

HBase
一、概述
hbase是一个非关系型分布式数据库,满足快速随机读写的功能。
二、存储流程
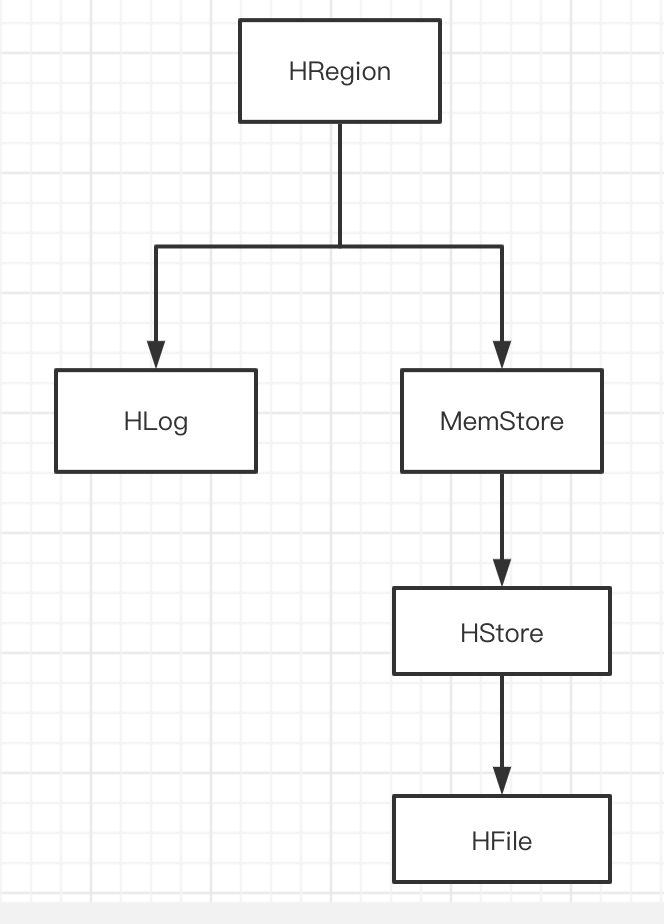
首先调用master找到一个表对应的HRegionServer,然后从regeionServer中找到对应的HRegion,一个HRegion就是一张表的数据,包含一个HLog和若干个HStore。
一个HStore就是一个列族的数据,包含HStore包含一个MemStore,并实现了HFile的写入和读取。
数据保存时先写入HLog,然后写入memStore,memStore满了之后会写入HFile,每个HFile都有一个固定大小,当小文件过度时会由合并拆分线程将小文件合并成一个大文件,
合并几次之后文件会逐渐增大,达到条件后由拆分合并线程完成HFile的拆分。HFile第二次拆分会拆分成标准大小。
之所以要完成合并后再拆分就是为了防止过多同一个rowkey被分到不同的HFile中,一次合并后,一个rowkey的所有kv会合并为一个data块,如果是同一个key则根据最后更新的时间戳来合并最新的值。
三、HBase整体架构


