

xlent
1.概述
XLNet 与 Bert 有着许多的不同,XLNet 利用一个全新的模型Transformer-XL作为语义表示的骨架, 将置换语言模型的建模作为优化目标,同时在预训练阶段也利用了更多的数据。 最终,XLNet 在多个 NLP 任务上达到了 SOTA 的效果。
2.Two-Stream Self-Attention
接下来的问题是用什么模型来表示。当然有很多种可选的函数(模型),我们这里通过位置来从context 里通过Attention机制提取需要的信息来预测这个位置的词。那么它需要满足如下两点要求:
为了预测只能使用位置信息而不能使用。这是显然的:你预测一个词当然不能知道要预测的是什么词。
数学定义:
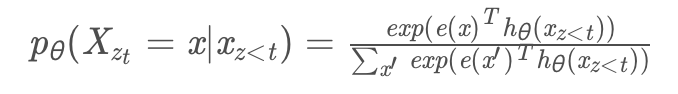



 浙公网安备 33010602011771号
浙公网安备 33010602011771号