
erine
1.概述
erine是一种自然语言处理的预训练模型,对自然语言推理,命名实体识别,文本分类有很好的效果。
2.模型结构
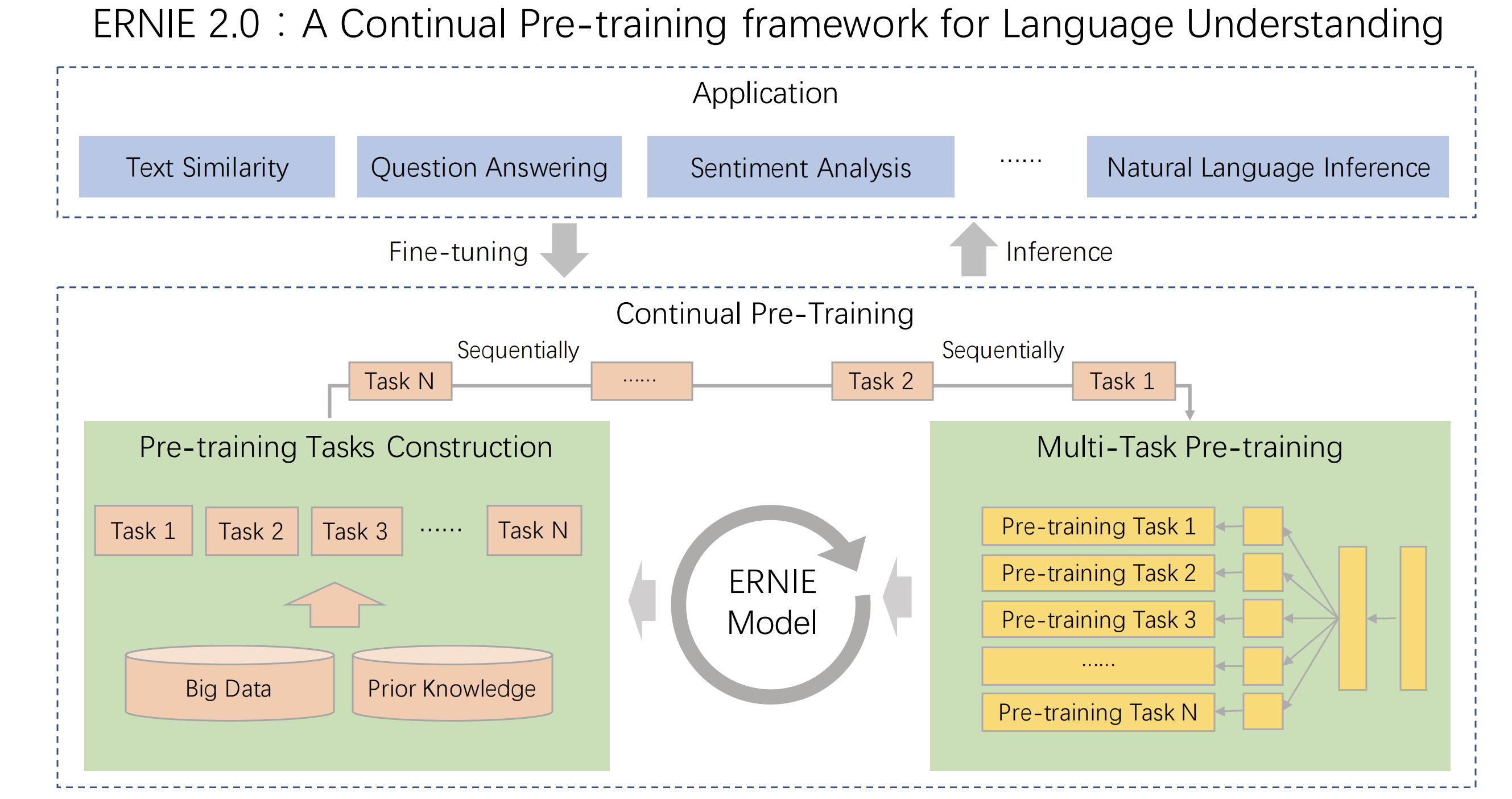
3.模型结构
1).Transformer Encoder
该模型使用多层Transformer作为基本编码器,与其他预训练类似GPT、BERT等模型。Transformer可以捕获每个Token的上下文信息在序列中通过自我注意,并生成一个上下文嵌入序列。给定一个序列,特殊的
分类嵌入[CLS]被添加到序列的第一个位置。此外,还添加了[SEP]符号
作为多个输入段任务的段间隔的分隔符。
2).Task Embedding
任务嵌入模型为任务嵌入提供信息,以调节不同任务的特性。我们使用
id从0到N的不同任务。每个任务id都分配给一个唯一的任务嵌入。相应的
模型以tokwn、分段、位置和任务嵌入作为输入。我们可以使用任何任务id来初始化
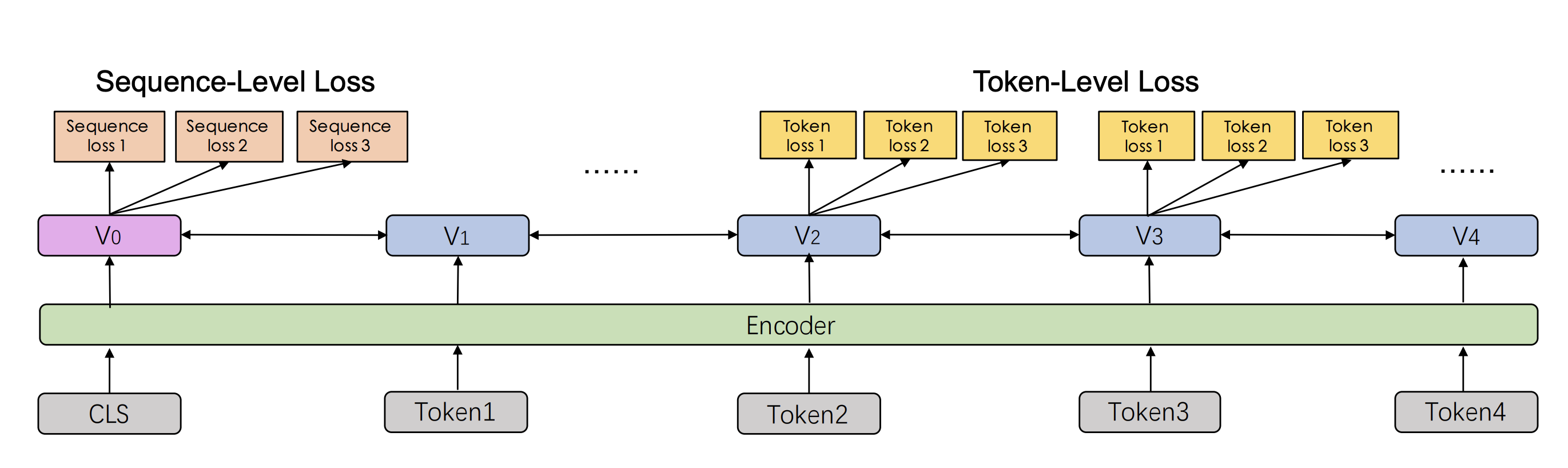
4.任务
1).Word-aware Pre-training Tasks
提出了一种通过知识增强表示的有效策略
整合。它引入了短语掩蔽和命名实体掩蔽,并对整个掩蔽短语进行预测
实体来帮助模型学习本地上下文和全局上下文中的依赖关系信息。我们用这个任务训练模型的初始版本。
2).Structure-aware Pre-training Tasks
我们添加一个句子重新排序任务来学习句子之间的关系。在
在这个任务的预训练过程中,一个给定的段落被随机分成1到m段,然后
组合被随机排列的顺序洗牌。我们让预先训练的模型重新组织这些排列
分段,建模为k类分类问题。根据经验,句子重新排序任务
可以使预先训练的模型学习文档中句子之间的关系。
3).Semantic-aware Pre-training Tasks
除了上面提到的距离任务之外,我们还引入了一个任务来预测语义
或两个句子之间的修辞关系。我们使用Sileo等人[18]建立的数据来训练预先训练的模型
英语任务。按照Sileo等人[18]的方法,我们还自动构建了
训练前。
4).IR Relevance Task
我们构建了一个学习信息检索中短文本相关性的预训练任务。这是三等舱
预测查询和标题之间关系的分类任务。我们把这个问题当作第一句话
标题作为第二句话。我们使用百度搜索引擎的搜索日志数据作为我们的训练前数据。
此任务中有三种标签。标记为“0”的查询和标题对表示强相关性,
这意味着用户在输入查询后会单击标题。那些标为“1”的代表软弱
相关性,这意味着当用户输入查询时,这些标题出现在搜索结果中,但失败了
被用户点击。标签“2”表示查询和标题完全不相关,并且在以下方面是随机的
语义信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号