第二篇:DRF之序列化组件
第二篇:DRF之序列化组件
一、序列化器-Serializer
1、作用
1. 序列化:序列化器会把表模型对象转换成字典,经过response以后返回json字符串
2. 反序列化:把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
3. 反序列化:完成数据校验功能
# 不准确来说:序列化的时候看字段类型;反序列化的时候看字段参数和全局局部钩子
2、序列化器的简单使用
Django REST framework中的Serializer使用类来进行定义。
我们先使用如下的方式进行测试。
- urls.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 测试序列化组件
url(r'^books/(?P<pk>\d+)/', views.BookView.as_view())
]
- ser.py
from rest_framework import serializers
# 定义一个书籍的序列化类
class BookSerializer(serializers.Serializer):
id = serializers.CharField()
title = serializers.CharField() # 将数据对象中的字段序列化成字符类型
price = serializers.CharField() # 有很多类型的字段
author = serializers.CharField()
publish = serializers.CharField()
- views.py
from rest_framework.views import APIView
from app01.ser import BookSerializer
from app01 import models
from rest_framework.response import Response
class BookView(APIView):
def get(self, request, pk):
# 根据pk拿到书籍对象
book_obj = models.Book.objects.filter(id=pk).first()
# 用一个类,毫无疑问,一定要实例化;要序列化谁,就把谁作为参数传进来
book_ser = BookSerializer(book_obj) # 调用类的__init__方法
"""
Response继承了HttpResponse的类
book_ser.data 就是序列化后的数据字典
"""
return Response(book_ser.data) # 将序列化对象的data数据使用返回;
# return JsonResponse(book_ser.data)
好了,我们在浏览器中输入http://127.0.0.1:8000/books/2/,我们可以得到如下界面。
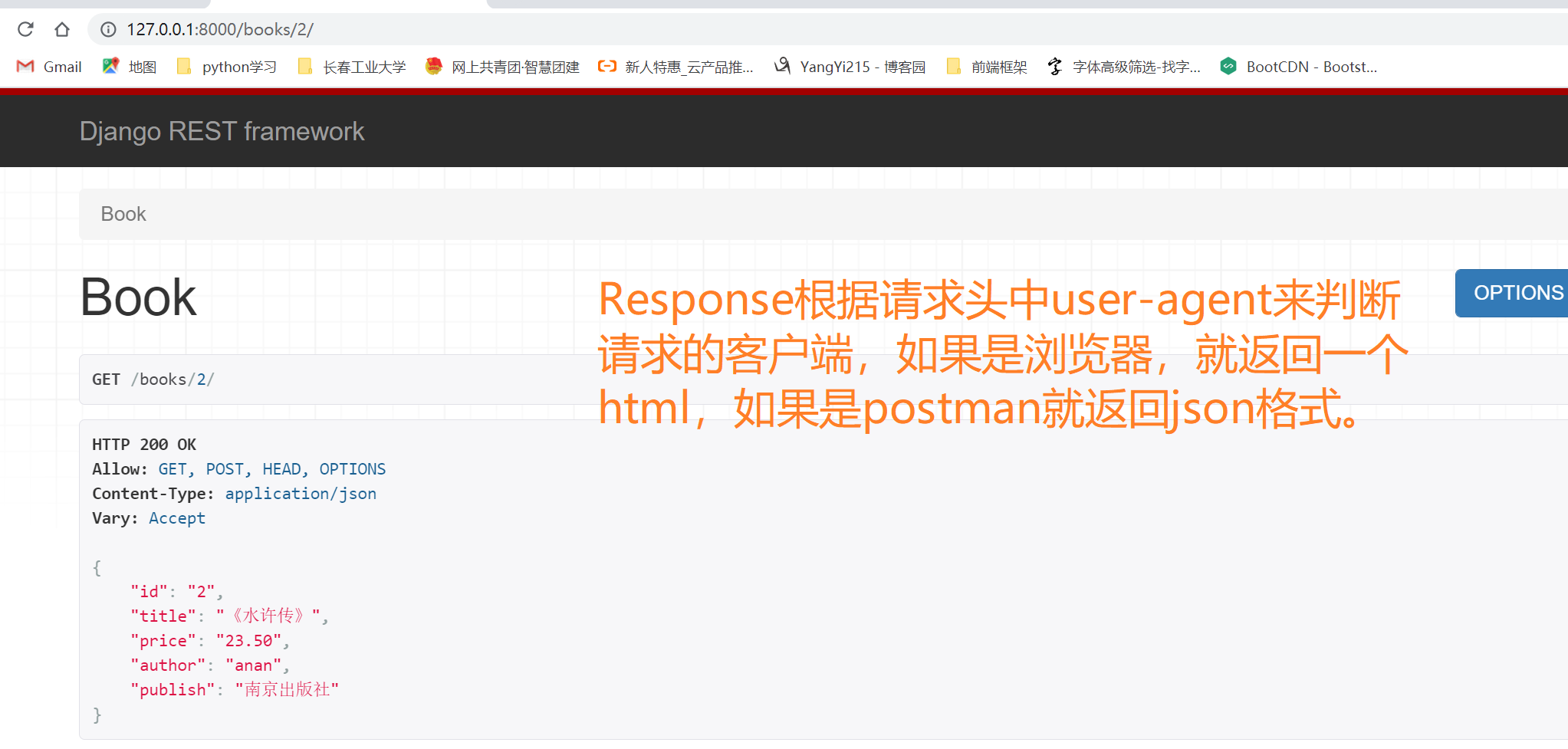
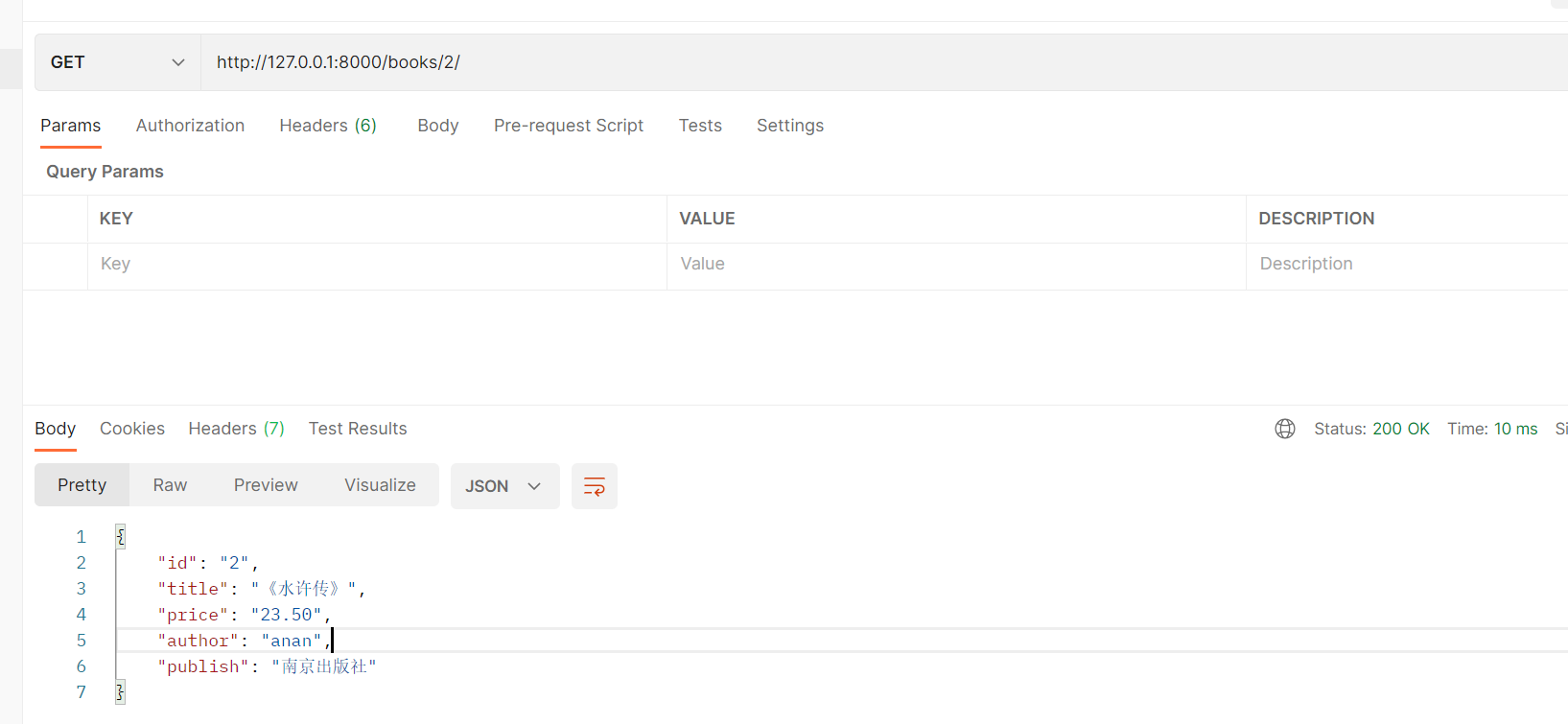
使用postman进行访问,结果如下所示。
使用步骤
1 写一个序列化的类,继承Serializer
2 在类中写要序列化的字段,想序列化哪个字段,就在类中写哪个字段
3 在视图类中使用,导入--》实例化得到序列化类的对象,将要序列化的对象传入
4 序列化类的对象.data 是一个序列化后的数据字典
5 把字典返回,如果不使用rest_framework提供的Response,就得使用JsonResponse
3、序列化类的字段类型
"""有很多,只需要记住下面几个即可。"""
CharField
IntegerField
DateField
4、序列化组件修改数据
简单来说,就是反序列化。拿到前端传过来的json格式数据,反序列化成数据对象,然后进行相应的修改保存删除等操作。
"""步骤"""
1 写一个序列化的类,继承Serializer
2 在类中写要反序列化的字段,想反序列化哪个字段,就在类中写哪个字段,字段的属性(max_lenth......)
max_length 最大长度
min_lenght 最小长度
allow_blank 是否允许为空
trim_whitespace 是否截断空白字符
max_value 最小值
min_value 最大值
# 额外补充:id = serializers.CharField(read_only=True) 当设置为read_only=True,反序列化时就不需要传该字段了
# read_only=True,序列化的时候显示,反序列化的时候不需要传该字段
# write_only=True,序列化的时候不显示,反序列化的时候需要传入该字段
3 在视图类中使用,导入--》实例化得到序列化类的对象,把要要修改的对象传入,修改的数据传入
book_ser = BookSerializer(instance=book_obj, data=request.data)
4 数据校验 if boo_ser.is_valid()
5 如果校验通过,就保存
book_ser.save() # 注意不是book.save()
6 如果不通过,逻辑自己写
7 如果字段的校验规则不够,可以写钩子函数(局部和全局)
-
修改一本书
修改书需要进行put提交方式进行,【类似于原生的django的post,可以json格式的数据发往后端,使用request.data获取数据】
我们使用如下代码进行测试。
"""ser.py"""
from rest_framework import serializers
# 定义一个书籍的序列化类
class BookSerializer(serializers.Serializer):
id = serializers.CharField()
title = serializers.CharField(max_length=8, min_length=3)
price = serializers.CharField()
author = serializers.CharField()
publish = serializers.CharField()
# 重写父类的update方法
def update(self, instance, validated_data):
"""
instance:要修改的实例化对象
validated_data: 类似form中的cleaned_data,为反序列化后校验通过的数据
"""
instance.title = validated_data.get('title')
instance.price = validated_data.get('price')
instance.author = validated_data.get('author')
instance.publish = validated_data.get('publish')
# django中orm提供的对象保存方法
instance.save()
return instance # 必须返回,不然报错
"""views.py"""
from rest_framework.views import APIView
from app01.ser import BookSerializer
from app01 import models
from rest_framework.response import Response
class BookView(APIView):
def get(self, request, pk):
# 根据pk拿到书籍对象
book_obj = models.Book.objects.filter(id=pk).first()
# 用一个类,毫无疑问,一定要实例化;要序列化谁,就把谁作为参数传进来
book_ser = BookSerializer(book_obj) # 调用类的__init__方法
"""
Response继承了HttpResponse的类
book_ser.data 就是序列化后的数据字典
"""
return Response(book_ser.data) # 将序列化对象的data数据使用返回;
# return JsonResponse(book_ser.data)
# put请求:修改书的对象
def put(self, request, pk):
# 返回给前端的接口数据
back_dic = {
'status': 1000,
'msg': ''
}
# 根据pk拿到书籍对象
book_obj = models.Book.objects.filter(id=pk).first()
# 对传过来的数据,传入序列化组件中
"""
instance: 需要修改的实例化的数据对象
data:put请求传过来的数据
"""
book_ser = BookSerializer(instance=book_obj, data=request.data)
# 判断反序列化后的数据是否符合要求【类似form组件】
if book_ser.is_valid(): # Ture表示校验正确
print('数据合法')
"""序列化的对象,调用save方法,方法中又调用了BookSerializer中的update方法,保存了数据"""
book_ser.save() # 报错【如果不写update会报错,内部执行了序列化组件中的update方法】
back_dic['msg'] = '操作成功'
back_dic['data'] = book_ser.data
else:
print('数据不合法')
back_dic['status'] = 2000
back_dic['msg'] = '数据校验失败'
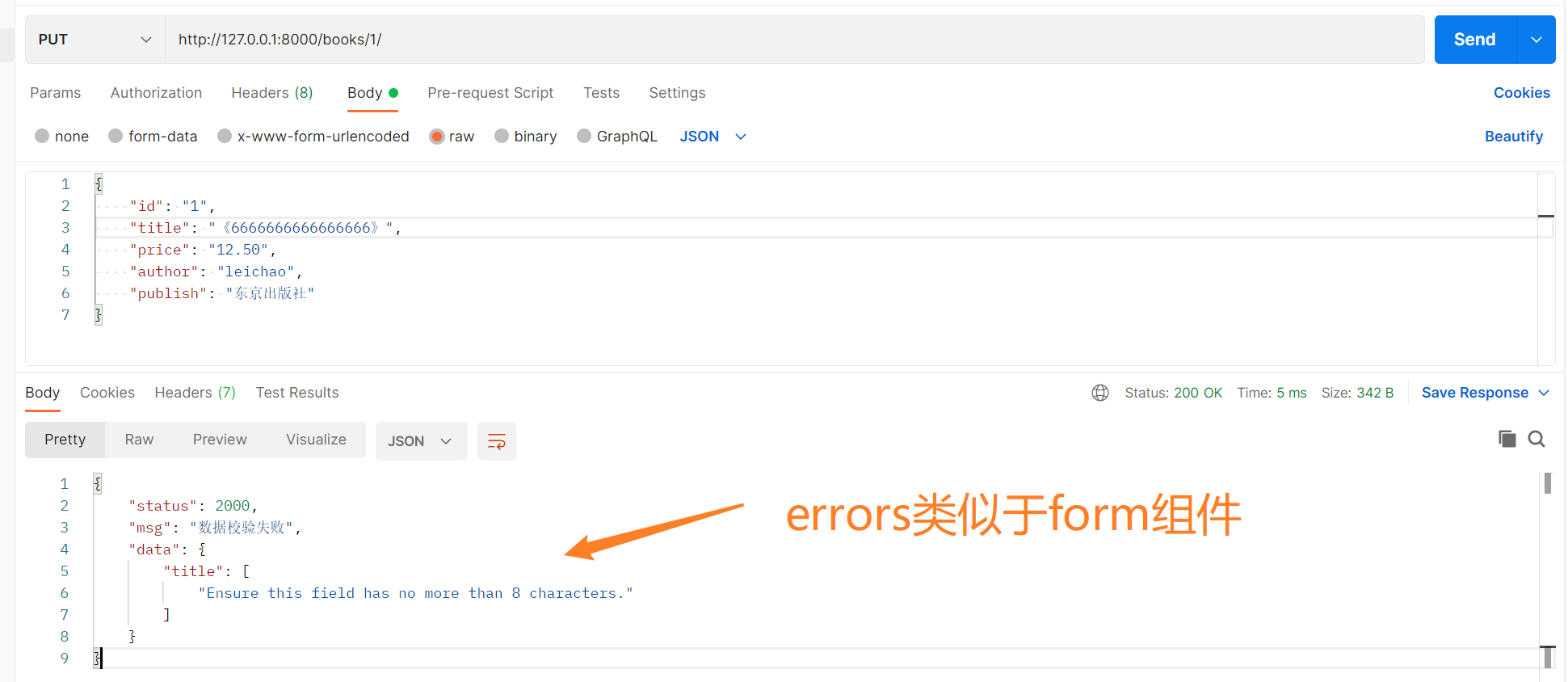
back_dic['data'] = book_ser.errors # 参考form组件
return Response(back_dic)
我们必须在BookSerializer类中重写父类的update方法。【python中虽然是鸭子类型,书写代码少,但也会因此带来一些缺陷,不方便进行统一规范,解决方法有两个:(1 使用abc模块,强制进行规定子类的方法 ; 2 如果子类中没有书写需要的方法,直接进行报错处理)】,drf中使用了报错处理raise NotImplementedError。
演示效果如下。
使用put方法,成功修改数据的情况。
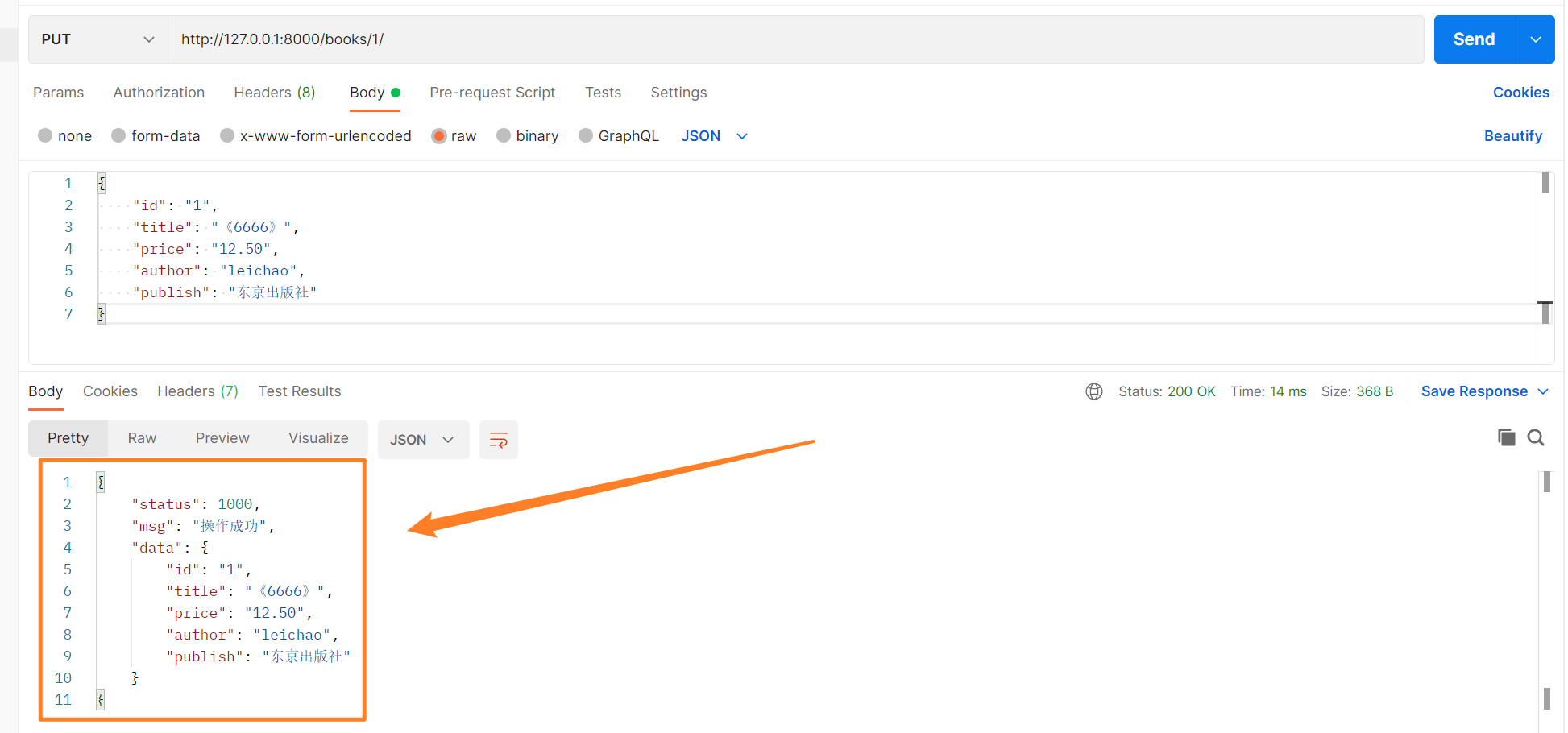
失败情况下,显示效果如下所示。
5、局部钩子和全局钩子
如果字段的校验规则不够,我们可以书写局部钩子和全局钩子进行相应的校验。
局部钩子和全局钩子是对反序列化传过来的数据进行校验。
-
局部钩子
校验价格不能少于10元,我们使用下面的代码来完成局部钩子的校验,代码如下。
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
# 定义一个书籍的序列化类
class BookSerializer(serializers.Serializer):
id = serializers.CharField()
title = serializers.CharField(max_length=8, min_length=3)
price = serializers.CharField()
author = serializers.CharField()
publish = serializers.CharField()
# 局部钩子【使用put修改数据,如果价格少于10元,则校验不通过】
def validate_price(self, data): # # validate_字段名 接收一个参数
"""注意:此时的data已经不是data=form.data,而是price的data,drf做了一个处理"""
print(data, type(data)) # 9.50 <class 'str'>
if float(data) > 10:
return data # 和form组件类似,钩出来数据之后必须返回数据
else:
# 校验失败,抛异常
raise ValidationError('价格太低')
测试的效果如下。

-
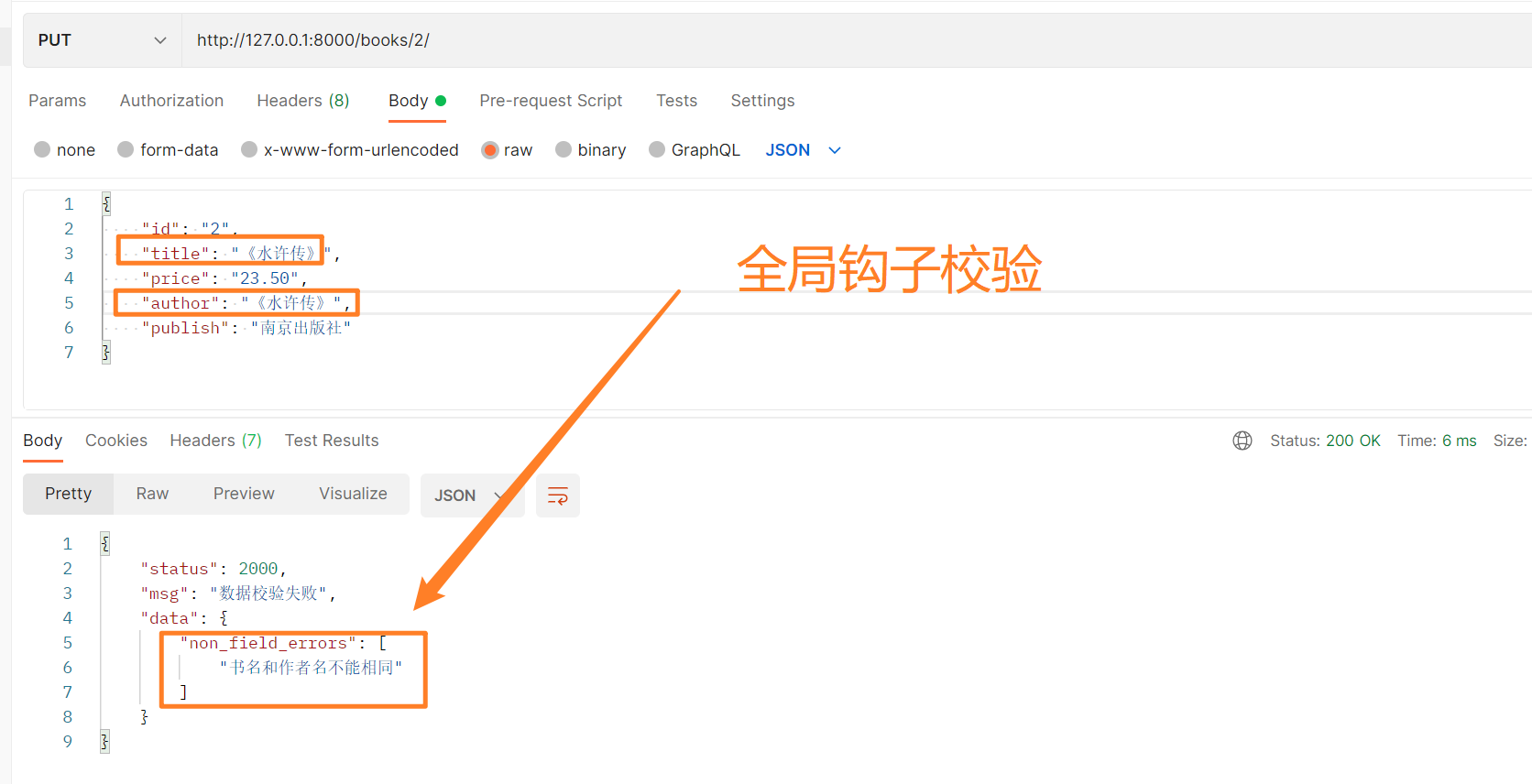
全局钩子
校验书名和作者名不能相同,涉及两个字段,使用全局钩子,代码如下。
# 定义一个书籍的序列化类
class BookSerializer(serializers.Serializer):
id = serializers.CharField()
title = serializers.CharField(max_length=8, min_length=3)
price = serializers.CharField()
author = serializers.CharField()
publish = serializers.CharField()
# 全局钩子【如果书名和作者名一样,则校验失败】
def validate(self, validate_data):
print(validate_data) # 类似于cleaned_data是一个过滤后的字典
title = validate_data.get('title')
author = validate_data.get('author')
# 如果相等,抛异常
if title == author:
raise ValidationError('书名和作者名不能相同')
else:
return validate_data
测试效果如下所示。
-
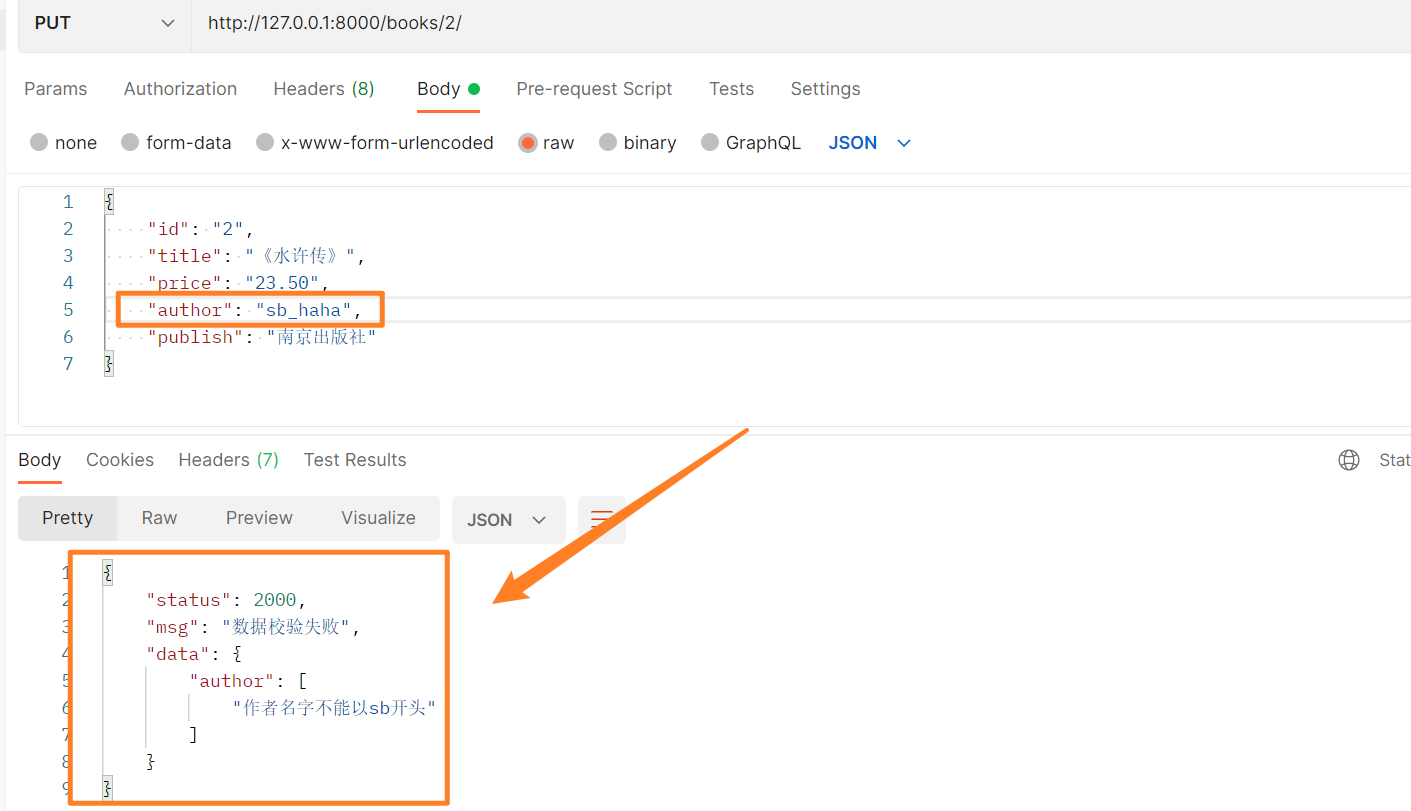
validators=[check_author] 校验
校验作者名不能以sb_开头。
"""自定义函数"""
def check_author(data):
if data.startswith('sb'):
raise ValidationError('作者名字不能以sb开头')
else:
return data
"""BookSerializer类中字段"""
# 定义一个书籍的序列化类
class BookSerializer(serializers.Serializer):
id = serializers.CharField()
title = serializers.CharField(max_length=8, min_length=3)
price = serializers.CharField()
# validators验证
author = serializers.CharField(validators=[check_author])
publish = serializers.CharField()
校验效果如下所示。
6、read_only和write_only
"""掌握"""
# read_only
表明该字段仅用于序列化输出,默认False,如果设置成True,postman中可以看到该字段,修改时,不需要传该字段。【序列化的时候显示,反序列化的时候不需要传入】
# write_only
表明该字段仅用于反序列化输入,默认False,如果设置成True,postman中看不到该字段,修改时,该字段需要传
"""了解"""
# required
表明该字段在反序列化时必须输入,默认True
# default
反序列化时使用的默认值
# allow_null
表明该字段是否允许传入None,默认False
# validators
该字段使用的验证器【上面的函数验证】
# error_messages
包含错误编号与错误信息的字典
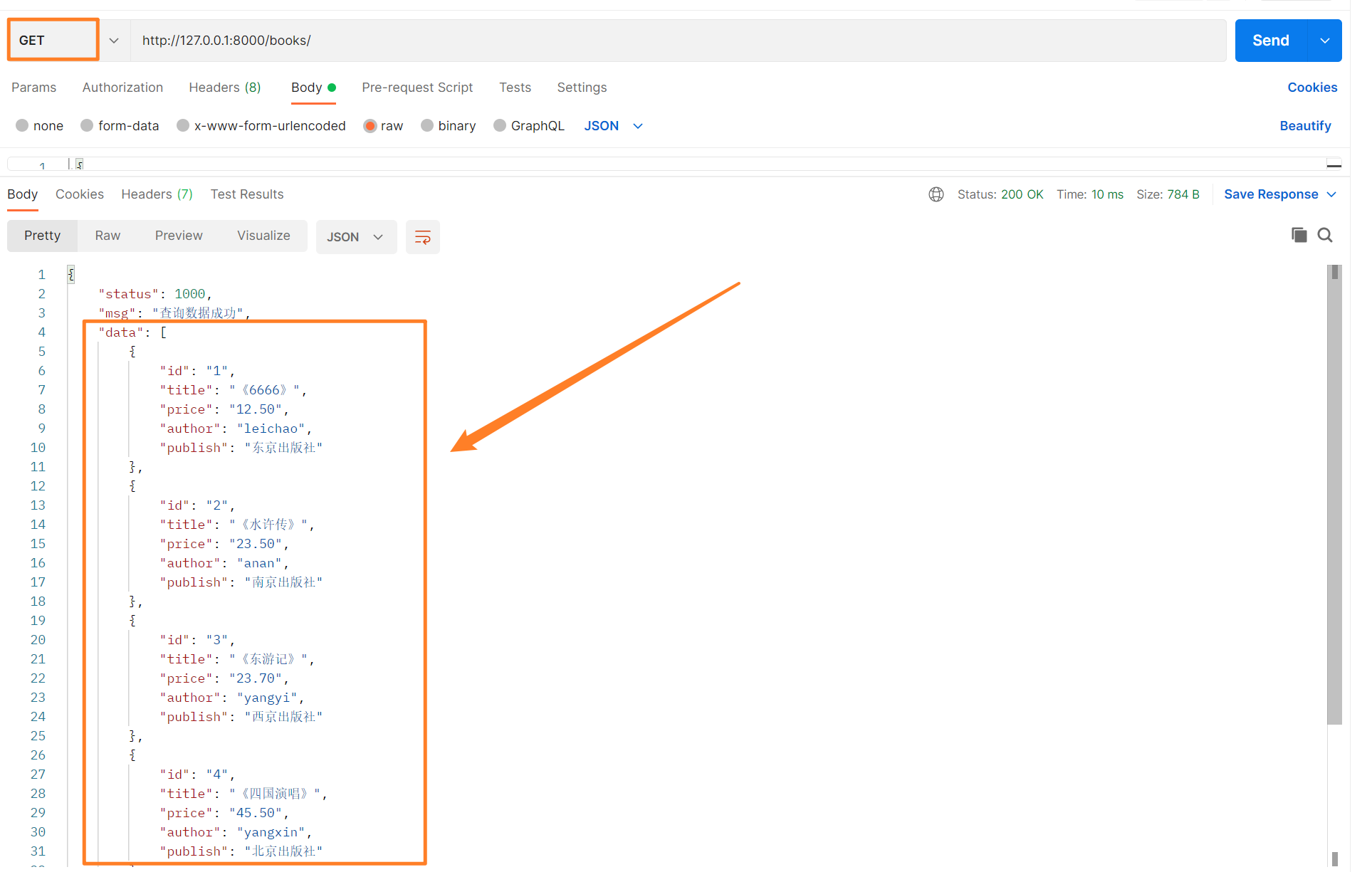
7、查询所有的数据
根据restful规范,我们查看所有数据时,以get方式提交,后面不需要传递主键值,http://127.0.0.1:8000/books/即可。
路由配置如下。
- urls.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 查询所有的数据
url(r'^books/', views.BookViews.as_view()) # 不需要数据的pk值
]
- views.py
# 查询所有的数据 添加数据【不需要pk的操作】
class BookViews(APIView):
# 查询所有的数据,并不要pk值
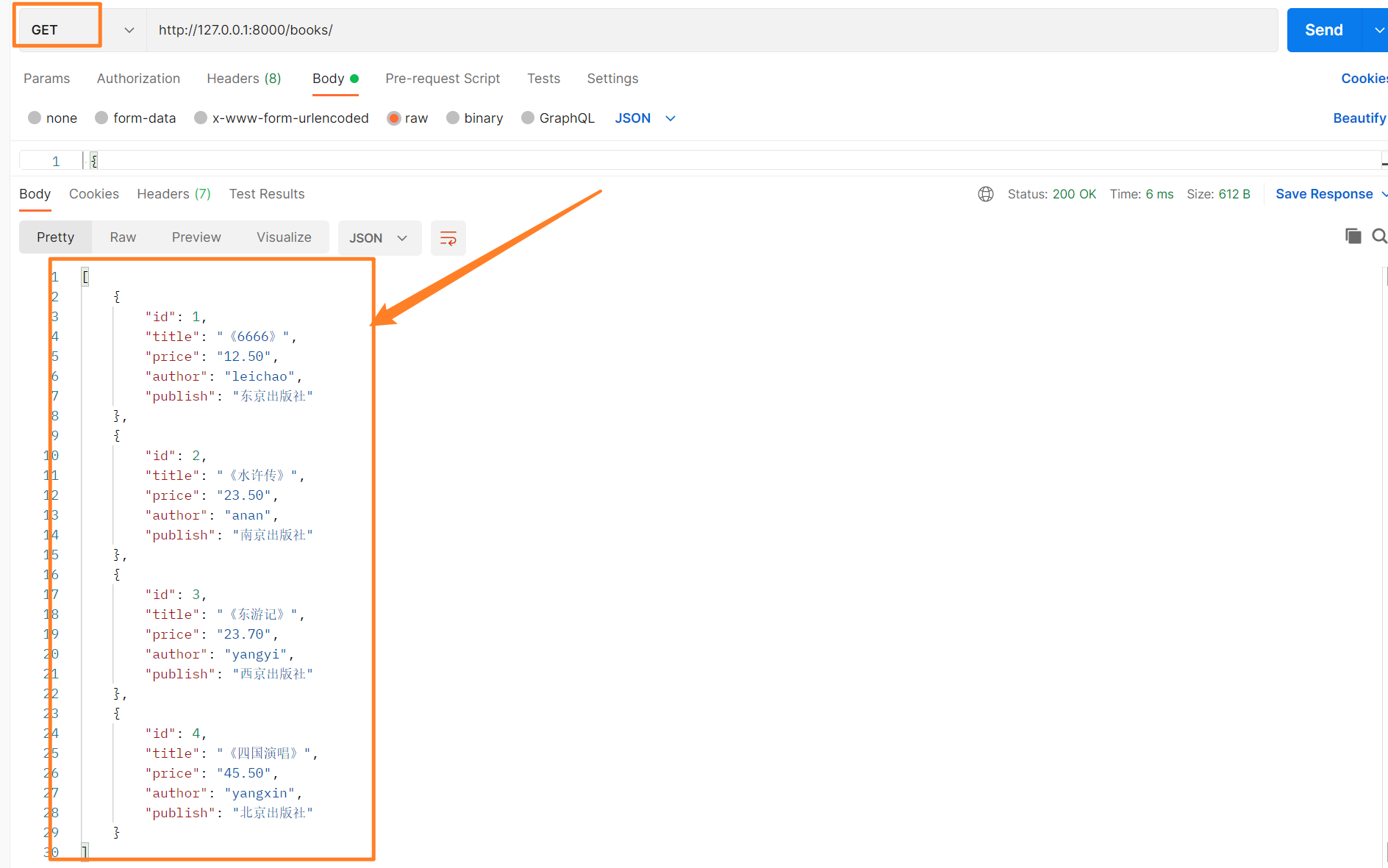
def get(self, request):
# 返回的数据
back_dic = {'status': 1000, 'msg': '查询数据成功'}
# 拿到所有的书籍查询集
book_queryset = models.Book.objects.all()
# 进行序列化【当需要查看多个数据的时候,需要添加many=True】
books_ser = BookSerializer(book_queryset, many=True)
# 进行查询数据的添加
back_dic['data'] = books_ser.data
# 进行数据的返回
return Response(back_dic)
- ser.py
# 定义一个书籍的序列化类
class BookSerializer(serializers.Serializer):
id = serializers.CharField()
title = serializers.CharField()
price = serializers.CharField()
author = serializers.CharField()
publish = serializers.CharField()
效果如下所示。
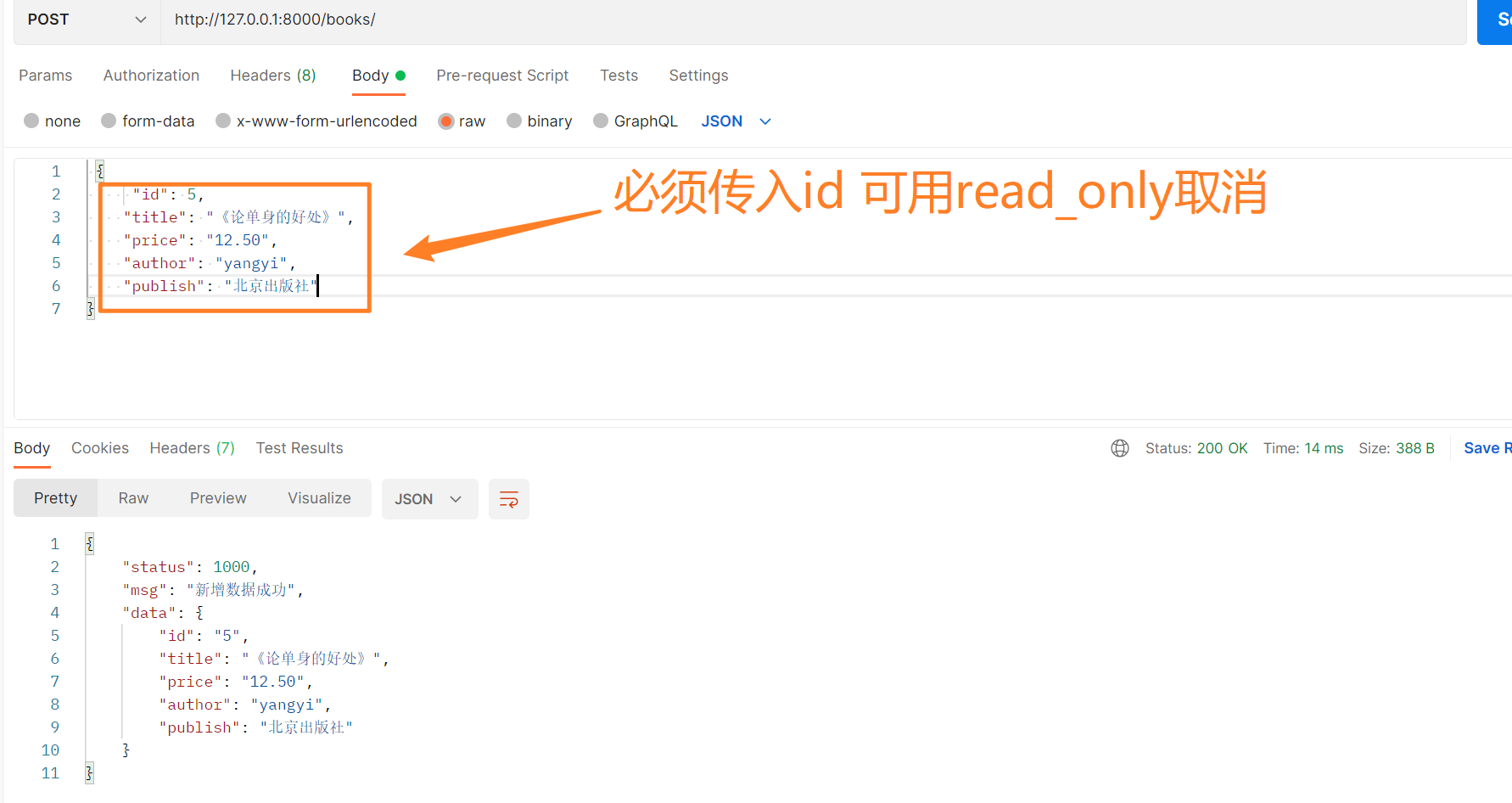
8、新增数据
根据restful规范,我们新增数据时,以post方式提交,后面也不需要传递主键值,所以直接在http://127.0.0.1:8000/books/路由中操作即可。
路由配置如下。
- urls.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 查询所有的数据 添加数据
url(r'^books/', views.BookViews.as_view()) # 不需要数据的pk值
]
- views.py
# 查询所有的数据 添加数据【不需要pk的操作】
class BookViews(APIView):
# 新增数据,不需要pk值【需要将传过来的数据进行反序列化】
def post(self, request):
# 返回的数据
back_dic = {'status': 1000, 'msg': '新增数据成功'}
# 修改才有instance,新增没有instance,只有data,必须以关键字的方式传入参数
"""
当传了data的时候,book_ser.save()的时候调用create方法
当传了instance和data的时候,book_ser.save()的时候调用update方法
"""
book_ser = BookSerializer(data=request.data)
# 校验传过来的数据是够正确
if book_ser.is_valid():
# 保存数据
book_ser.save()
# 添加返回的数据
back_dic['data'] = book_ser.data
else:
# 不成功返回的数据
back_dic['status'] = 2000
back_dic['msg'] = book_ser.errors
return Response(back_dic)
- ser.py
# 定义一个书籍的序列化类
class BookSerializer(serializers.Serializer):
id = serializers.CharField()
title = serializers.CharField(max_length=8, min_length=3)
price = serializers.CharField()
author = serializers.CharField(validators=[check_author])
publish = serializers.CharField()
# 父类要求子类添加数据时必须书写create方法【添加数据】
def create(self, validated_data):
"""
validated_data为校验通过的有效字段
"""
# 使用有效数据创建书籍
"""方式一:直接打散 方式二:拿到单独的数据,然后单独进行传参"""
instance = models.Book.objects.create(**validated_data)
return instance # 必须返回instance
效果如下所示。
9、删除一个数据
需要传入pk值,我们配置这样的路由。删除数据不需要序列化组件。
- urls.py
urlpatterns = [
# 修改、获取、删除【需要pk】
url(r'^books/(?P<pk>\d+)/', views.BookView.as_view()),
]
- views.py
# 单本数据的查看、修改、删除
class BookView(APIView):
# delete请求:删除数据【当然,也可以有更复杂的逻辑,这里只做演示】
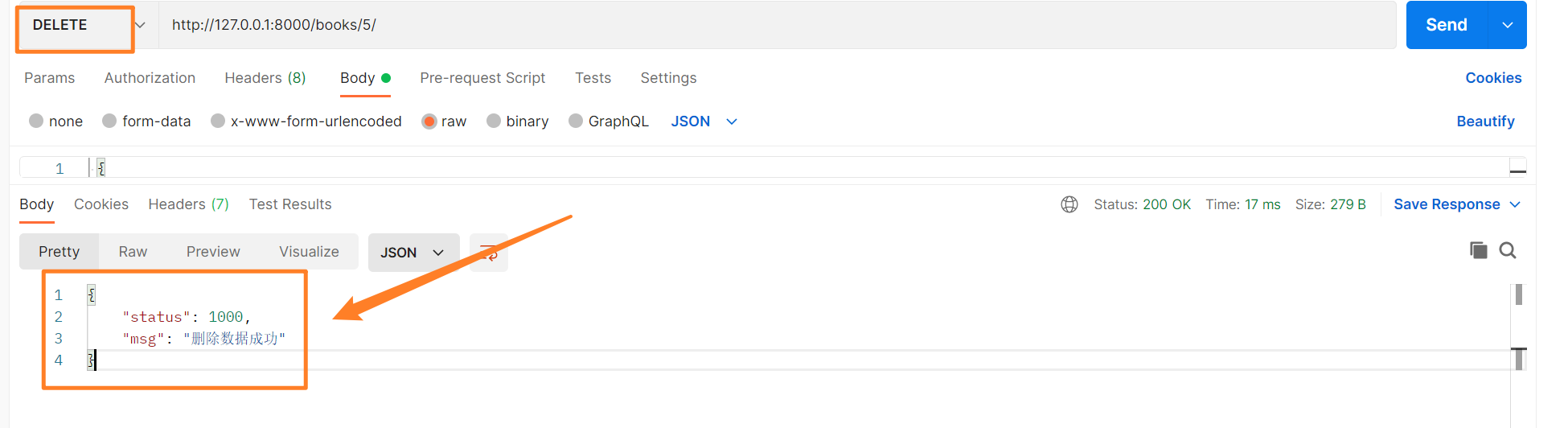
def delete(self, request, pk):
# 根据pk拿到书籍对象
models.Book.objects.filter(id=pk).delete()
# 返回的数据
back_dic = {'status': 1000, 'msg': '删除数据成功'}
# 返回数据
return Response(back_dic)
10、模型类序列化器
我们使用下面代码进行测试。
"""urls.py"""
url(r'^books/', views.BookViews.as_view())
"""ser.py"""
# 模型类序列化器【继承serializers.ModelSerializer】
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
# 对应上models.py中的表模型
model = models.Book
# 确定要序列化的字段
fields = '__all__'
"""views.py"""
# 使用模型类序列化器查看数据
class BookViews(APIView):
def get(self, request):
# 返回数据
back_dic = {'status': 1000, 'msg': '获取数据成功'}
# 拿到所有的书籍对象
book_queryset = models.Book.objects.all()
# 模型类序列化器使用
book_ser = BookModelSerializer(book_queryset, many=True)
# 添加返回数据
back_dic['data'] = book_ser.data
# 返回数据
return Response(book_ser.data)
"""补充"""
fields=('name','price','id','author') # 只序列化指定的字段
exclude=('name',) # 排除序列化name字段
read_only_fields=('price',) # 已弃用
write_only_fields=('id',) # 已弃用
# 可以给字段添加额外的属性,类似于这种形式name=serializers.CharField(max_length=16,min_length=4)
extra_kwargs = {
'id': { # 这里是read_only和write_only如果写,都要写,没有默认一说
'write_only': True,
'read_only': False
},
}
# 不需要重写create和updata方法了,其余的使用一模一样。
显示效果如下所示,
11、many源码分析
序列化的时候,有两种传参方式。
# 传入单个数据对象
book_ser = BookSerializer(book_obj)
print(book_ser) # <class 'app01.ser.BookSerializer'>
# 传入一个查询集的多个数据对象
books_ser = BookSerializer(book_queryset, many=True)
print(books_ser) # <class 'rest_framework.serializers.ListSerializer'>
"""类产生对象的三个步骤"""
1 对象的生成--》先调用类的__new__方法,生成空对象
2 对象=类名(name=yangyi),触发类的__init__()
3 类的__new__方法控制对象的生成
我们发现,同一个类BookSerializer,根据传入方式的不同,产生的不同对象,确从属于不同的类,这是为什么?是怎么实现的呢?
我们通过观察源码可以得到答案。

12、Serializer高级用法
1、source的使用
从上面的案例中,我们发现,序列化组件中的字段貌似"必须"和数据库中表字段相同,如果是这样的话,那么是很危险的,别人可以通过返回的数据,查到数据库中字段名。
那么,我们该如何解决这个问题,这就要用到source,使用方式如下所示。
同时我们使用三张表,进行测试,分别是书籍表、出版社表、作者表,分别是一对多 和 多对多的关系。
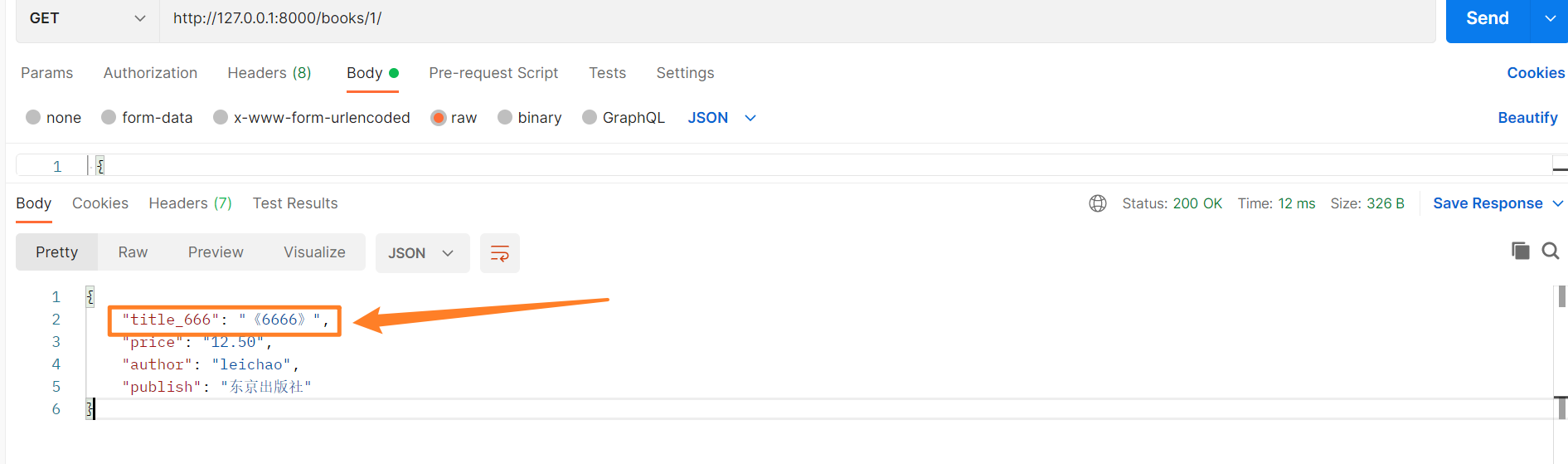
# 修改字段名
title_666 = serializers.CharField(source='title')
显示效果如下。
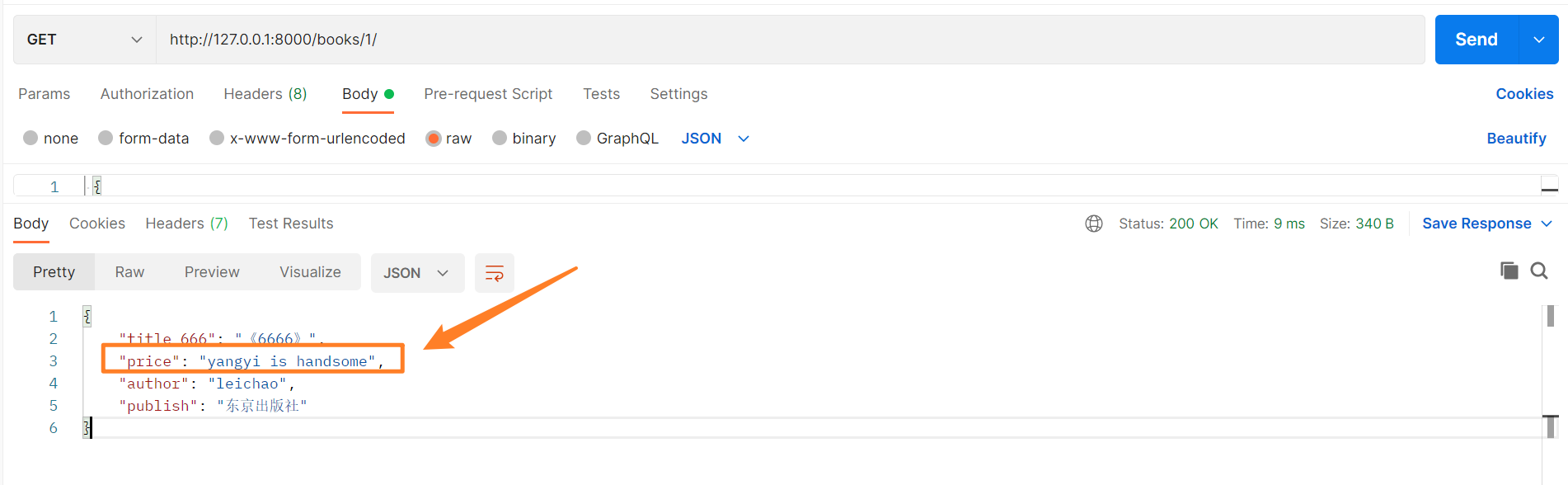
# 可以跨表查询
publish=serializers.CharField(source='publish.addr')
# 可以执行方法【test是一个Book模型表中的方法】
price = serializers.CharField(source='test')
"""Book模型表"""
class Book(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
author = models.CharField(max_length=32)
publish = models.CharField(max_length=64)
# 表中的方法
def test(self):
return 'yangyi is handsome'
显示效果如下。
为什么会是这样呢?
因为在序列化的类中,隐藏有一个book对象,如在title_666 = serializers.CharField(source='title')中,title_666为将要序列化后将要显示的键key,value为book.title(内部是这样实现的)。如果不传参数,默认是book.当前字段名。
那么又有一个问题,如果有外键呢?
"""一对多"""
publish = serializers.CharField() # book.publish 取到一个对象,如果要显示对象名,可定义__str__方法。
"""多对多"""
authors = serializers.CharField() # book.authors 我们发现并不能正确显示,因为正常情况下需要 book.authors.all(),那么该如何解决的?
# source其实可以指定按照哪个字段来序列化,如果不写,默认是book.当前字段名;如果书写,就是book.source指定的字段
2、SerializerMethodField()的使用
专门用来解决多对多取值的问题。
# 定义字段方式
authors=serializers.SerializerMethodField()
# 它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西
def get_authors(self,instance):
"""传入一个instance,即为book对象"""
authors_queryset=instance.authors.all() # 取出所有作者
li = []
for author_obj in authors_queryset:
li.append({'name':author_obj.name,'age':author_obj.age})
return li

 浙公网安备 33010602011771号
浙公网安备 33010602011771号