

软工实践寒假作业(2/2)
|这个作业属于哪个课程|2021春软件工程实践S班|
:-: | :-: | :-:
|这个作业要求在哪里|软工实践寒假作业(2/2)|
|这个作业的目标|阅读《构建之法》、学习Github使用、学习单元测试与性能分析|
|其他参考文献|廖雪峰的git教程 CSDN博客|
GitHub项目链接:https://github.com/yangyi16123/PersonalProject-Java
目录
任务一:重新阅读《构建之法》并提问
- 我在读到第四章两人合作时,在了解代码复审的重要性的同时也有一些疑问?4.5.3表明现在的复审方式大致为两种,伙伴复审:程序员之间互相复审以及团队复审:多人开会复审,而这两种方式都有自身的缺陷。我的个人理解如下,伙伴复审较为贴近日常,审出bug来,较为容易让人接受,自己不会有压迫感,更不可能为此争辩自己没有错。但是这样同时也不够正式不够全面,如文中所说这样不能持久、定时的复审,毕竟没有人愿意天天帮你。但是团队复审也存在问题,比如耗时,这对于一项需要经常展开的活动来说是致命的。而且,原本审查的工作在开会进行会让开发者觉得大家***难自己,也就是所谓的面子问题。因此,我有疑问,这两种方式该如何选择。
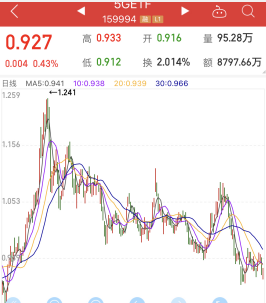
- 阅读到"16-8图:高科技被炒作的规律"与"16-9图:股票泡沫的几个阶段"时我有点吃惊,因为图与我近期关注的5g、半导体、芯片etf基金k线十分相符.这些高科技产品的走势,都是经历了19年的大涨,然后迎来20年的暴跌,且19年时简直把这些捧上天了。我觉得,诚然华为公司确实是国之骄傲,但是当时它还是被过分吹捧了。毕竟,一家公司想要独抗m国这是不可能的,而且我们的芯片技术落后了人家几十年,这不知道要花多久时间去追赶。如今,它们可能正处于作者所说的迷茫期,我只能简单理解股价涨久必跌的道理,但是不明白为这些新技术会有"迷茫期"这一阶段.
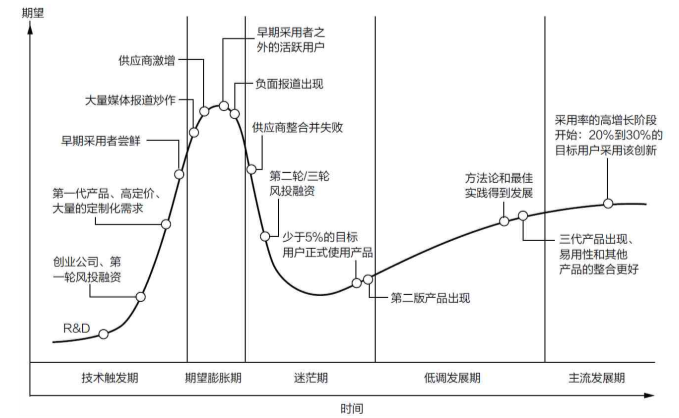
- 书中提到"因为颠覆性技术的市场还不存在",并且颠覆性技术的描述为“这是一门新技术,很不稳定,经济效益也未必确定。有很多未知因素:市场有多大,用户在哪里,有哪些竞争对手,成熟的商业模式是什么。我不太认同作者“颠覆性技术的预测往往是错误的!”的观点,的确谁也没想到今后手机、汽车这些的发展会这么迅速,但是我觉得这些都是个例。我们之所以觉得预测是错的,只是因为我们公众所能了解到的信息,都是一些无行业价值的,或者本来有商业价值但是大家都知道,也就变得无价值。我查阅了资料,人工智能以及区块链钱包都属于颠覆性技术,而且目前大家普遍看好如果说专家的预测存在偏差,是否意味着如今大家认为的"人工智能 大数据"这些是风口,我们还是应持保留态度?
- 阅读到3.2软件工程师的职业发展,作者提到,21世纪以来,中国大陆每年招收六百万大学生,其中的百分之十是在学习各种IT相关的专业每年大致有四十万到六十万左右的“职业软件工程师”进入工作岗位.我又翻到首页看了下作者更新第三版的时候是2015年,时隔六年,我百度了一下现在的数据,据统计中国目前有六百万左右从事开发人员。而且由于如今的从业门槛低增长速度不断增加,火爆程度愈演愈烈。从我最近关注的考研情况来看,就中科大软件学院,前几年还招收调剂生,而今年据不完全统计分数400+的人数已经超过了400。网上也传出了“内卷”这个词,承然,现如今没以前那么容易在这个领域混下去了,在这样的局势下我们的未来规划应该做出如何的调整呢?
- 作者在书中提到“简单的说,软件的行为和用户的期望值不一样,就叫Bug,是否是Bug,取决于用户、开发者的不同角度。”,从这里我也有个疑问,用户期望跟软件开发的需求肯定会存在冲突,当我们围绕用户需求去设计开发这个软件时,需求得到了很好的满足,但是对于开发者往往达不到自己认为的标准,因为开发者觉得可以牺牲一些不必要的体验来优化性能。当这个行为与用户需求冲突时,这bug到底应该谁来背。有时我们可以引导用户取一个中间值,但是若是用户期望值跟软件优化产生极大冲突时,应当如何抉择。
任务二:设计词频统计程序
1、项目github链接:https://github.com/yangyi16123/PersonalProject-Java
2、PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 20 |
| Development | • 开发 | 400 | 600 |
| • Analysis | • 需求分析 (包括学习新技术) | 90 | 120 |
| • Design Spec | • 生成设计文档 | 20 | 30 |
| • Design Review | • 设计复审 | 30 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 100 | 60 |
| • Design | • 具体设计 | 60 | 50 |
| • Coding | • 具体编码 | 60 | 40 |
| • Code Review | • 代码复审 | 60 | 80 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 120 | 100 |
| • Test Repor | • 测试报告 | 90 | 90 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1240 | 1650 |
3、设计思路
- 初看题目
起初看到题目时,看到要求众多,且都是一些没有接触过的东西,看的我有点不知所措。接着按照任务清单的指引,我对此次作业有了一定认识。但是,天真的我以为只是写一个程序,能跑就行。很快我发现我错了,这任务跟以往完全不同,以前的作业,只需要输入一些简单的测试项,各项功能正常就算完成,可是此次任务需要模仿个人独立完成项目,加上GitHub不断commit和完成后进行性能分析并且改进,最后其实花掉我最多时间的就是完善代码。 - 开始分析
我大概把任务分成几块,1、文件的读写操作 2、字符串的处理(包括计算字符、单词数量等) 3、性能分析并改进。而我首先要完成的就是文件的操作与字符串的处理。首先我花了一点时间(其实很久,对文件的相对路径有点陌生)学习文件操作,刚开始先做字符串与行数计算,采用变读取文件边计算的方法,很快发现了弊端。于是换将整个文件存入字符串中,再对字符串处理。其中遇到了很多问题,大致思考流程如图,当然这是我初步的想法与实践,后续还遇到了问题。

4、代码规范制定
代码规范:https://github.com/yangyi16123/PersonalProject-Java/blob/main/221801325/codestyle.md
5、模块接口设计
- 总体概述
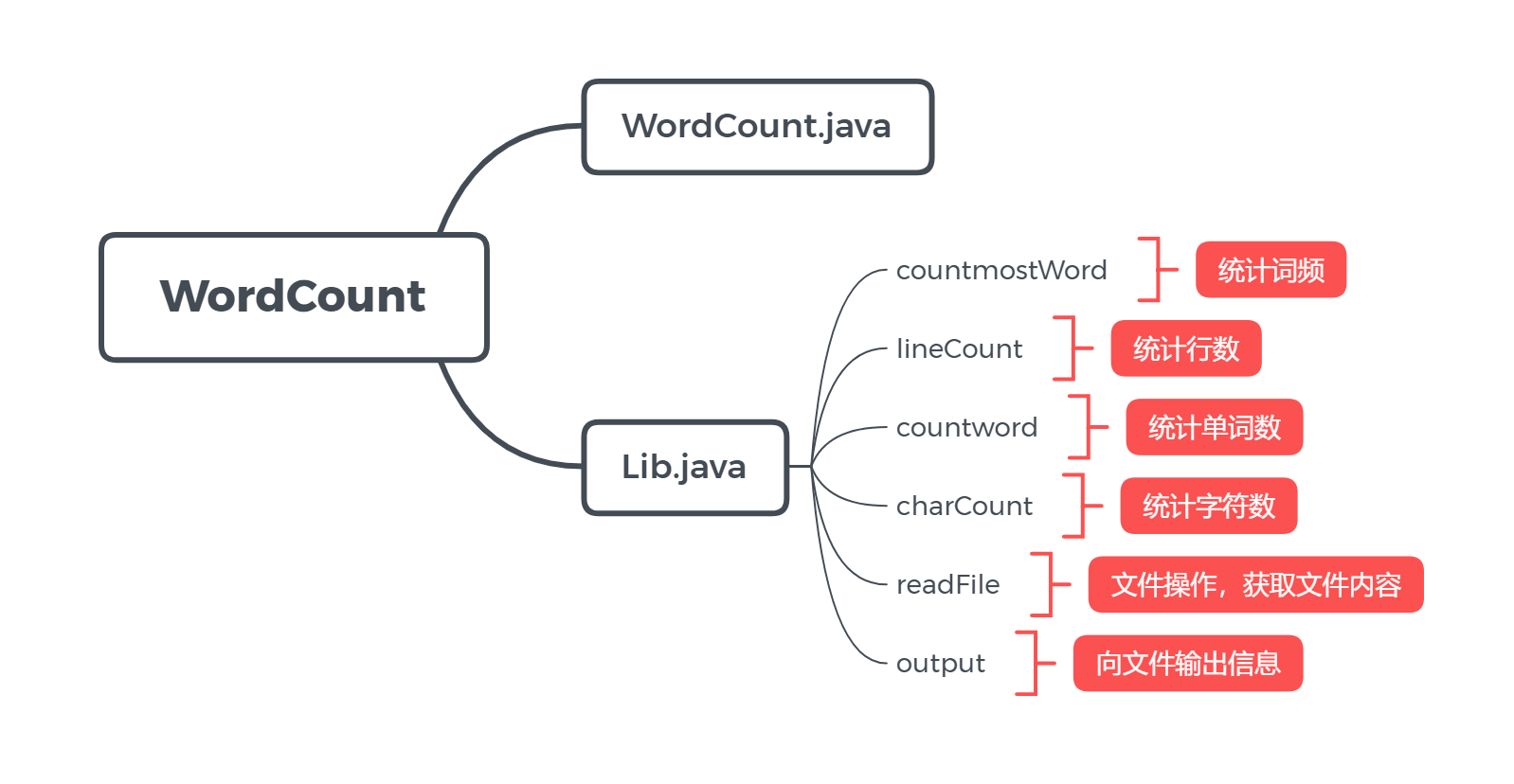
实现细节
1、读取文件
考虑到读取文件,若文件过大,会十分耗时。因此,设计一个readFile(),将文件内容以字符串形式返回,然后将字符串传入各计算接口。
readFile方法主要功能块
File file = new File(filePath);
FileInputStream inputStream = new FileInputStream(file);
byte[] buffer = new byte[1024];
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int cnt = 0;
while ((cnt = inputStream.read(buffer)) > -1)
{
baos.write(buffer, 0, cnt);
}
baos.flush();
inputStream.close();
baos.close();
return baos.toString();
接着,首先进行字符数量的计算设计charCount()方法,传入一个字符串,通过正则表达式,matcher.fin()部分匹配查找是否合法。
charCount主要功能块
public long charCount(String string) throws IOException
{
String regex = "\\p{ASCII}";//正则表达式判断是否为合法字符
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(string);
while (matcher.find()) {
characters++;
}
return characters;
}
countword主要功能块,接收字符串参数,还是通过正则表示匹配,计算单词数。这里因为查找的是(分隔符)+(单词)的情况,因此取group(2),但开头的单词,不存在前分隔符号,因此我这里建了一个新的Stringbuffer在开头加上一个空格,拼接传入的string作为新的参数。此次,由于遍历了一遍单词,因此可以顺便把单词存到一个map中,方便后续的高频词查找。
public long countword(String string)
{
long num = 0;
string=string.toLowerCase();
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append(" ");
stringBuffer.append(string);
String regex = "([^a-z0-9])([a-z]{4}[a-z0-9]*)";//正则匹配
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(stringBuffer.toString());
while(matcher.find())
{ String temp=matcher.group(2).trim();//取出group(2),既单词,trim为了除去之前加的空格
num++;
if (map.containsKey(temp)) {
map.put(temp, map.get(temp) + 1);//顺便存入map,方便后续
} else {
map.put(temp, 1);
}
}
return num;
}
countmostWord()功能块,查找高频词,返回一个list
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>()
{
public int compare(Map.Entry<String, Integer> mapping2, Map.Entry<String, Integer> mapping1)
{
int result = mapping1.getValue().compareTo(mapping2.getValue());
if(result!=0)
{
return result;//即两个Value不相同,就按照Value倒序输出
}
else
{
return mapping2.getKey().compareTo(mapping1.getKey());
}//若两个Value相同,就按照Key倒序输出
}
});
return list;
剩余内容,将于性能分析处,详细说明。
6、性能分析与改进
初始性能情况(测试文件大小100m,字符数一亿左右)
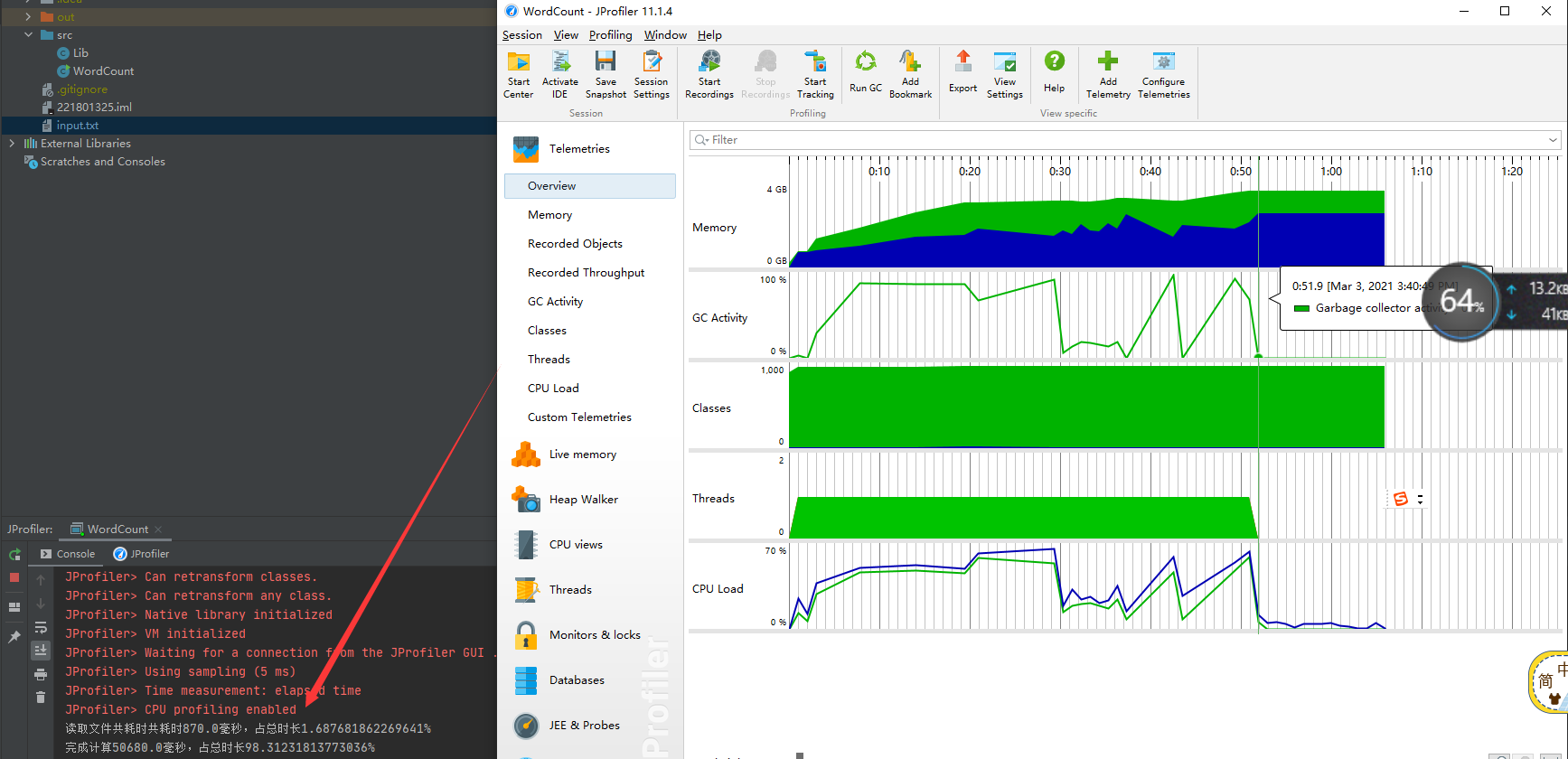
耗时五十秒左右,根据常识,我也明白了此时的性能完全不行。但是,不知道性能分析软件,如何精确看到各模块的时间,因此我手动算了一下时间
根据测算,我发现我的程序,首先在读取文件上就花了许多时间占了总时间百分九十多.
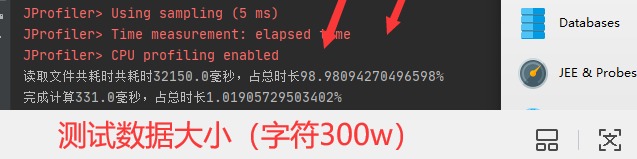
初始读取文件主要功能块
BufferedReader bufferedReader = new BufferedReader(new FileReader(path));
String s = "";
String line;
while ((line = bufferedReader.readLine()) != null)
{
s = s + line + "\n";
}
System.out.println(s);
于是开始改进,我以为是我的读取方法有问题,换了很多种,都不见效。很快我从网上找到了答案。
于是我将String s改为了Stringbuffer,改用append()方法进行拼接,在这里也学到了。原来String是不可变长的,不断的拼接,一直产生新的String极大影响的效率。修改后我测试了一个小文件结果还算可以。

初始处理字符串主要功能块
前面基本完成了对文件操作的小优化,我测试100m文件的耗时也优化到了30s,接着随着测试文件越来越大,我发现,字符串处理部分的耗时占比越来越大。于是开始着手对处理算法进行优化。首先是
计算单词数目改进
刚开始我使用的方法是这样的,将字符串分割成数组,再进行正则匹配,而这样的耗时也十分大,我输出了一下耗时发现!分割字符串,以及匹配都十分耗时。

初始方法:
String[] word = string.split("\\s+");
for (int i = 0; i < word.length; i++)
{
word[i] = word[i].toLowerCase();
}
String regex = "^[a-z]{4,}.*";
for (int i = 0; i < word.length; i++)
{
String temp = word[i];
if (temp.matches(regex))
{ num++;
经过同学介绍了解到,split()和matches()效率都很低,于是弃用,改用matcher.find()这样既不用分割,又可以部分匹配极大加快了速度,
改进后:计算单词的耗时变成了4000毫秒左右。

计算行数功能改进
同时,我也发现了。计算行数的耗时还是偏高,因为计算行数我也使用的是split(),通过“\r或\n或\r\n”分割(这里错误理解了\r,以为\r也可以换行),接着计算有效行的数量。修改后,我一样采用了正则表达式+matcher.find()来寻找有效行。
初始方法
String[] line = string.split("\r\n|\r|\n");
for (int i = 0;i<line.length;i++)
{
if(!line[i].equals("")&&line[i]!=null)
{
num_of_line++;
}
改进后
long num_of_line=0;
String regex = "(.*)(\\S)";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(string);
while (matcher.find())
{
if (matcher.group(1)!=null&&!matcher.group(1).equals('\t')&&!matcher.group(1).equals('\n')&&!matcher.group(1).equals('\40'))
num_of_line++;
}
但这里仍然存在一个问题,我本以为这样的正则在文档只有一行的情况会出错,但是事实当,对于仅有一行或者没有行的文本,这样仍然适用,而且效率还可以。
文件处理功能改进
至此我测试100m文档的耗时,来到了12s左右。同时我发现,我舍友的读取文件速度出奇的快,而我需要三秒。
目前我是一个一个字符读取的,但是如果我一行一行读,我无法确定行的末尾是以\r还是\n又或是两者结束的。(这里错误理解了\r,以为\r也可以换行,经过助教补充说明其实是可实现的,但是速度应该还是没有按字节读的快)又经过不断的改进,我将文件读取改为了一次操作1024个byte解决了这个问题。文件读取耗时,由原来的3000毫秒左右变为了1000毫秒以内。
并且得知老师说不存在ASCII外字符,与是连算字符串是否匹配的过程也省略了,又快了几百毫秒。
优化后性能情况
终于!!我的耗时进入了十秒,此时的我跟短跑运动员跑进了十秒一样激动。
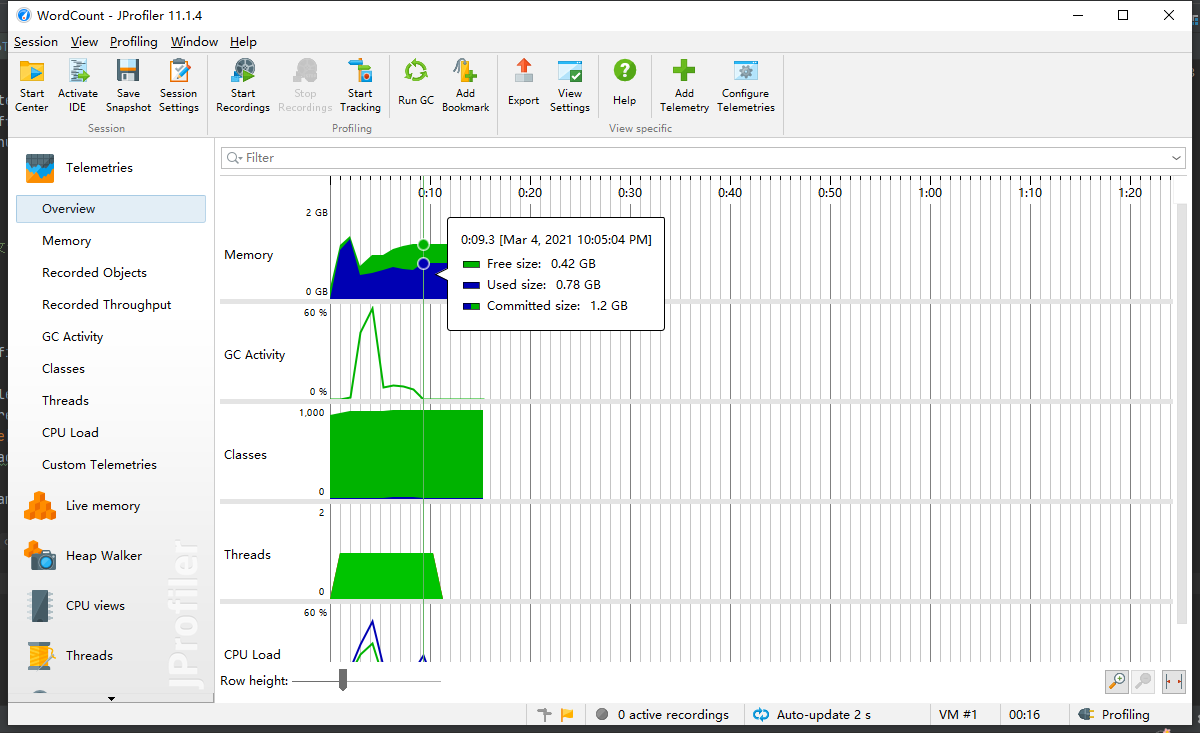
但是我又发现,当文件大小超过500mb我的程序边会崩溃。经过改进后我发现是算行数,正则匹配循环中的if(匹配到的是有效行)语句使得程序变得很慢,经过改进使用,String regex = "(.*)(\\S)";可以不用if语句,匹配到的一定是有效行,我的程序也顺利跑出了500m测试结果。
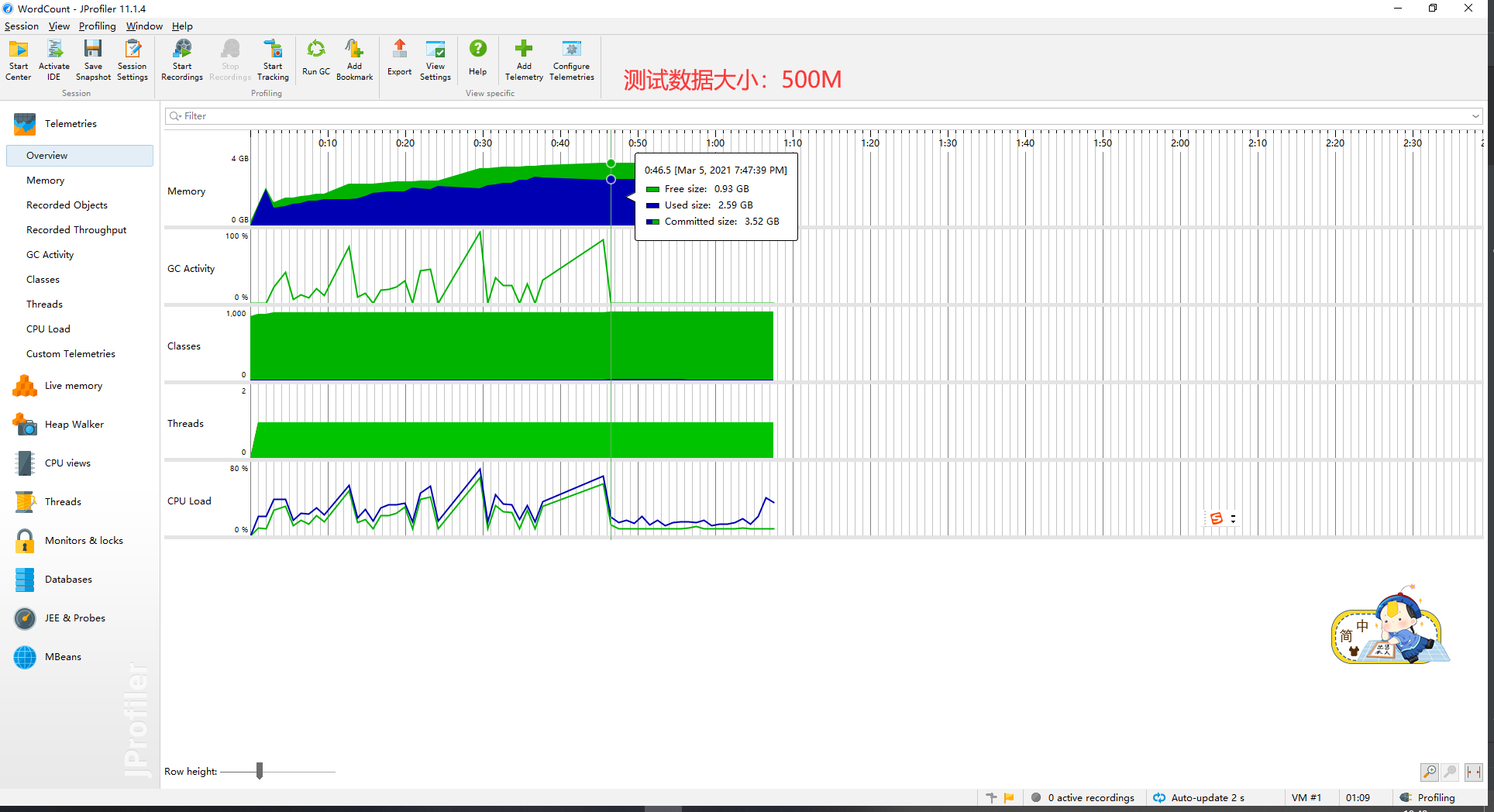
至此,我的优化基本完成。
7、单元测试
我先随机生成了几个测试文件(100m,一亿字符)基本覆盖所有代码,最终我的测试覆盖率如下:
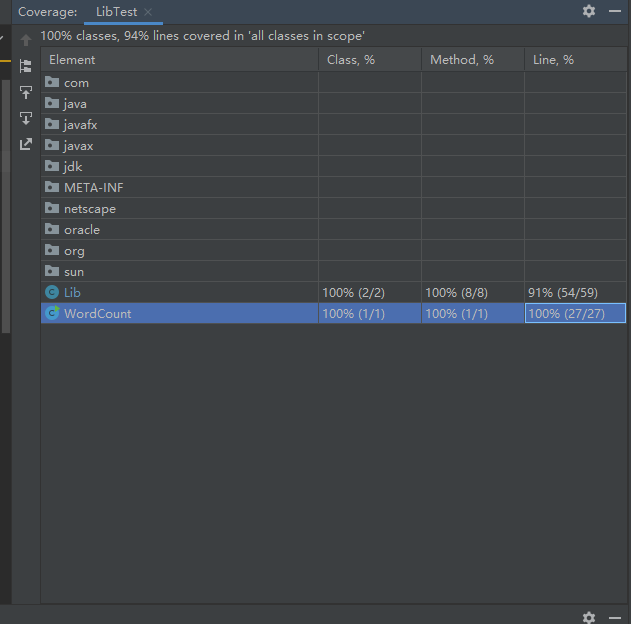
统计字符数测试
public void charCount() throws IOException {
long result = lib.charCount(string);
Assert.assertEquals(100000000,result);
lib.output("output.txt","characters:",result);
}
统计单词书测试
public void countword() {
long result = lib.countword(string);
Assert.assertEquals(4019065,result);
lib.output("output.txt","Word:",result);
}
统计行数测试
public void lineCount() {
long result = lib.lineCount(string);
Assert.assertEquals(8691537,result);
lib.output("output.txt","Line:",result);
}
测试结果如下
8、异常处理说明
文件不存在异常处理
catch (FileNotFoundException e)
{
System.out.println("Can't find file");
}
心路历程
此次作业第一次让我体验到了学长学姐说的软件工程这么课的恐怖,当然他们同时也肯定了自己的收获。这次作业跟以往的作业不一样了,再也不是面向CSDN编程了。很多东西,根本搜不到一样的,只能看一些类似的方法进行改进。刚开始,我还停留在以往的思想,按要求一步一步完成功能,最后整合就行。但是在这之中就已经遇到了很多细节问题,比如一个简单的windows换行是\r\n,我就要多考虑很多东西。以前,只管完成任务,完全不顾效率,这次作业才知道,原来有这么多函数功能相同相似,但是性能上确是天差地别。
这也是我第一次这么仔细的对待一个作业,可能也是因为大三了,跟以前的感觉不一样了,心态不再是那个作业完成就行的年轻人了。
通过作业我收获了很多东西,比如github的使用, 当然刚开始由于不懂,经常出现我不知道怎么解决的问题,提示又是全英文,对于我这英语垃圾十分不友好,当然这也提醒了我,一个优秀的开发者英语能力是十分重要的。也借此巩固了java的基础,更深层次的了解了一些方法上的不同。总体而言,这次作业完成的十分艰辛,这与自己当年的摸鱼逃不了关系,算法改进的时候,我与钟煜新同学一直连麦好几个小时,一直相互讨论如何改进自己的算法,分享自己的想法,也让我知道了团队协作十分重要。
当然,此次作业还有很多不如(看到有些同学多线程处理,100m文件仅需3秒多),而且我在测试性能时,为了结果准确我采用的是直接printf输出时间差而不是进行单元测试查看时间(我也不知道还有什么方式查看),这样的方法可能也比较笨。我所用的方法应该也不是最优,但是第一次体验了一个程序,从运行需要50s一直改进到10s内的过程,受益匪多。相信,后面的作业会带我更多的惊喜。加油!软工人!
