
第八篇:DRF之图书数据的增删查改【练习】
第八篇:DRF之图书数据的增删查改【练习】
目录
一、数据表
1、数据表的书写
为了进行测试,我们建立下面的数据表。
"""models.py"""
from django.db import models
# 表基类:因为许多表都有相同的字段
class BaseModel(models.Model):
# 默认是未删除状态
is_delete = models.BooleanField(default=False)
# auto_now_add=True 只要记录创建,不需要手动插入时间,自动把当前时间插入
create_time = models.DateTimeField(auto_now_add=True)
# auto_now=True,只要更新,就会把当前时间插入
last_update_time = models.DateTimeField(auto_now=True)
# 设置一些表相关
class Meta:
# 将表设置为抽象表,即不在数据库中建立该表
abstract = True
# 图书表
class Book(BaseModel):
# 设置主键id,
id = models.AutoField(primary_key=True)
"""
补充:
verbose_name 可以在admin中显示中文
help_text 可以在admin中显示更详细的提示
"""
# 表名
name = models.CharField(max_length=32, verbose_name='书名', help_text='这里填书名')
# 价格
price = models.DecimalField(max_digits=5, decimal_places=2)
"""
db_constraint = False 键是逻辑上的关联,实质上没有外键联系,增删不会受外键影响,但是并不影响orm查询
"""
# 一对多
publish = models.ForeignKey(to='Publish', on_delete=models.DO_NOTHING, db_constraint=False)
"""
当第三张表只有关联字段,不需要拓展字段时,用自动即可,否则手动。
"""
# 多对多
authors = models.ManyToManyField(to='Author', db_constraint=False)
# 表的相关配置
class Meta:
# admin中表明的显示
verbose_name_plural = '图书表'
# 表对象的显示
def __str__(self):
return self.name
# 与序列化展示,反序列化相关
@property # 可加装饰器,也可不加装饰器
def publish_name(self):
return self.publish.name
# 序列化展示作者列表信息
@property
def author_list(self):
# 拿到所有的作者查询集
author_queryset = self.authors.all()
return [
{'name': author_obj.name, 'sex': author_obj.get_sex_display()} for author_obj in author_queryset
]
# 出版社表
class Publish(BaseModel):
# 出版社名
name = models.CharField(max_length=32)
# 地址
addr = models.CharField(max_length=32)
# 表对象的显示
def __str__(self):
return self.name
# 作者表
class Author(BaseModel):
# 作者名
name = models.CharField(max_length=32)
# 性别
sex = models.IntegerField(choices=((1, '男'), (2, '女')))
"""
一对一也可以用: ForeignKey + unique
"""
detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE, db_constraint=False)
# 作者详情表
class AuthorDetail(BaseModel):
# 手机号
phone = models.CharField(max_length=11)
"""
注意事项:
1.使用db_constraint=False断开表关系之后,表之间没有外键关联,但是有外键逻辑关联(有充当外键的字段);
2.断关联后不会影响数据库查询效率,但是会极大提高数据库增删改效率,不影响增删改查操作;
3.断关联一定要通过逻辑保证表之间数据的安全,不要出现脏数据,要使用代码进行控制;
4.级联关系举例:
作者如果没了,详情也便没有:使用 on_delete=models.CASCADE
出版社没了,书还是那个出版社出版:on_delete=models.DO_NOTHING
部门如果没了,员工没有部门(空不能):null=True, on_delete=models.SET_NULL
部门如果没了,员工进入默认部门(默认值):default=0, on_delete=models.SET_DEFAULT
"""
2、admin注册
"""admin.py"""
from django.contrib import admin
# Register your models here.
from api import models
admin.site.register(models.Book)
admin.site.register(models.Publish)
admin.site.register(models.Author)
admin.site.register(models.AuthorDetail)
二、序列化组件
"""ser.py"""
from rest_framework import serializers
from api import models
# 写一个类,继ListSerializer,重写update
class BookListSerializer(serializers.ListSerializer):
"""重写其中的create方法,其内部已经书写,没有必要"""
"""
def create(self, validated_data):
return super().create(validated_data)
"""
# 重写update方法
def update(self, instance, validated_data):
# 参考源码的create方法 【self.child:是BookModelSerializer对象】
return [
self.child.update(instance[i], attrs) for i, attrs in enumerate(validated_data)
]
# 写一个序列化器【如果序列化的是数据库的表,尽量用ModelSerializer】
class BookModelSerializer(serializers.ModelSerializer):
"""第一种方案:只序列化可以,但是反序列化有问题"""
# publish = serializers.CharField(source='publish.name')
"""第二种方案:models数据表中写方法显示"""
class Meta:
# 为了批量修改数据使用,为了重写其中的update方法,替换类
list_serializer_class = BookListSerializer
model = models.Book
# fields = '__all__'
# depth = 1 # 一般不使用
fields = ('name', 'price', 'authors', 'publish', 'publish_name', 'author_list')
# 添加额外的属性
extra_kwargs = {
'publish': {'write_only': True}, # 写的时候写
'publish_name': {'read_only': True}, # 读的时候读
'authors': {'write_only': True}, # 写的时候写
'author_list': {'read_only': True} # 读的时候读
}
三、路由配置
为了更好的符合restful规范,我们使用路由分发。
"""主路由"""
from django.conf.urls import url, include
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 使用路由分发,可以更好的符合restful规范
url(r'^api/', include('api.urls'))
]
"""api应用下的路由"""
from django.conf.urls import url
from api import views
urlpatterns = [
url(r'^books/$', views.BookAPIView.as_view()), # 因为正则路由配置问题,才导致匹配不到第二条
url(r'^books/(?P<pk>\d+)/', views.BookAPIView.as_view())
]
四、视图类的书写
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from api import models
from api.ser import BookModelSerializer
# Create your views here.
class BookAPIView(APIView):
"""查询单条数据,和多条数据"""
def get(self, request, *args, **kwargs):
# 查询一个
pk = kwargs.get('pk')
if pk:
# 根据pk,拿到书籍对象
book_obj = models.Book.objects.filter(id=pk).first()
# 单个对象,序列化
book_ser = BookModelSerializer(book_obj)
else:
# 查询所有
book_queryset = models.Book.objects.all().filter(is_delete=False)
# 进行序列化
book_ser = BookModelSerializer(book_queryset, many=True)
# 返回序列化后的数据
return Response(data=book_ser.data)
"""增加单条数据,和多条数据"""
def post(self, request, *args, **kwargs):
# 如果是单条数据
if isinstance(request.data, dict):
book_ser = BookModelSerializer(data=request.data)
# 校验数据
book_ser.is_valid(raise_exception=True)
# 保存数据,调用内部的create方法
book_ser.save()
# 返回创建的数据
return Response(data=book_ser.data)
# 如果是多条数据
elif isinstance(request.data, list):
# 进行序列化【此时的book_ser是ListSerializer对象】 from rest_framework.serializers import ListSerializer
from rest_framework.serializers import ListSerializer
book_ser = BookModelSerializer(data=request.data, many=True)
# 校验数据
book_ser.is_valid(raise_exception=True)
# 保存数据,调用内部的create方法
book_ser.save()
# 返回创建的数据
return Response(data=book_ser.data)
"""修改单条数据,和多条数据"""
def put(self, request, *args ,**kwargs):
# 修改一个数据
pk = kwargs.get('pk')
# 如果修改单个数据
if pk:
book_obj = models.Book.objects.filter(pk=pk).first()
# 进行反序列化
"""partial=True是当修改的数据不完整的时候,使用的"""
book_ser = BookModelSerializer(instance=book_obj, data=request.data, partial=True)
# 校验
book_ser.is_valid(raise_exception=True)
# 保存数据,调用内部的update方法
book_ser.save()
# 返回修改的数据
return Response(data=book_ser.data)
# 批量修改多条数据
else:
"""
前端传过来的数据 [{id:1,name:xx,price:xx},{id:1,name:xx,price:xx}]
处理传入的数据 对象列表[book1,book2] 修改的数据列表[{name:xx,price:xx},{name:xx,price:xx}]
"""
# 定义一个书籍对象里欸包
book_obj_list = []
# 修改的数据列表
modify_data = []
# 对前端传过来的数据进行处理
for book_info in request.data:
# {id:1,name:xx,price:xx}
pk = book_info.pop('id') # 除掉id,并复制给pk
book_obj = models.Book.objects.filter(pk=pk).first()
book_obj_list.append(book_obj)
modify_data.append(book_info)
"""第一种方案:for循环一个一个修改"""
"""
for index, data in enumerate(modify_data):
# 单条进行修改
book_ser = BookModelSerializer(instance=book_obj_list[index], data=data)
book_ser.is_valid(raise_exception=True)
book_ser.save()
return Response(data='修改单条数据成功')
"""
"""第二种方案:重写ListSerializer的update方法"""
book_ser = BookModelSerializer(instance=book_obj_list, data=modify_data, many=True)
book_ser.is_valid(raise_exception=True)
# 保存数据,调用自定义的update方法
book_ser.save()
# 返回修改的数据
return Response(data=book_ser.data)
"""删除一条数据,或者多条"""
def delete(self, request, *args, **kwargs):
# 拿到单条删除的pk
pk = kwargs.get('pk')
# 不管单条删除还是多条删除,都用多条 删除
pks = []
if pk:
pks.append(pk)
else:
pks = request.data.get('pks')
# 删除将把is_delete设置成true,ret返回受影响的行数
ret = models.Book.objects.filter(pk__in=pks, is_delete=False).update(is_delete=True)
# 如果删除
if ret:
return Response(data={'msg': '删除成功'})
else:
return Response(data={'msg': '没有要删除的数据'})
五、效果展示
1、查询单条数据
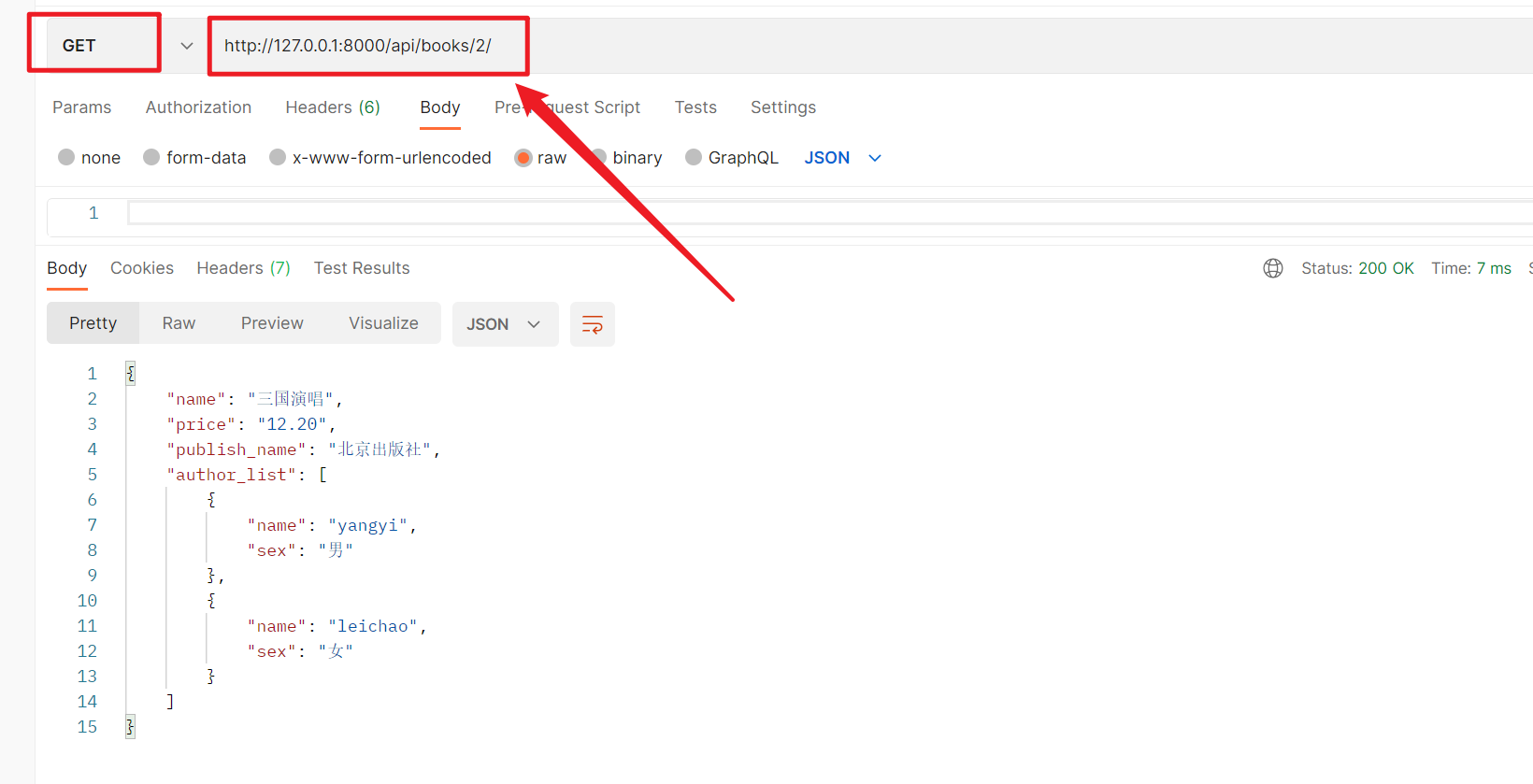
2、查询所有数据
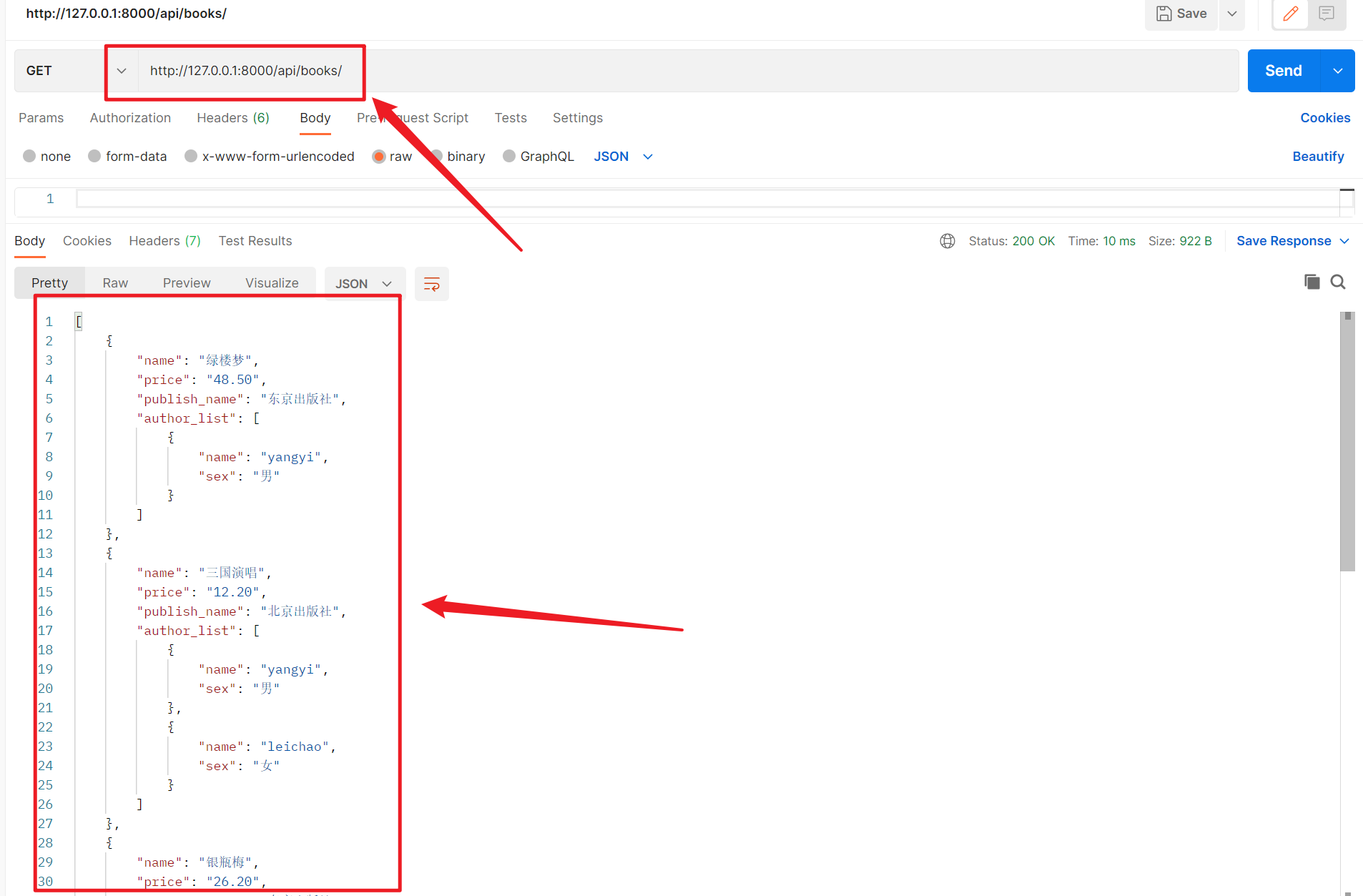
3、增加单条数据
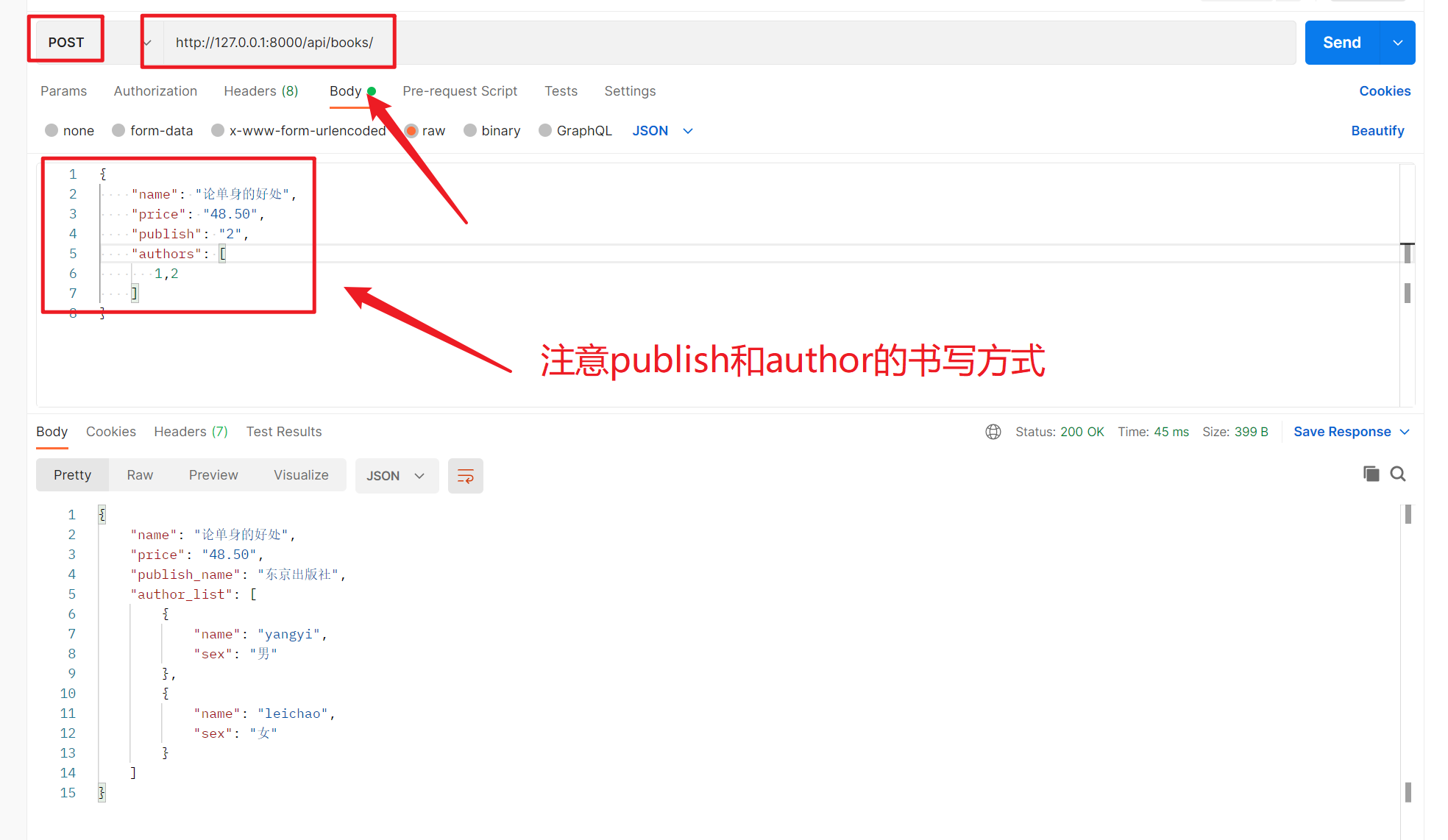
4、增加多条数据
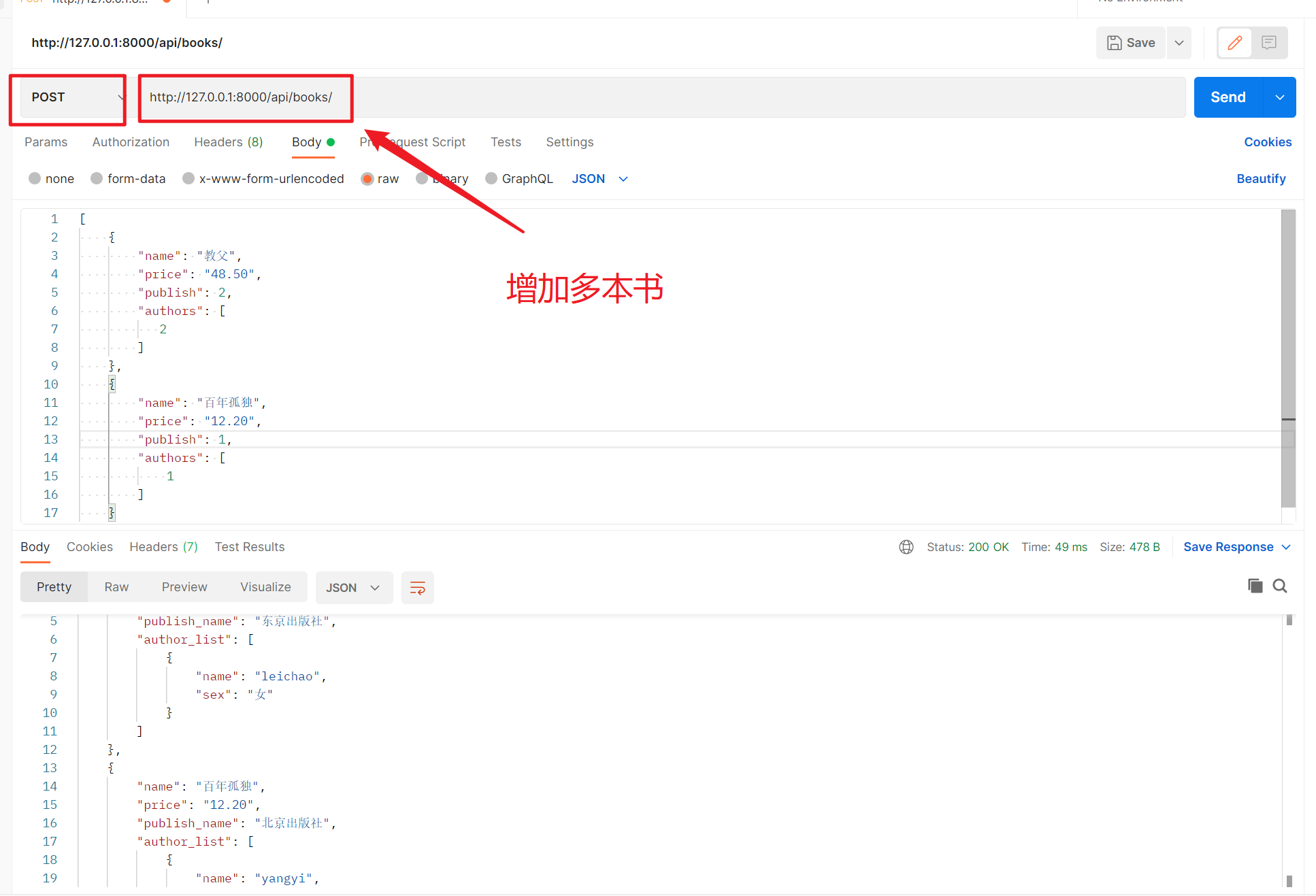
5、修改单条数据
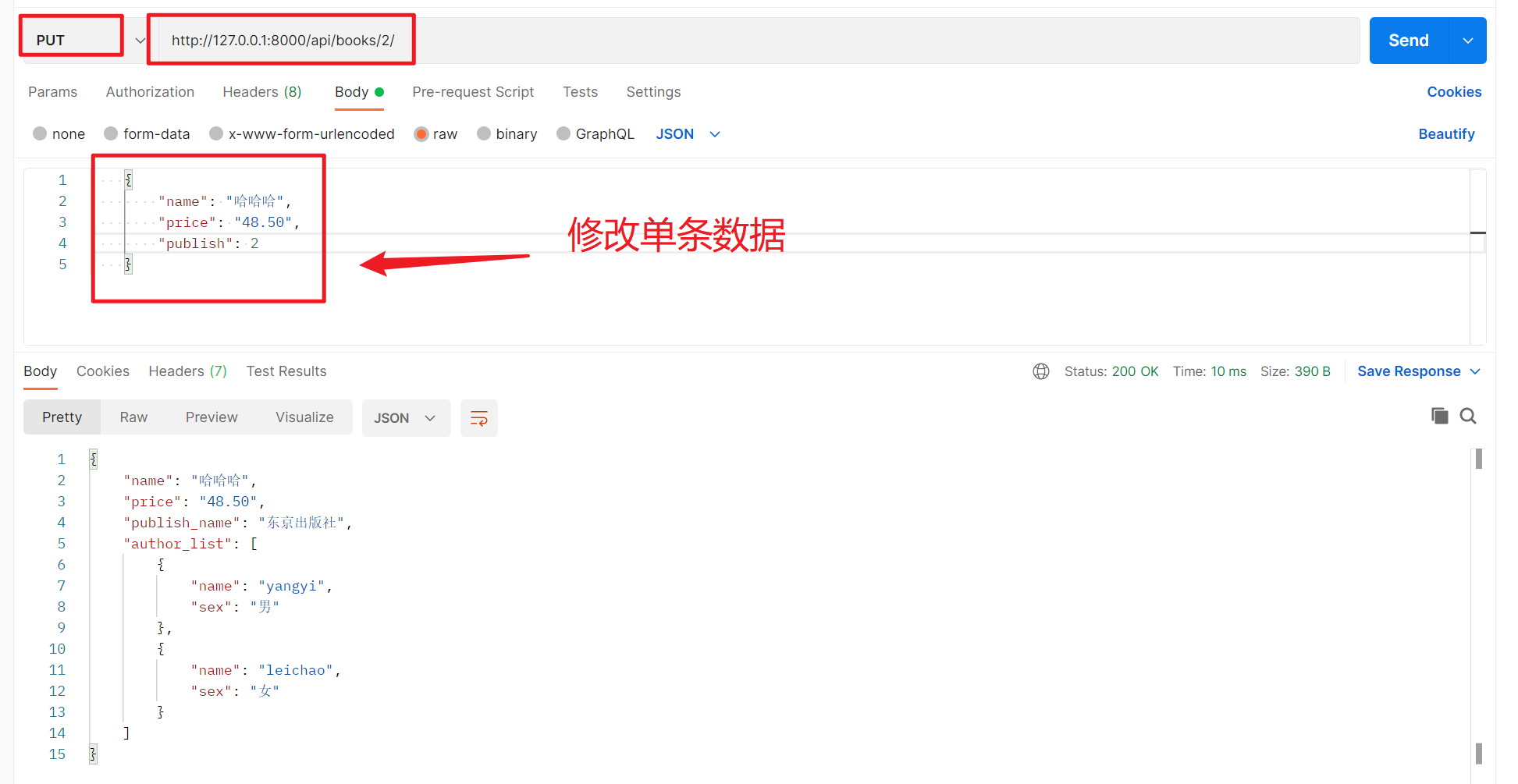
6、修改多条数据
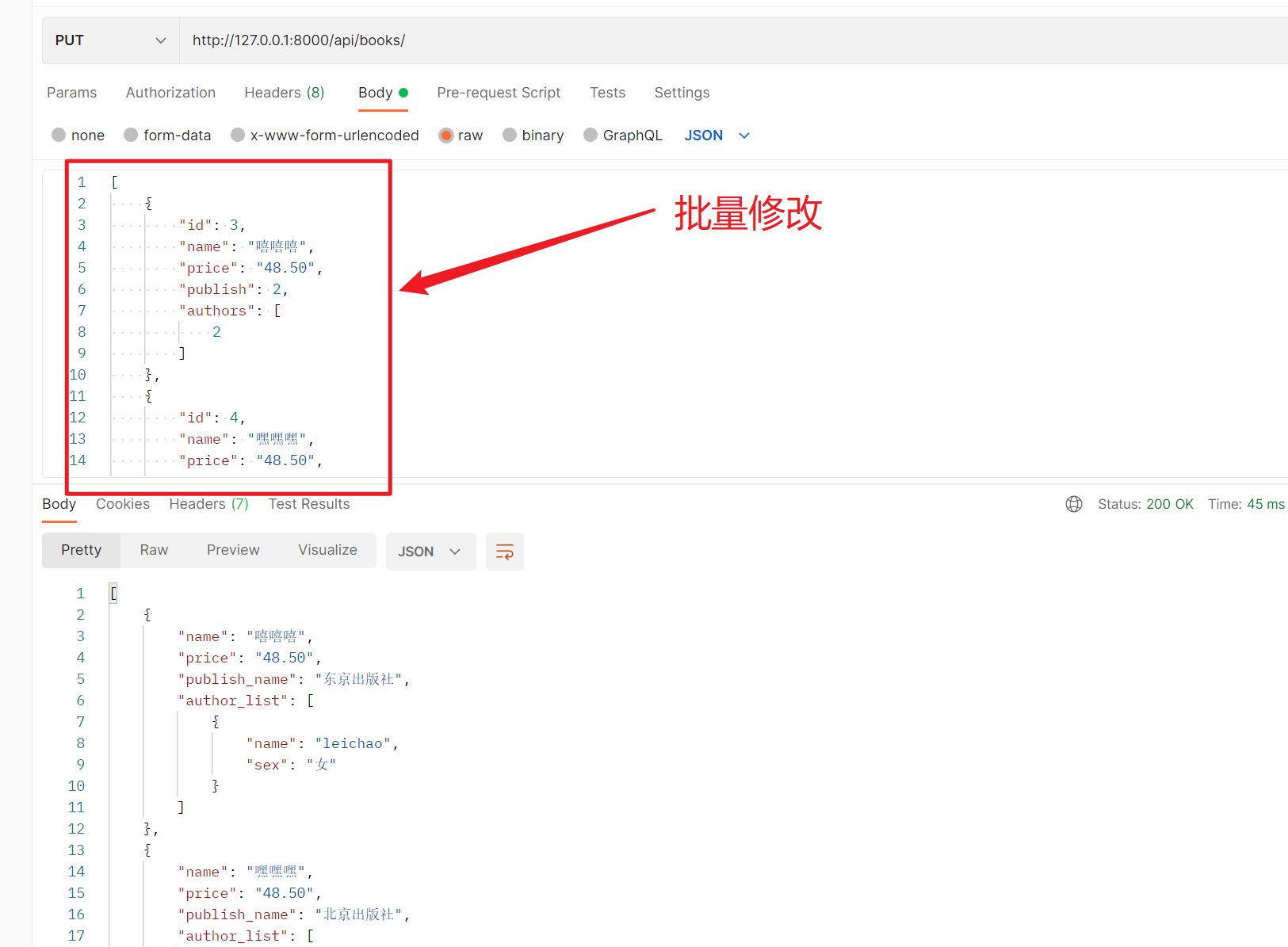
7、删除一条数据
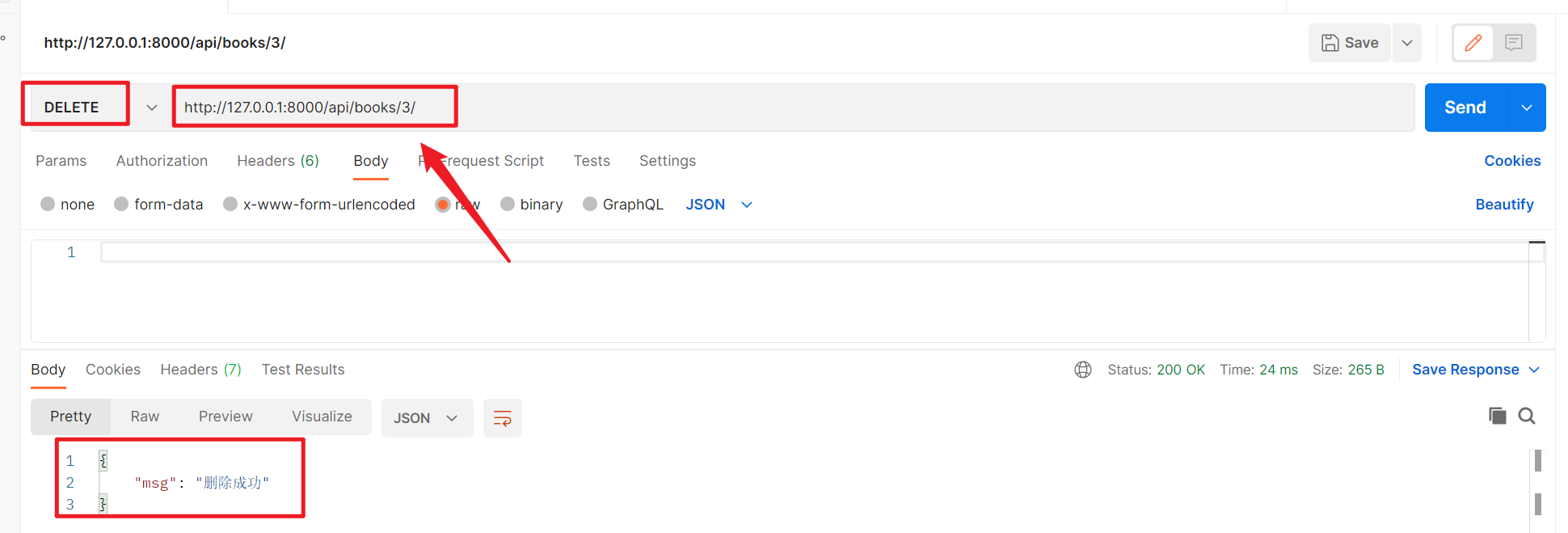
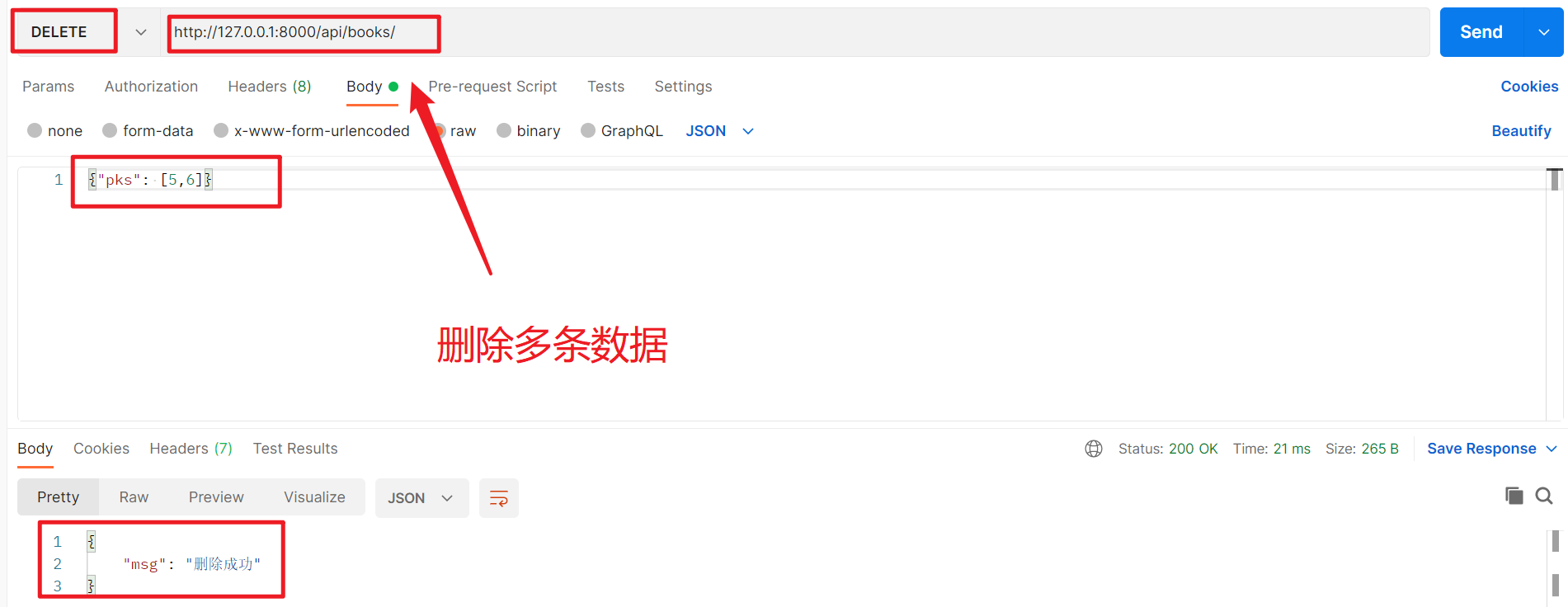
8、删除多条数据
分类:
DRF


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人