
JEMT模型
1.概述
机器翻译的输入一般是源语言的句子。但在很多实际系统中,比如语音识别系统的输出或者基于拼音的文字输入,源语言句子一般包含很多同音字错误, 这会导致翻译出现很多意想不到的错误。由于可以同时获得发音信息,我们提出了一种在输入端加入发音信息,进而在模型的嵌入层
融合文字信息和发音信息的翻译方法,大大提高了翻译模型对同音字错误的抵抗能力。
2.Joint Embedding
对于源语言的一个词,它的发音单元记作
![]()
作embedding时,每一个s作一次embedding,记作:
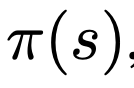
对于一个词的embedding是l+1维
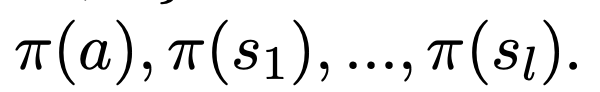
最后通过公式
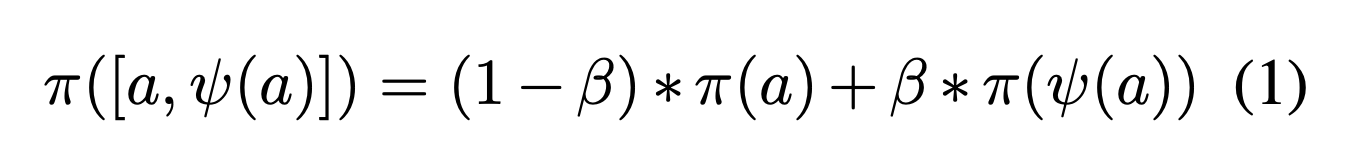
将三个向量合成一个向量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号