
机器翻译
1.概述
机器翻译(machine translation, MT)是用计算机来实现不同语言之间翻译的技术。被翻译的语言通常称为源语言(source language),翻译成的结果语言称为目标语言(target language)。机器翻译即实现从源语言到目标语言转换的过程,是自然语言处理的重要研究领域之一。
2.GRU
我们已经在情感分析一章中介绍了循环神经网络(RNN)及长短时间记忆网络(LSTM)。相比于简单的RNN,LSTM增加了记忆单元(memory cell)、输入门(input gate)、遗忘门(forget gate)及输出门(output gate),这些门及记忆单元组合起来大大提升了RNN处理远距离依赖问题的能力。
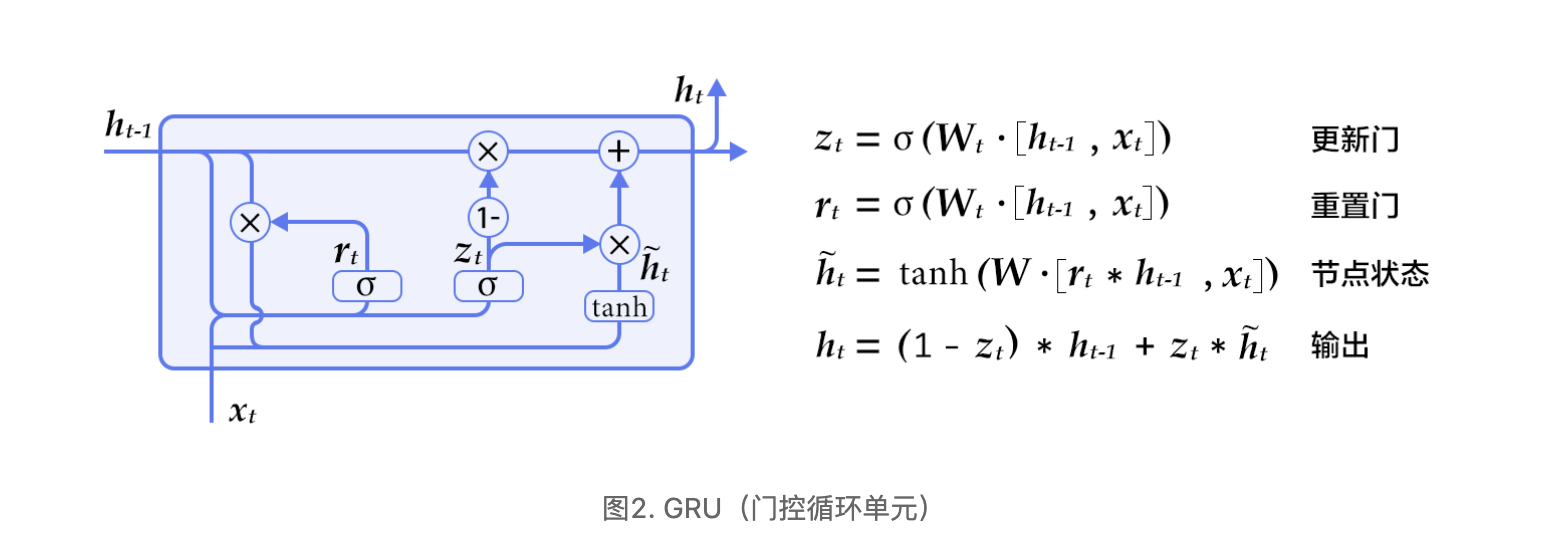
GRU[2]是Cho等人在LSTM上提出的简化版本,也是RNN的一种扩展,如下图所示。GRU单元只有两个门:
- 重置门(reset gate):如果重置门关闭,会忽略掉历史信息,即历史不相干的信息不会影响未来的输出。
- 更新门(update gate):将LSTM的输入门和遗忘门合并,用于控制历史信息对当前时刻隐层输出的影响。如果更新门接近1,会把历史信息传递下去
3.seq2seq模型
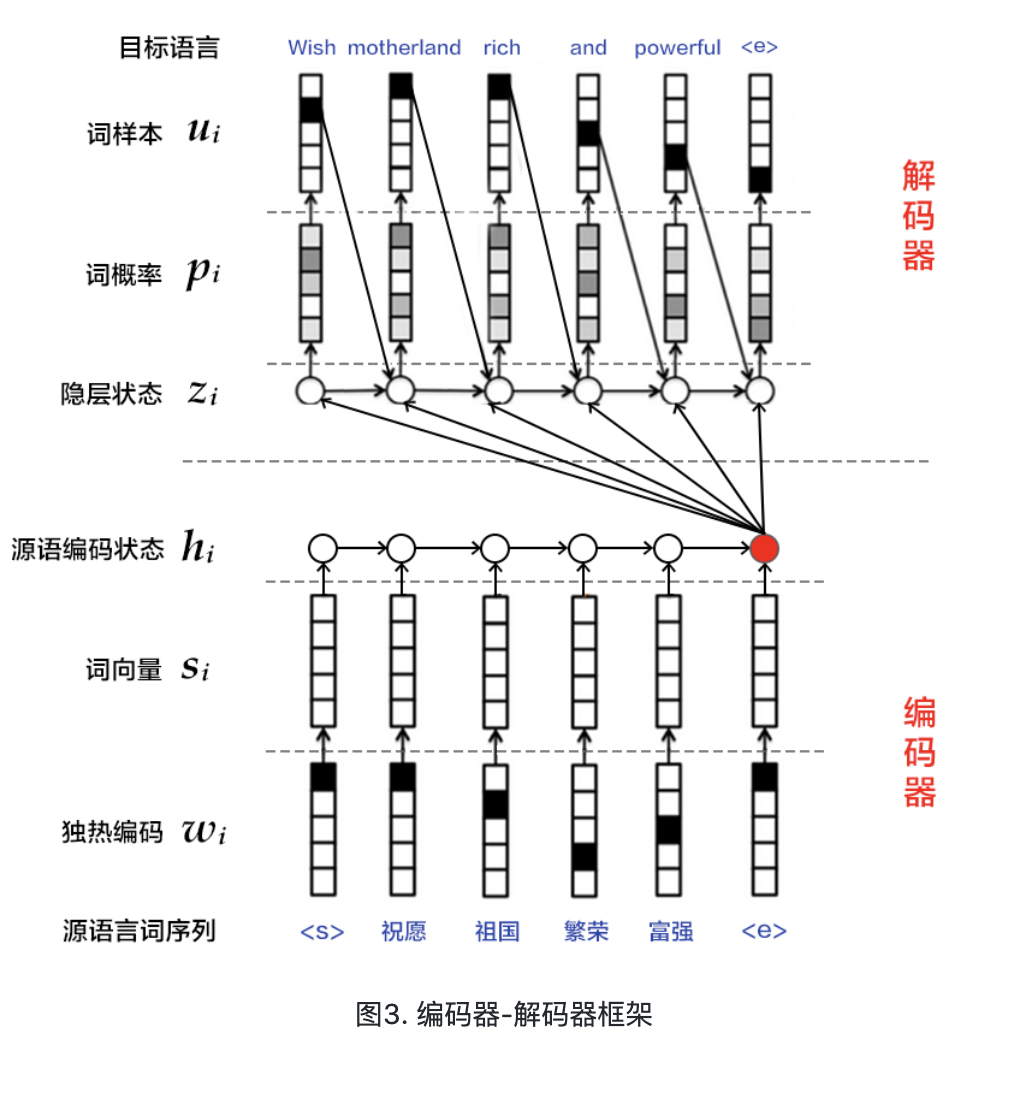
编码器-解码器(Encoder-Decoder)[2]框架用于解决由一个任意长度的源序列到另一个任意长度的目标序列的变换问题。即编码阶段将整个源序列编码成一个向量,解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用RNN实现。
4.注意力机制
如果编码阶段的输出是一个固定维度的向量,会带来以下两个问题:1)不论源语言序列的长度是5个词还是50个词,如果都用固定维度的向量去编码其中的语义和句法结构信息,对模型来说是一个非常高的要求,特别是对长句子序列而言;2)直觉上,当人类翻译一句话时,会对与当前译文更相关的源语言片段上给予更多关注,且关注点会随着翻译的进行而改变。而固定维度的向量则相当于,任何时刻都对源语言所有信息给予了同等程度的关注,这是不合理的。因此,Bahdanau等人[4]引入注意力(attention)机制,可以对编码后的上下文片段进行解码,以此来解决长句子的特征学习问题。下面介绍在注意力机制下的解码器结构。
与简单的解码器不同,这里zizi的计算公式为:

可见,源语言句子的编码向量表示为第ii个词的上下文片段cici,即针对每一个目标语言中的词uiui,都有一个特定的cici与之对应。cici的计算公式如下:
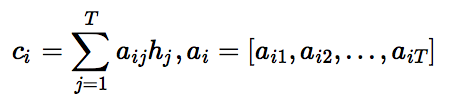
从公式中可以看出,注意力机制是通过对编码器中各时刻的RNN状态hjhj进行加权平均实现的。权重aijaij表示目标语言中第ii个词对源语言中第jj个词的注意力大小,aijaij的计算公式如下:
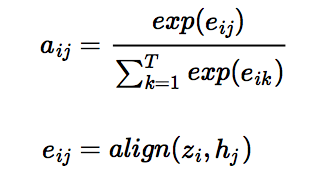
其中,alignalign可以看作是一个对齐模型,用来衡量目标语言中第ii个词和源语言中第jj个词的匹配程度。具体而言,这个程度是通过解码RNN的第ii个隐层状态zizi和源语言句子的第jj个上下文片段hjhj计算得到的。传统的对齐模型中,目标语言的每个词明确对应源语言的一个或多个词(hard alignment);而在注意力模型中采用的是soft alignment,即任何两个目标语言和源语言词间均存在一定的关联,且这个关联强度是由模型计算得到的实数,因此可以融入整个NMT框架,并通过反向传播算法进行训练。

from __future__ import print_function import os import six import numpy as np import paddle import paddle.fluid as fluid import paddle.fluid.layers as layers dict_size = 30000 # 词典大小 bos_id = 0 # 词典中start token对应的id eos_id = 1 # 词典中end token对应的id source_dict_size = target_dict_size = dict_size # 源/目标语言字典大小 word_dim = 512 # 词向量维度 hidden_dim = 512 # 编码器中的隐层大小 decoder_size = hidden_dim # 解码器中的隐层大小 max_length = 256 # 解码生成句子的最大长度 beam_size = 4 # beam search的柱宽度 batch_size = 64 # batch 中的样本数 model_file = "machine_translation" def data_func(is_train=True): src = fluid.data(name="src", shape=[None, None], dtype="int64") src_sequence_length = fluid.data(name="src_sequence_length",shape=[None],dtype="int64") inputs = [src, src_sequence_length] if is_train: trg = fluid.data(name="trg", shape=[None, None], dtype="int64") trg_sequence_length = fluid.data(name="trg_sequence_length", shape=[None], dtype="int64") label = fluid.data(name="label", shape=[None, None], dtype="int64") inputs += [trg, trg_sequence_length, label] loader = fluid.io.DataLoader.from_generator(feed_list=inputs, capacity=10, iterable=True, use_double_buffer=True) return inputs, loader def encoder(src_embedding, src_sequence_length): # 使用GRUCell构建前向RNN layers.dynamic_lstm(input=src_embedding) encoder_fwd_cell = layers.GRUCell(hidden_size=hidden_dim) encoder_fwd_output, fwd_state = layers.rnn( cell=encoder_fwd_cell, inputs=src_embedding, sequence_length=src_sequence_length, time_major=False, is_reverse=False) # 使用GRUCell构建反向RNN encoder_bwd_cell = layers.GRUCell(hidden_size=hidden_dim) encoder_bwd_output, bwd_state = layers.rnn( cell=encoder_bwd_cell, inputs=src_embedding, sequence_length=src_sequence_length, time_major=False, is_reverse=True) # 拼接前向与反向GRU的编码结果得到h encoder_output = layers.concat( input=[encoder_fwd_output, encoder_bwd_output], axis=2) encoder_state = layers.concat(input=[fwd_state, bwd_state], axis=1) return encoder_output, encoder_state class DecoderCell(layers.RNNCell): def __init__(self, hidden_size): self.hidden_size = hidden_size self.gru_cell = layers.GRUCell(hidden_size) def attention(self, hidden, encoder_output, encoder_output_proj, encoder_padding_mask): # 定义attention用以计算context,即 c_i,这里使用Bahdanau attention机制 decoder_state_proj = layers.unsqueeze( layers.fc(hidden, size=self.hidden_size, bias_attr=False), [1]) mixed_state = fluid.layers.elementwise_add( encoder_output_proj, layers.expand(decoder_state_proj, [1, layers.shape(decoder_state_proj)[1], 1])) attn_scores = layers.squeeze( layers.fc(input=mixed_state, size=1, num_flatten_dims=2, bias_attr=False), [2]) if encoder_padding_mask is not None: attn_scores = layers.elementwise_add(attn_scores, encoder_padding_mask) attn_scores = layers.softmax(attn_scores) context = layers.reduce_sum(layers.elementwise_mul(encoder_output, attn_scores, axis=0), dim=1) return context def call(self, step_input, hidden, encoder_output, encoder_output_proj, encoder_padding_mask=None): # Bahdanau attention context = self.attention(hidden, encoder_output, encoder_output_proj, encoder_padding_mask) step_input = layers.concat([step_input, context], axis=1) # GRU output, new_hidden = self.gru_cell(step_input, hidden) return output, new_hidden def decoder(encoder_output, encoder_output_proj, encoder_state, encoder_padding_mask, trg=None, is_train=True): # 定义 RNN 所需要的组件 decoder_cell = DecoderCell(hidden_size=decoder_size) decoder_initial_states = layers.fc(encoder_state, size=decoder_size, act="tanh") trg_embeder = lambda x: fluid.embedding(input=x, size=[target_dict_size, hidden_dim], dtype="float32", param_attr=fluid.ParamAttr( name="trg_emb_table")) output_layer = lambda x: layers.fc(x, size=target_dict_size, num_flatten_dims=len(x.shape) - 1, param_attr=fluid.ParamAttr(name= "output_w")) if is_train: # 训练 # 训练时使用 `layers.rnn` 构造由 `cell` 指定的循环神经网络 # 循环的每一步从 `inputs` 中切片产生输入,并执行 `cell.call` decoder_output, _ = layers.rnn( cell=decoder_cell, inputs=trg_embeder(trg), initial_states=decoder_initial_states, time_major=False, encoder_output=encoder_output, encoder_output_proj=encoder_output_proj, encoder_padding_mask=encoder_padding_mask) decoder_output = output_layer(decoder_output) else: # 基于 beam search 的预测生成 # beam search 时需要将用到的形为 `[batch_size, ...]` 的张量扩展为 `[batch_size* beam_size, ...]` encoder_output = layers.BeamSearchDecoder.tile_beam_merge_with_batch( encoder_output, beam_size) encoder_output_proj = layers.BeamSearchDecoder.tile_beam_merge_with_batch( encoder_output_proj, beam_size) encoder_padding_mask = layers.BeamSearchDecoder.tile_beam_merge_with_batch( encoder_padding_mask, beam_size) # BeamSearchDecoder 定义了单步解码的操作:`cell.call` + `beam_search_step` beam_search_decoder = layers.BeamSearchDecoder(cell=decoder_cell, start_token=bos_id, end_token=eos_id, beam_size=beam_size, embedding_fn=trg_embeder, output_fn=output_layer) # 使用 layers.dynamic_decode 动态解码 # 重复执行 `decoder.step()` 直到其返回的表示完成状态的张量中的值全部为True或解码步骤达到 `max_step_num` decoder_output, _ = layers.dynamic_decode( decoder=beam_search_decoder, inits=decoder_initial_states, max_step_num=max_length, output_time_major=False, encoder_output=encoder_output, encoder_output_proj=encoder_output_proj, encoder_padding_mask=encoder_padding_mask) return decoder_output def model_func(inputs, is_train=True): # 源语言输入 src = inputs[0] src_sequence_length = inputs[1] src_embeder = lambda x: fluid.embedding( input=x, size=[source_dict_size, hidden_dim], dtype="float32", param_attr=fluid.ParamAttr(name="src_emb_table")) src_embedding = src_embeder(src) # 编码器 encoder_output, encoder_state = encoder(src_embedding, src_sequence_length) encoder_output_proj = layers.fc(input=encoder_output, size=decoder_size, num_flatten_dims=2, bias_attr=False) src_mask = layers.sequence_mask(src_sequence_length, maxlen=layers.shape(src)[1], dtype="float32") encoder_padding_mask = (src_mask - 1.0) * 1e9 # 目标语言输入,训练时有、预测生成时无该输入 trg = inputs[2] if is_train else None # 解码器 output = decoder(encoder_output=encoder_output, encoder_output_proj=encoder_output_proj, encoder_state=encoder_state, encoder_padding_mask=encoder_padding_mask, trg=trg, is_train=is_train) return output def loss_func(logits, label, trg_sequence_length): probs = layers.softmax(logits) # 使用交叉熵损失函数 loss = layers.cross_entropy(input=probs, label=label) # 根据长度生成掩码,并依此剔除 padding 部分计算的损失 trg_mask = layers.sequence_mask(trg_sequence_length, maxlen=layers.shape(logits)[1], dtype="float32") avg_cost = layers.reduce_sum(loss * trg_mask) / layers.reduce_sum(trg_mask) return avg_cost def optimizer_func(): # 设置梯度裁剪 fluid.clip.set_gradient_clip( clip=fluid.clip.GradientClipByGlobalNorm(clip_norm=5.0)) # 定义先增后降的学习率策略 lr_decay = fluid.layers.learning_rate_scheduler.noam_decay(hidden_dim, 1000) return fluid.optimizer.Adam( learning_rate=lr_decay, regularization=fluid.regularizer.L2DecayRegularizer( regularization_coeff=1e-4)) def inputs_generator(batch_size, pad_id, is_train=True): data_generator = fluid.io.shuffle( paddle.dataset.wmt16.train(source_dict_size, target_dict_size), buf_size=10000) if is_train else paddle.dataset.wmt16.test( source_dict_size, target_dict_size) batch_generator = fluid.io.batch(data_generator, batch_size=batch_size) # 对 batch 内的数据进行 padding def _pad_batch_data(insts, pad_id): seq_lengths = np.array(list(map(len, insts)), dtype="int64") max_len = max(seq_lengths) pad_data = np.array( [inst + [pad_id] * (max_len - len(inst)) for inst in insts], dtype="int64") return pad_data, seq_lengths def _generator(): for batch in batch_generator(): batch_src = [ins[0] for ins in batch] src_data, src_lengths = _pad_batch_data(batch_src, pad_id) inputs = [src_data, src_lengths] if is_train: #训练时包含 target 和 label 数据 batch_trg = [ins[1] for ins in batch] trg_data, trg_lengths = _pad_batch_data(batch_trg, pad_id) batch_lbl = [ins[2] for ins in batch] lbl_data, _ = _pad_batch_data(batch_lbl, pad_id) inputs += [trg_data, trg_lengths, lbl_data] yield inputs return _generator train_prog = fluid.Program() startup_prog = fluid.Program() with fluid.program_guard(train_prog, startup_prog): with fluid.unique_name.guard(): inputs, loader = data_func(is_train=True) logits = model_func(inputs, is_train=True) loss = loss_func(logits, inputs[-1], inputs[-2]) optimizer = optimizer_func() optimizer.minimize(loss) use_cuda = False places = fluid.cuda_places() if use_cuda else fluid.cpu_places() # 设置数据源 loader.set_batch_generator(inputs_generator(batch_size, eos_id, is_train=True), places=places) # 定义执行器,初始化参数并绑定Program exe = fluid.Executor(places[0]) exe.run(startup_prog) prog = fluid.CompiledProgram(train_prog).with_data_parallel( loss_name=loss.name) EPOCH_NUM = 2 for pass_id in six.moves.xrange(EPOCH_NUM): batch_id = 0 for data in loader(): loss_val = exe.run(prog, feed=data, fetch_list=[loss])[0] print('pass_id: %d, batch_id: %d, loss: %f' % (pass_id, batch_id, loss_val)) batch_id += 1 # 保存模型 fluid.save(train_prog, model_file)
infer_prog = fluid.Program() startup_prog = fluid.Program() with fluid.program_guard(infer_prog, startup_prog): with fluid.unique_name.guard(): inputs, loader = data_func(is_train=False) predict_seqs = model_func(inputs, is_train=False) use_cuda = False # 设置训练设备 places = fluid.cuda_places() if use_cuda else fluid.cpu_places() # 设置数据源 loader.set_batch_generator(inputs_generator(batch_size, eos_id, is_train=False), places=places) # 定义执行器,加载参数并绑定Program exe = fluid.Executor(places[0]) exe.run(startup_prog) fluid.load(infer_prog, model_file, exe) prog = fluid.CompiledProgram(infer_prog).with_data_parallel() # 获取 id 到 word 映射的词典 src_idx2word = paddle.dataset.wmt16.get_dict( "en", source_dict_size, reverse=True) trg_idx2word = paddle.dataset.wmt16.get_dict( "de", target_dict_size, reverse=True) # 循环测试数据 for data in loader(): seq_ids = exe.run(prog, feed=data, fetch_list=[predict_seqs])[0] for ins_idx in range(seq_ids.shape[0]): print("Original sentence:") src_seqs = np.array(data[0]["src"]) print(" ".join([ src_idx2word[idx] for idx in src_seqs[ins_idx][1:] if idx != eos_id ])) print("Translated sentence:") for beam_idx in range(beam_size): seq = [ trg_idx2word[idx] for idx in seq_ids[ins_idx, :, beam_idx] if idx != eos_id ] print(" ".join(seq).encode("utf8"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号