第二篇:Python变量及基本数据类型相关
Python变量及基本数据类型相关
一、变量
1、什么是变量?
变量就是可以变化的量,用来记录事物的信息,比如人的年龄、性别,游戏角色的等级、金钱等等。
2、变量的三大特征及原则
-
变量名
变量名用来存放等号右侧值的内存地址,用来访问右侧的值。【python是引用传递】
-
=
将变量值的内存地址绑定给变量名
-
变量值
代表事物的状态【申请内存空间】
"""举例"""
name = 'yangyi'
age = 18
gender = 'male'
变量名【见名知意】:
- 字母、数字、下划线,但不能以数字开头,不能使用python关键字
- 不能使用拼音、中文【虽然并不报错】
变量名的使用原则
先定义,后使用。
变量名的命名规则
-
纯小写 + 下划线 【python中推荐使用】
student_name = 'yangyi' -
驼峰式
studentName = 'yangyi'
3、变量值的三大特征
- id
name = 'yangyi'
print(id(name)) # 查看变量值所在的内存地址
>>> 21662080
- type
type(name)
>>> <class 'str'> # python中万物皆对象,其实查看的是name的父类
- value
没什么好说的。
4、变量的引用计数
python提供了所谓的垃圾回收机制,即当变量的引用技术变为0时,将堆中的变量值进行清除。
name = 'yangyi' # name存在栈中,'yangyi'存在堆区中 此时'yangyi'的引用计数为1,并不会当作垃圾进行清除
del name # 'yangyi'的引用计数变为0,此时会被python的垃圾回收机制进行清除
x = 10
y = x
z = y # 此时 10 的引用计数为 3
二、常量
Python没有常量的概念,但是在程序开发中会涉及到常量的概念,所以提供了约定俗成的一种写法。【并非强制性,而是约定俗称】
PI = 3.1415926
三、is 与 ==
- 身份运算 is
# is 比较左右两个值身份id是否相等
# == 比较左右两个值他们的值是否相等
结论:
值相等的情况下,id可能不同
name1 = 'yangyi' name2 = 'yangyi'
但id相等的情况下,值一定相同。
四、小整数池
从python解释器启动的那一刻起开始,就会在内存中事先申请号一系列的内存空间,用来存放常用的整数【也是用于部分字符】,即python解释器做的一种优化。
"""这也就可以解释如下情况"""
a = 10
b = 10
a is b # True
a = 12345
b = 12345
a is b # False
ps: python解释器的小整数池范围为 [-5, 256],pycharm对小整数池做了更大的优化。【所以Pycahrm吃内存】,范围以python解释器为准。
五、基本数据类型
1、数字类型
-
整形 int
用来记录年龄、身份证号、个数等
age = 18
type(age)
>>> <class 'int'>
-
浮点型 float
记录薪资、身高、体重等
num = 18.6
type(num)
>>> <class 'float'>
2、字符串类型
作用:记录描述性质的状况,名字,信息,性别等。【用引号括起来,单引号,双引号均可,变量名也是字符,但是不需要加引号】
name = 'yangyi' # 补充:变量的三大特征齐全,才会开辟内存空间
字符串引号嵌套使用
1、单双引号之间相互嵌套
2、使用转义字符
info = 'my name is \'yangyi\''
"""字符串的拼接"""
字符串可以直接相加,但是仅限于字符串和字符串之间【js中字符串可以和其他类型相加】不推荐使用,因为效率很低,python中推荐使用 .join()
# 直接拼接
name = 'yang'
info = 'yi'
print(name + info)
>>> 'yangyi'
# join方法
desc = ''.join([name, info])
print(desc)
>>> 'yangyi'
"""字符串相乘"""
print('='*20)
'===================='
3、列表类型
由来:虽然字符串可以存储多个数据,如:hobbies = 'read music eat',但是取十分不方便,数据存主要是为了取而存在的,因此必须有一种更好的数据结构出现,列表由此而生。
列表:记录多个值,并可以按照索引取指定位置的值,索引取值(有序),从0开始。【列表中通常存放的是同一种属性,如:同一个人的多个爱好,同一个班级的所有学生姓名】
li = ['read', 'music', 'eat']
print(type(li))
<class 'list'>
# 列表数据可以嵌套
li = [10, 3.14, 'yangyi', [111, 'aaa']]
# 取值【索引取值,支持负数索引】
li[-1]
[111, 'aaa']
li[3][1]
'aaa'
4、字典类型
字典是为了方便的进行数据存储而存在的,列表对应的索引值没有描述性的功能。字典中的数据是无序的,根据键的方式取值,键为不可变类型,通常为字符串,即有描述性信息。
# 好的数据结构,可以在程序执行过程中起到事半功倍的效果
user_info = {
'name':'yangyi',
'age':18,
'gender':'male',
'hobbies':['read','music','study'] # 列表与字典可以相互嵌套,组合成更好的数据结构
}
print(type(user_info))
<class 'dict'>
# 取值方式【键取值】
user_info['name'] # 没有键则报错
'yangyi'
user_info.get('name') # 没有键则返回None【取数据推荐】
'yangyi'
5、元组
元组为不可变类型,不能进行修改,存储和返回固定的数据,为‘阉割版’的列表,相较于列表缺少一定的方法。
tup = (1,)
print(type(tup))
<class 'tuple'>
# 取值方式【索引取值】
tup[0]
1
5、布尔类型
作用:用于记录真假,当前也可以不适用,使用 0 或 1,只要能表示两种状态即可。
# True False
print(type(True))
<class 'bool'>
六、可变与不可变类型
可变类型:值改变,id不变,改的是原值,证明原值是可以该改变的。
不可变类型:值改变,id改变,改的不是原值,产生了新的值,原值是不可以改变的。
- 整形【不可变类型】
x = 10
print(id(x)) # 1351022656
x = 11
print(id(x)) # 1351022672
# 值改变,id改变,说明产生了新的内存空间,即整形为不可变类型
- 浮点型【不可变类型】
x = 3.14
print(id(x)) # 15348992
y = 3.15
print(id(x)) # 15349344
# 值改变,id改变,说明产生了新的内存空间,即浮点型为不可变类型
- 字符串【不可变类型】
name = 'yangyi'
print(id(name)) # 27414144
name = 'leichao'
print(id(name)) # 27363840
# 值改变,id改变,说明产生了新的内存空间,即字符串为不可变类型
- 列表【可变类型】
user = ['yangyi', 'leichao', 'anan', 'yangxin']
print(id(user)) #27340584
user[0] = 'quankang'
print(id(user)) #27340584
# 我们会发现,更改列表中元素的值后,列表的id值不变,即列表为可变类型。
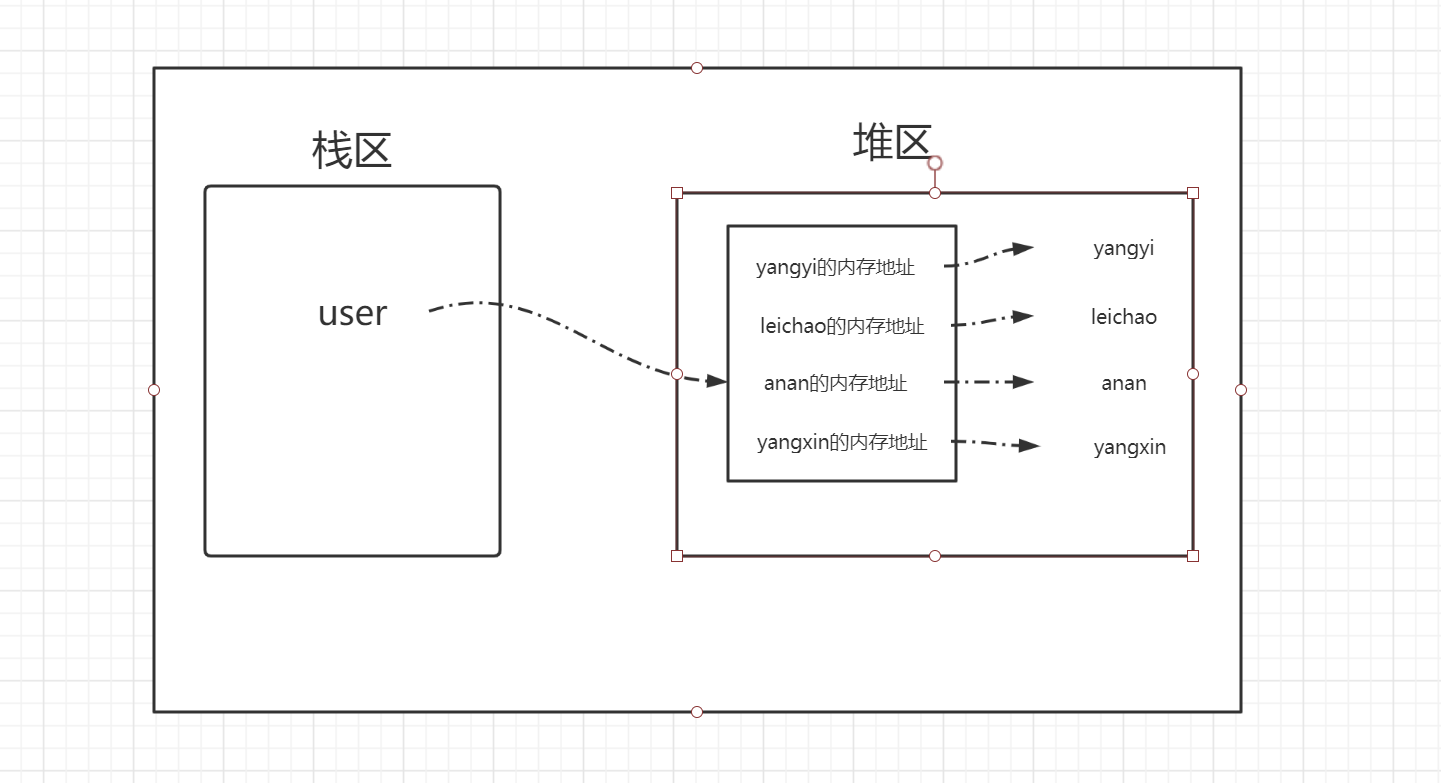
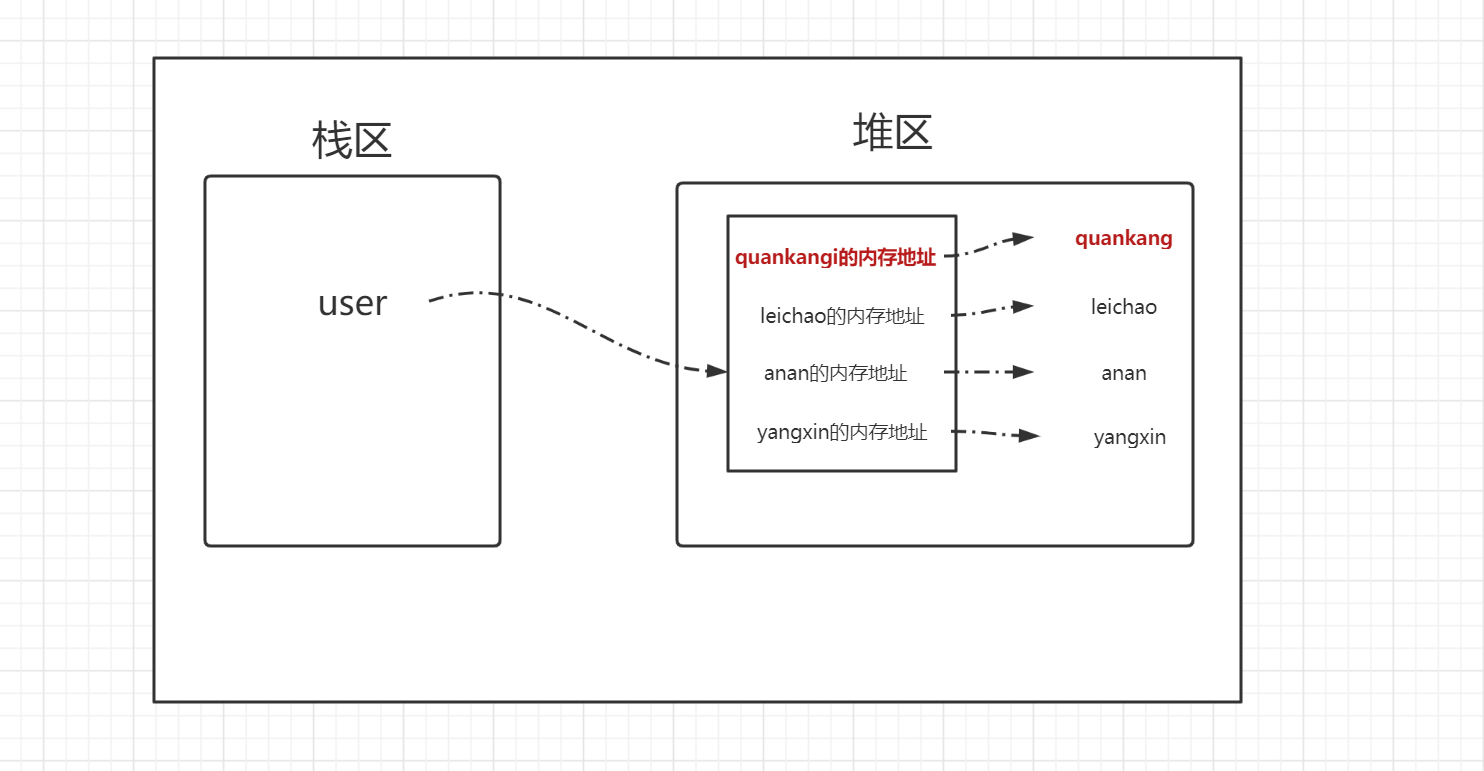
从图中我们看出来,user始终指向堆区列表的内存地址,列表中存放的并非值本身,而是存放的值的内存地址,所以修改user[0] = 'quankang'只是在堆区开辟了 quankang的内存地址,并将列表的稍作修改,所以的id值并未改变,所以列表为可变类型。
- 字典【可变类型】
字典和列表在内存中的存储方式类似,所以字典也为可变类型,此处不过多赘述。
user_info = {
'name':'yangyi',
'age':18
}
print(id(user_info)) # 16033424
user_info['age'] = 15
print(id(user_info)) # 16033424
- 布尔类型【不可变类型】
flag = True
print(id(flag)) # 1350897984
flag = False
print(id(flag)) # 1350898000
七、深浅拷贝
重要:列表是可变类型
list1 = ['yangyi', 18, [1, 2]]
list2 = list1
# 如此一来,两者便不可分割,一改俱改
list1[1] = 15
list1
['yangyi', 15, [1, 2]]
list2
['yangyi', 15, [1, 2]]
如此一来,便引入了一个问题,如果要将两者分开,那么该如何处理?
需求:1、拷贝一下原列表,产生一个新的列表
2、两个列表完全独立开。【如果仅仅是为了读取,那么完全没有必要独立,如果改操作的话,那么就要分开,做到互不干扰。】
-
浅拷贝
利用列表对象提供的方法
list1 = ['yangyi', 18, [1, 2]]
list2 = list1.copy()
# 如此一来,copy了一份新的列表,list1和list2的id值不同
print(id(list1)) # 27340616
print(id(list2)) # 27340712
别急,接着我们又会发现一个新的问题。
list1 = ['yangyi', 18, [1, 2]]
list2 = list1.copy()
list1[2][0] = 222
list1
['yangyi', 18, [222, 2]]
list2 # 修改`list1`中的值,`list2`又发生了变化,这又是为何?
['yangyi', 18, [222, 2]]
总结 : 浅拷贝其实只是拷贝了列表容器的本身,只是把原列表第一层的内存地址拷贝了一份,仅此而已,所以,如果要严格拷贝列表,必须使用深拷贝
- 深拷贝
拷贝一份完全独立的列表
import copy # 我们需要导入copy模块,以后模块会进行详讲
list1 = ['yangyi', 18, [1, 2]]
list2 = copy.deepcopy(list1)
"""
原理:针对可变类型,产生新的内存地址即可;
针对不可变类型,不产生新的内存地址。【因为如果重新赋值,不可变类型自会产生新的内存空间】
"""
八、基本数据类型及内置方法
1、数值类型【类型转化】
- int类型
age = 18 等价于 age = int(18) # 名字+() 代表触发了功能的运行
# int在python中是一个类,将18转化成int对象【python中一切皆对象】
# 小tip:
res = print('yangyi')
print(res) >>> None # 类比现实:代表工厂没有生产出产品.
类型转换
int('18') # 纯数字的字符串转换成int
>>> 18
int('18.1') # 报错【不能有小数点】
>>> ValueError
"""二进制转化为其他进制"""
# 十进制 ---> 二进制
bin(18)
>>>'0b10010' # 注意,转换出来的是字符串
# 十进制 ---> 八进制
oct(18)
>>>'0o22'
# 十进制 ---> 十六进制
hex(18)
>>>'0x12'
"""其他进制转换为二进制"""
# 二进制 ---> 十进制
int('0b10010', 2)
>>> 18
# 八进制 ---> 十进制
int('0o22', 8)
>>> 18
# 十六进制 ---> 十进制
int('0x12', 16)
>>> 18
整数类型没有内置方法【即().()】
-
float
float('18.3')
>>> 18.3
总结:int 和 float 没有需要掌握的内置方法,使用便是数学运算 + 条件判断
2、复数【了解】
基本使用
x = 10 + 2j
type(x)
<class 'complex'>
x.real # 查看实部
>>> 10.0
x.imag # 查看虚部
>>> 2.0
3、字符串类型
msg = 'yangyi' # msg = str('yangyi')
"""str可以把任意其他类型转化成字符串"""
res = str({'name':'yangyi', 'age':18})
print(res)
>>> "{'name': 'yangyi', 'age': 18}" # 单双引号嵌套使用
字符串操作
- 必须掌握的操作
- 按照索引取值【只能取】
msg = 'yangyi'
# 正向索引
print(msg[0])
>>> 'y'
# 反向索引
print(msg[-1])
>>> 'i'
# 不能赋值,直接报错
msg[0] = 'L'
- 切片【索引的拓展应用】(顾头不顾尾)
"""从一个大字符串中拷贝出一个子字符串,字符串是不可变类型,所以必须重新分配内存空间(不修改原字符串)"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号