/', views.index, name='index')
# 视图函数中用reverse('别名')反向解析url路由
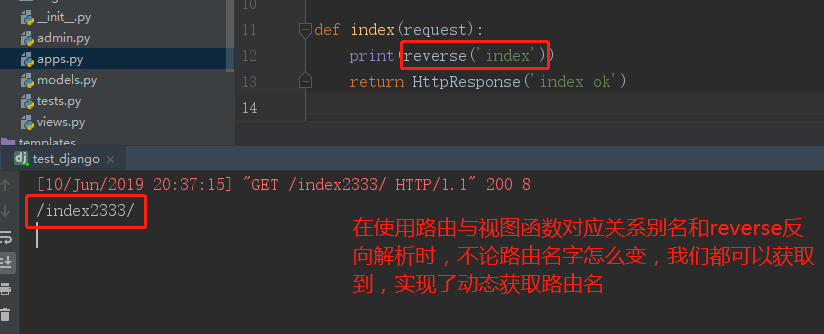
def index(request):
print(reverse('index'))
return HttpResponse('index ok')
🔹浏览器输入URL:http://127.0.0.1:8000/index/ 结果如下:
🔹修改url路由名字,视图函数不变
接下来我们修改一下url,让url本身就是不固定的(运用正则)
url(r'index/\d+/', views.index, name='index')
def index(request):
print(reverse('index'))
return HttpResponse('index ok')
浏览器输入URL:http://127.0.0.1:8000/index/233/结果如下:
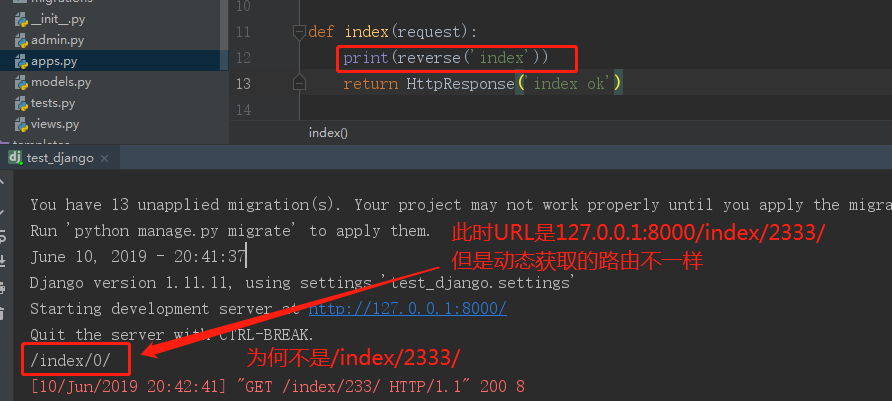
原来这个因为我们url正则中用的\d+,反向解析时根本不知道\d+是啥,
不知道该用什么替换。为了能够反向解析的路由一致,
我们必须在反向解析时告诉reverse \d+是什么。
修改路由(加上分组)及视图函数:
url(r'index/(\d+)/', views.index, name='index')
def index(request, id):
# reverse可以用args接收参数,但是要是元组,注意,单个元素的元组必须加个逗号!!!
print(reverse('index', args=(id, )))
return HttpResponse('index ok')
接下来输入同样的URL再看结果:
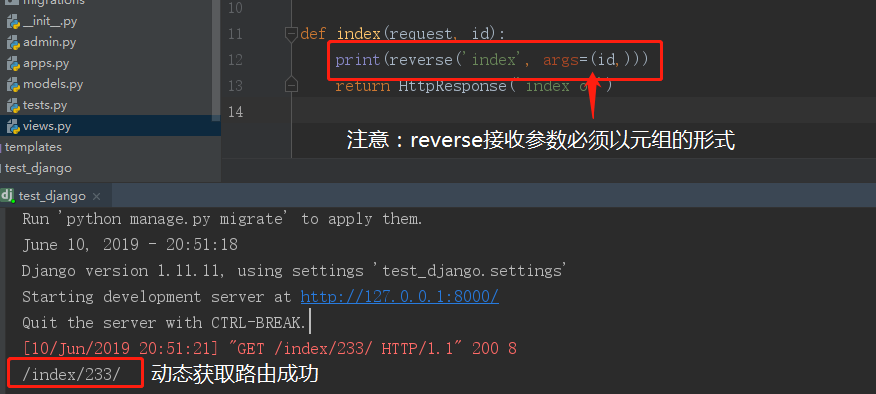
上述是运用分组来把\d+的内容通过参数的形式传给视图函数,
然后通过reverse的args传参把\d+的内容告诉reverse。
总结:
前端使用 {% url 'index' %} {% url '你给路由与视图函数对应关系起的别名' %} 后端使用 reverse('index') reverse('你给路由与视图函数对应关系起的别名')
无名分组反向解析


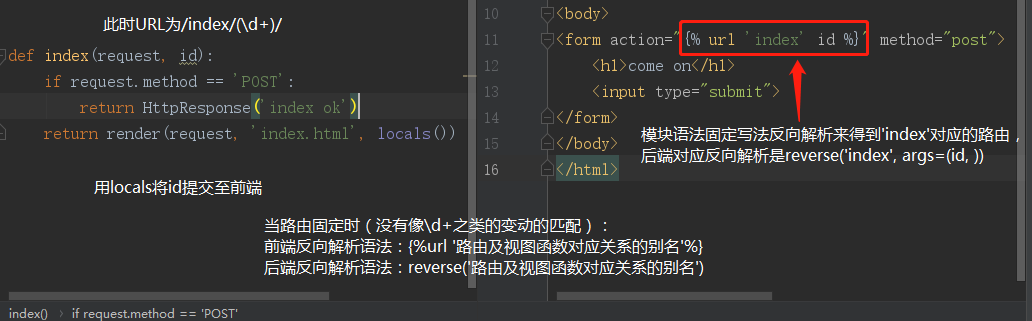
# 路由 url(r'index/(\d+)/', views.index, name='index') # 视图函数 def index(request, id): if request.method == 'POST': return HttpResponse('index ok') return render(request, 'index.html', locals()) #HTML代码(body标签内) <form action="{% url 'index' id %}" method="post"> <h1>come on</h1> <input type="submit"> </form>
◾路由
url(r'^test/(\d+)/',views.test,name='list')
◾后端使用
print(reverse('list',args=(10,)))
◾前端使用
{% url 'list' 10 %}
user_list = models.User.objects.all()
url(r'^edit/(\d+)/',views.edit,name='edit')
前端模板语法
{%for user_obj in user_list%}
<a href='edit/{{ user_obj.pk }}/'></a>
{% endfor %}
视图函数
from django.shortcuts import reverse def edit(request,edit_id): url = reverse('edit',args=(edit_id,))
模板
{% url 'edit' edit_id %}
有名分组反向解析
后端使用 # 后端有名分组和无名分组都可以用这种形式 print(reverse('list',args=(10,))) # 下面这个了解即可 print(reverse('list',kwargs={'year':10})) 前端使用 # 前端有名分组和无名分组都可以用这种形式 {% url 'list' 10 %} # 下面这个了解即可 {% url 'list' year=10 %}
与无名分组的反向解析的区别在于: 视图函数request后的形参名需要同分组名一致 reverse('index', kwargs={'id': 10}) 前端{% url 'index' id=10%}
不过有名分组的反向解析也采用无名分组解析的方式,
这就意味无论有名分组还是无名分组,
我们都可以统一用无名分组反向解析的方式。
总结:针对有名分组与无名分组的反向解析统一采用一种格式即可 后端 reverse('list',args=(10,)) # 这里的数字通常都是数据的主键值 前端 {% url 'list' 10 %} 反向解析的本质:就是获取到一个能够访问名字所对应的视图函数
路由分发
应用场景:
Django里每个app都可以有自己独立的urls.py,static,templates,既然它有独立的这些东西,那么它是不是可以自成一体呢?
答案是肯定的,它可访问自己的静态文件夹,自己的模板,那app里面的视图函数就可以调我app里面的视图函数,从而产生渲染,
那就相当于每个应用可以独立开了,那么一个庞大的项目就可以拆成每一个独立的小项目,每个程序员只完成他自己的那个app,
之后把每个app拿过来新建一个Django项目把这几个app往setting里面注册,总路由只需要路由分发即可,带着每个app应用的前缀,
来个路由分发就能够自动分发到所有app的urls.py里面,这样就相当于把几个小项目整合到一个大项目里面
django每一个app下面都可以有自己的urls.py路由层,
templates文件夹,static文件夹
项目名下urls.py(总路由)不再做路由与视图函数的匹配关系而是做路由的分发
from django.conf.urls import include # 路由分发 注意路由分发总路由千万不要$结尾 url(r'^app01/',include(app01_urls)), url(r'^app02/',include(app02_urls)) # 在应用下新建urls.py文件,在该文件内写路由与视图函数的对应关系即可 from django.conf.urls import url from app01 import views urlpatterns = [ url(r'^index/',views.index) ]
名称空间(了解)
直接看例子:
url(r'^app01/',include(app01_urls,namespace='app01')), url(r'^app02/',include(app02_urls,namespace='app02'))
app01.urls.py
from django.conf.urls import url from app01 import views urlpatterns = [ url(r'^index/',views.index,name='index') ]
app02.urls.py
from django.conf.urls import url from app02 import views urlpatterns = [ url(r'^index/',views.index,name='index') ]
app01.views.py
reverse('app01:index')
app02.views.py
reverse('app02:index')
伪静态网页
搜索优化seo,会优先加载静态的网页,所以静态网页优先级比较高,
我们可以仿静态网页来增加优先级,在路由后面加个.html
url(r'^index.html',views.index,name='app01_index')
虚拟环境
每一个项目都有属于自己的python环境,
避免导入多余的模块造成资源浪费
django1.0与django2.0之间的区别
# django2.0里面的path第一个参数不支持正则,
你写什么就匹配什么,100%精准匹配
# django2.0里面的re_path对应着django1.0里面的url
虽然django2.0里面的path不支持正则表达式,
但是它提供五个默认的转换器:
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式 int,匹配正整数,包含0。 slug,匹配字母、数字以及横杠、下划线组成的字符串。 uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。 path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
自定义转换器
1.正则表达式
2.类
3.注册
# 自定义转换器 class FourDigitYearConverter: regex = '[0-9]{4}' def to_python(self, value): return int(value) def to_url(self, value): return '%04d' % value # 占四位,不够用0填满,超了则就按超了的位数来! register_converter(FourDigitYearConverter, 'yyyy')
PS:路由匹配到的数据默认都是字符串形式
FBV与CBV
FBV:基于函数的视图
CBV:基于类的视图
无论是FBV还是CBV路由层都是路由对应视图函数内存地址
CBV:
首先我们在视图层views.py中写了一个类
from django.views import View # 需要导入View
class Index(View):
def get(self, request):
return render(request, 'index.html')
def post(self, request):
return HttpResponse('23333')
url中写路由与该类的对应关系
index.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>index</title> <script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script> <script src="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/js/bootstrap.min.js"></script> <link href="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/css/bootstrap.min.css" rel="stylesheet"> </head> <body> <form action="" method="post"> <h1>come on</h1> <input type="submit"> </form> </body> </html>
运行,通过路由分发找到该app01的index:
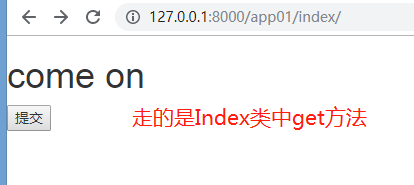
点提交:
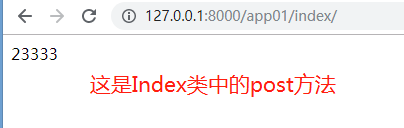
为什么定义一个继承Views的类,就可以根据请求方式自动走get或者post方法?
请往下看:
首先来看一下路由:url(r'^index/', views.Index.as_view()),Index
是我们自己定义的视图类,那么as_view很大概率是类方法。
as_view()就是执行该方法,查看一下该方法
❗注意:根据类中属性与方法的查找顺序,as_view方法Index类本身没有,
所以会找父类Views的as_view方法):


通过查看Views类中的as_view方法,发现它返回的是一个view函数名,
也就是view函数的内存地址,而当我们一个路由成功被匹配时,
会自动调用执行后面的视图函数。所以当我们
url(r'^index/', views.Index.as_view())被匹配成功时,
就相当于直接执行view()方法。接下来我们再看看view方法里面有啥。

再去dispath函数里面一探究竟:
因为该对象及其父类Index没有该方法,
所以最后会去Index的父类Views中找

这是Django所支持的八种请求方法:
![]()
总结:
- url中路由url(r'^index/', views.Index.as_view())成功匹配时,
会执行views.Index.as_view()(),as_views()返回的是view函数。
所以相当于执行views.view()。
- view函数执行返回的是一个对象方法——dispatch执行的结果。
- dispatch方法执行返回的handler函数的执行结果,而handler函数是
用反射从self对象名称空间里取出来的(再次涉及到属性查找顺序),
反射取的方法是根据小写的request.method。
- 我们自定义类中写了get和post函数,可以被反射取到并将该函数的
内存地址赋值给handler。
- handler执行的结果实际上就是我们定义的get或者post执行的结果,
然后通过dispatch继续return给view。所以view函数执行时
就相当于执行get或者post。
- 以上注意属性和方法(as_view及getattr反射)的查找顺序。
最后附一张关于request.method的图
(渣画质,想看仔细的话,可以自己试试):
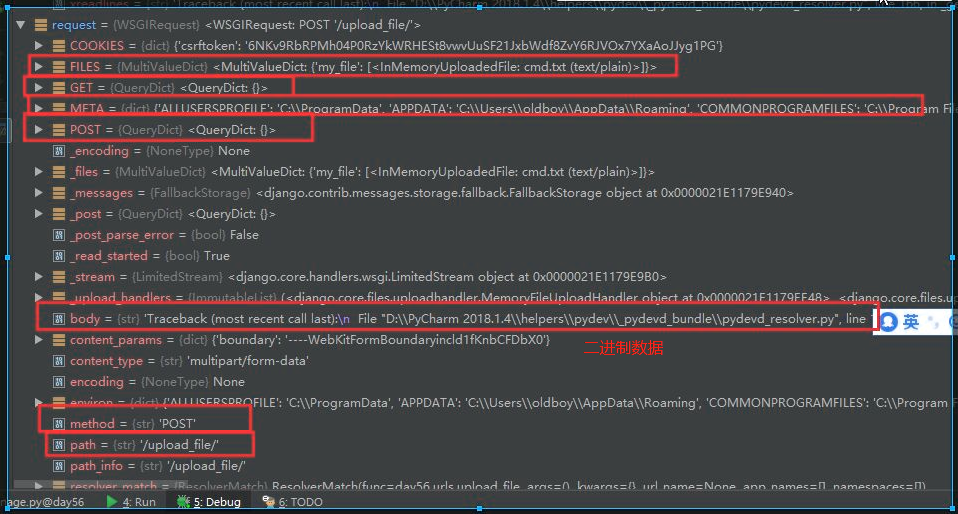
其中request.path和get_full_path的区别:
print('path:',request.path)
print('full_path:',request.get_full_path())
path: /upload_file/
full_path: /upload_file/?name=jason
大文件上传
注意事项:
前端需要注意的点:
1.method需要指定成post
2.enctype需要改为formdata格式
后端暂时需要注意的是
1.配置文件中注释掉csrfmiddleware中间件
2.通过request.FILES获取用户上传的post文件数据
file_obj = request.FILES.get('my_file')
print(file_obj.name)
with open(file_obj.name,'wb') as f:
for line in file_obj.chunks():
f.write(line)
整理的想吐。。。

