
elmo模型
1.概述
利用语言模型来获得一个上下文相关的预训练表示,称为ELMo。它使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。
2.模型结构
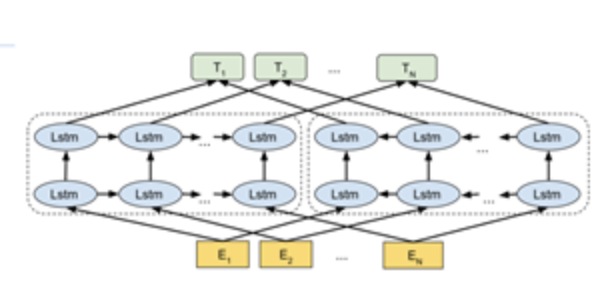
3.双向语言模型
前向概率计算:
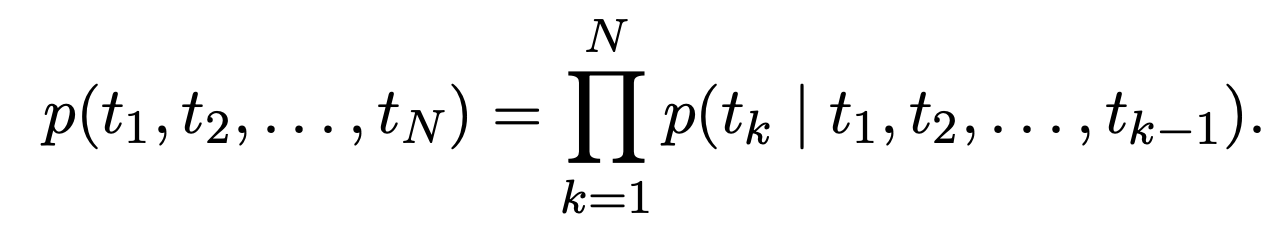
后向概率计算:
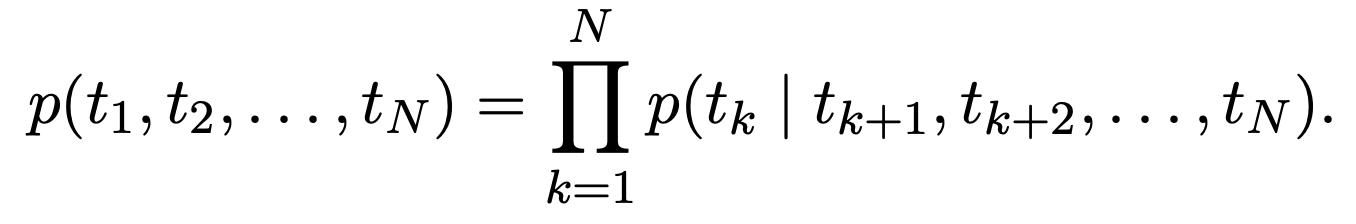
t代表token,即词
最后将前向和后向合并
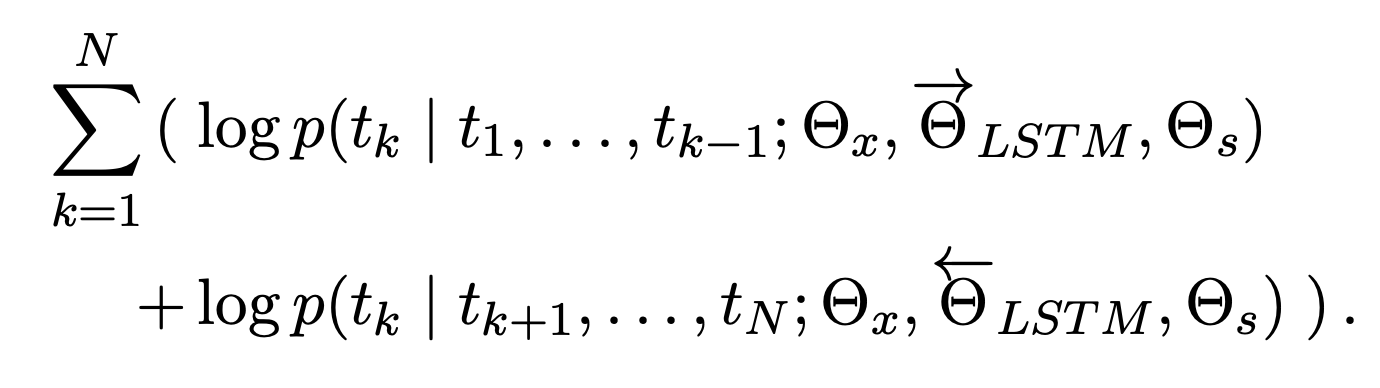
最终输出:
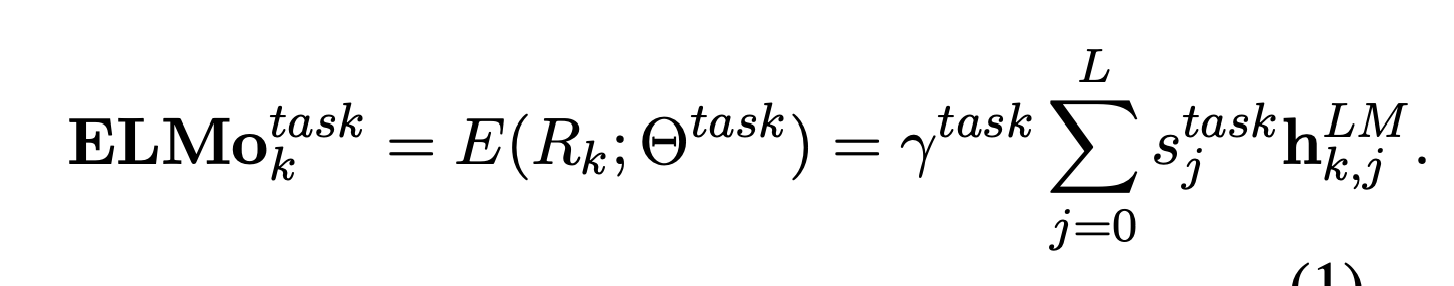
4.tensorflow的实现
import tensorflow_hub as hub # 加载模型 elmo = hub.Module("https://tfhub.dev/google/elmo/2", trainable=True) # 输入的数据集 texts = ["the cat is on the mat", "dogs are in the fog"] embeddings = elmo( texts, signature="default", as_dict=True)["default"] elmo = hub.Module("https://tfhub.dev/google/elmo/2", trainable=True) # 另一种方式输入数据 tokens_input = [["the", "cat", "is", "on", "the", "mat"], ["dogs", "are", "in", "the", "fog", ""]] # 长度,表示tokens_input第一行6一个有效,第二行5个有效 tokens_length = [6, 5] # 生成elmo embedding embeddings = elmo( inputs={ "tokens": tokens_input, "sequence_len": tokens_length }, signature="tokens", as_dict=True)["default"] from tensorflow.python.keras import backend as K sess = K.get_session() array = sess.run(embeddings)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号