
阅读理解-bidaf模型
1.概述
BiDAF采用多阶段的、层次化处理,使得可以捕获原文不同粒度的特征。同时使用双向的attention流机制以在without early summarization的情况下获得相关问句和原文之间的表征。
2.模型结构
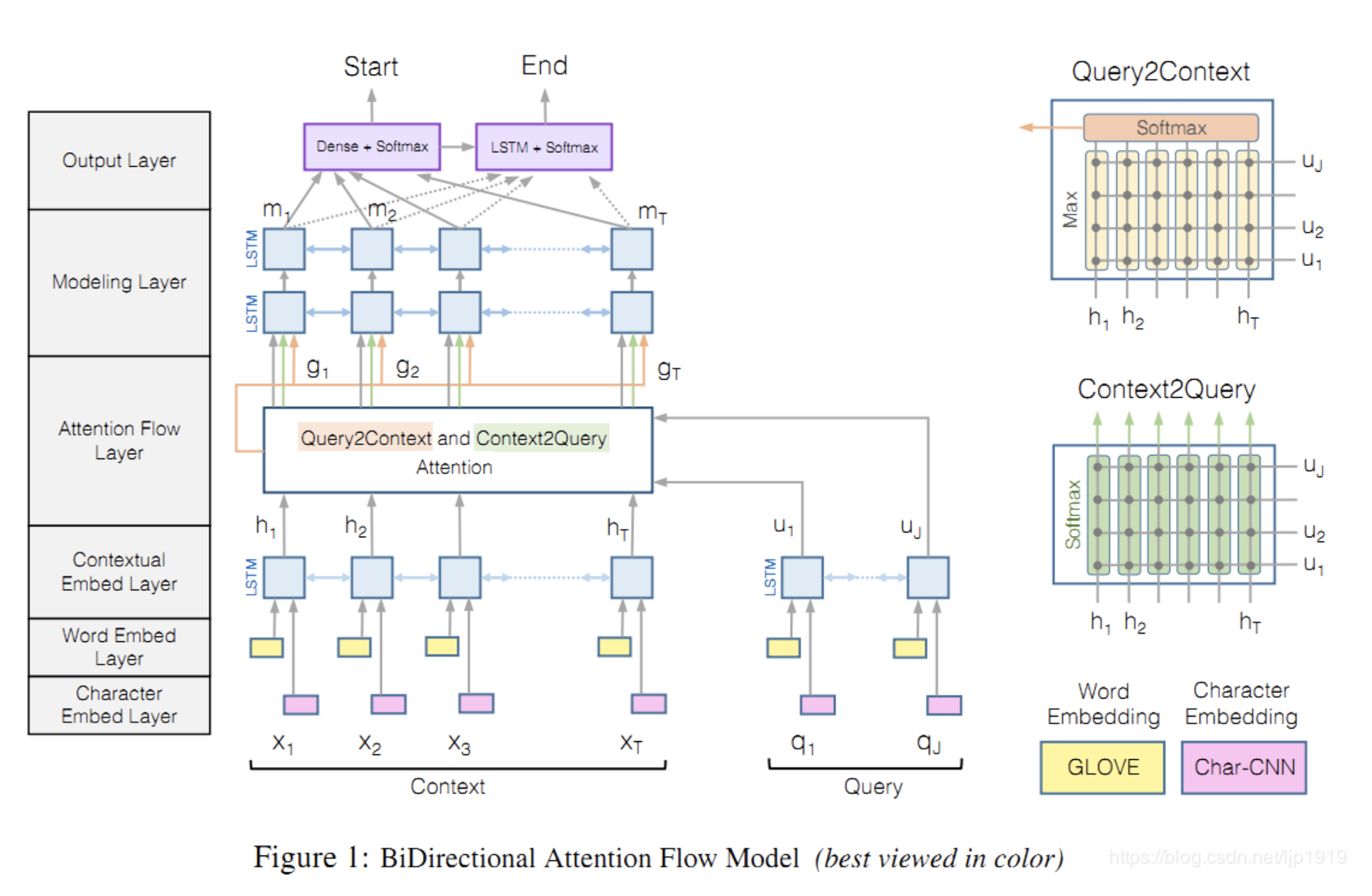
输入是问题和文章上下文的词和字符
1).步骤1,词嵌入和字符嵌入
q_ids = layers.data(name='q_ids', shape=[1], dtype='int64', lod_level=lod_level) p_ids = layers.data(name='p_ids', shape=[1], dtype='int64', lod_level=lod_level) p_embs = embedding(p_ids, emb_shape, args) q_embs = embedding(q_ids, emb_shape, args)
2).lstm,然后计算attn
该层用于链接和融合来自原文和问句中词的信息。不同于以往的注意力机制,将问句和原文总结概括为单一的特征向量。本文每个时刻的注意力向量都与其之前层的嵌入相关,且都可以流向之后的网络层。这种设计方案可以减缓由于过早归纳总结而导致的信息缺失。
该层的输入是原文H\rm HH和问句UUU向量,输出是 context words 的 query-aware vector ,以及上一层传下来的contextualembeddings。做context−to−query以及query−to−context两个方向的‘attention‘。做法是一样,都是先计算相似度矩阵,再归一化计算attention分数,最后与原始矩阵相乘得到修正的向量矩阵。c2q和q2c共享相似度矩阵,原文(,以及上一层传下来的 contextual embeddings。做 context-to-query 以及 query-to-context 两个方向的`attention`。做法是一样,都是先计算相似度矩阵,再归一化计算 attention 分数,最后与原始矩阵相乘得到修正的向量矩阵。c2q 和 q2c 共享相似度矩阵,原文(,以及上一层传下来的contextualembeddings。做context−to−query以及query−to−context两个方向的‘attention‘。做法是一样,都是先计算相似度矩阵,再归一化计算attention分数,最后与原始矩阵相乘得到修正的向量矩阵。c2q和q2c共享相似度矩阵,原文(H)和问句)和问句)和问句U的相似度矩阵的相似度矩阵的相似度矩阵计算如下:
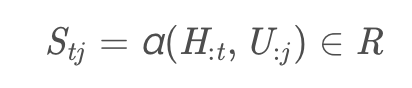
其中Stj是第 t 个 context word 和第 j 个 query word 之间的相似度
α: 可训练的scalar function,用以encode两个输入向量的相似度。
H:t H 的第 t 个列向量
U:j U 的第 j 个列向量
![]()
表示element-wise multiplication。
[;]是向量在行上的拼接。隐式乘法是矩阵乘法。
下面我们介绍用SSS获得两个方向上的attentions 和attended vectors。
Context-to-query Attention:
Context-to-query (C2Q) attention计算对每一个 context word 而言哪些 query words 和它最相关。前面得到了相似度矩阵,现在 softmax 对列归一化,然后计算 query 向量加权和得到Uˆ
![]()
其中at表示第t个contex word对于query words的注意力权重。每个被注意到的query vector计算如下:
U^ = ![]()
可以看出Uˆ是 2dxT 的矩阵,表示整个contex相关的query vector。
Query-to-context Attention:
query-to-context attention(Q2C): 计算对每一个 query word 而言哪些 context words 和它最相关,这些 context words 对回答问题很重要。取相似度矩阵每列最大值,对其进行 softmax 归一化得到b
![]()
再通过加权和计算相关的 context 向量,
![]()
即在contex中将相对于query最重要的词进行加权求和。
然后hˆ沿着列方向 tile T 次得到
最后,contextual embeddings和attention vectors拼接起来得到G。G中每个列向量可以视为每个contex word的query-aware表征。
![]()
其中G:t
是第t个列向量(对应第t个 contex word)。β是一个trainable vector function,它融合了3个输入向量。dG
是β函数的输出维度。β可以是任意的神经网络,如多层感知机。
不过在本文中简单的拼接效果也不错:

def bi_lstm_encoder(input_seq, gate_size, para_name, args): input_forward_proj = layers.fc( input=input_seq, param_attr=fluid.ParamAttr(name=para_name + '_fw_gate_w'), size=gate_size * 4, act=None, bias_attr=False) input_reversed_proj = layers.fc( input=input_seq, param_attr=fluid.ParamAttr(name=para_name + '_bw_gate_w'), size=gate_size * 4, act=None, bias_attr=False) forward, _ = layers.dynamic_lstm( input=input_forward_proj, size=gate_size * 4, use_peepholes=False, param_attr=fluid.ParamAttr(name=para_name + '_fw_lstm_w'), bias_attr=fluid.ParamAttr(name=para_name + '_fw_lstm_b')) reversed, _ = layers.dynamic_lstm( input=input_reversed_proj, param_attr=fluid.ParamAttr(name=para_name + '_bw_lstm_w'), bias_attr=fluid.ParamAttr(name=para_name + '_bw_lstm_b'), size=gate_size * 4, is_reverse=True, use_peepholes=False) encoder_out = layers.concat(input=[forward, reversed], axis=1) return encoder_out def attn_flow(q_enc, p_enc, p_ids_name, args): tag = p_ids_name + "__" drnn = layers.DynamicRNN() with drnn.block(): h_cur = drnn.step_input(p_enc) u_all = drnn.static_input(q_enc) h_expd = layers.sequence_expand(x=h_cur, y=u_all) s_t_mul = layers.elementwise_mul(x=u_all, y=h_expd, axis=0) s_t_sum = layers.reduce_sum(input=s_t_mul, dim=1, keep_dim=True) s_t_re = layers.reshape(s_t_sum, shape=[-1, 0]) s_t = layers.sequence_softmax(input=s_t_re) u_expr = layers.elementwise_mul(x=u_all, y=s_t, axis=0) u_expr = layers.sequence_pool(input=u_expr, pool_type='sum') b_t = layers.sequence_pool(input=s_t_sum, pool_type='max') drnn.output(u_expr, b_t) U_expr, b = drnn() b_norm = layers.sequence_softmax(input=b) h_expr = layers.elementwise_mul(x=p_enc, y=b_norm, axis=0) h_expr = layers.sequence_pool(input=h_expr, pool_type='sum') H_expr = layers.sequence_expand(x=h_expr, y=p_enc) H_expr = layers.lod_reset(x=H_expr, y=p_enc) h_u = layers.elementwise_mul(x=p_enc, y=U_expr, axis=0) h_h = layers.elementwise_mul(x=p_enc, y=H_expr, axis=0) g = layers.concat(input=[p_enc, U_expr, h_u, h_h], axis=1) return dropout(g, args) drnn = layers.DynamicRNN() with drnn.block(): p_emb = drnn.step_input(p_embs) q_emb = drnn.step_input(q_embs) p_enc = bi_lstm_encoder(p_emb, 'p_enc', hidden_size, args) q_enc = bi_lstm_encoder(q_emb, 'q_enc', hidden_size, args) # stage 2:match g_i = attn_flow(q_enc, p_enc, p_ids_name, args) # stage 3:fusion m_i = fusion(g_i, args) drnn.output(m_i, q_enc) ms, q_encs = drnn()
3).重新通过lstm计算预测的结果


def point_network_decoder(p_vec, q_vec, hidden_size, args): """Output layer - pointer network""" tag = 'pn_decoder_' init_random = fluid.initializer.Normal(loc=0.0, scale=1.0) random_attn = layers.create_parameter( shape=[1, hidden_size], dtype='float32', default_initializer=init_random) random_attn = layers.fc( input=random_attn, size=hidden_size, act=None, param_attr=fluid.ParamAttr(name=tag + 'random_attn_fc_w'), bias_attr=fluid.ParamAttr(name=tag + 'random_attn_fc_b')) random_attn = layers.reshape(random_attn, shape=[-1]) U = layers.fc(input=q_vec, param_attr=fluid.ParamAttr(name=tag + 'q_vec_fc_w'), bias_attr=False, size=hidden_size, act=None) + random_attn U = layers.tanh(U) logits = layers.fc(input=U, param_attr=fluid.ParamAttr(name=tag + 'logits_fc_w'), bias_attr=fluid.ParamAttr(name=tag + 'logits_fc_b'), size=1, act=None) scores = layers.sequence_softmax(input=logits) pooled_vec = layers.elementwise_mul(x=q_vec, y=scores, axis=0) pooled_vec = layers.sequence_pool(input=pooled_vec, pool_type='sum') init_state = layers.fc( input=pooled_vec, param_attr=fluid.ParamAttr(name=tag + 'init_state_fc_w'), bias_attr=fluid.ParamAttr(name=tag + 'init_state_fc_b'), size=hidden_size, act=None) def custom_dynamic_rnn(p_vec, init_state, hidden_size, para_name, args): tag = para_name + "custom_dynamic_rnn_" def static_rnn(step, p_vec=p_vec, init_state=None, para_name='', args=args): tag = para_name + "static_rnn_" ctx = layers.fc( input=p_vec, param_attr=fluid.ParamAttr(name=tag + 'context_fc_w'), bias_attr=fluid.ParamAttr(name=tag + 'context_fc_b'), size=hidden_size, act=None) beta = [] c_prev = init_state m_prev = init_state for i in range(step): m_prev0 = layers.fc( input=m_prev, size=hidden_size, act=None, param_attr=fluid.ParamAttr(name=tag + 'm_prev0_fc_w'), bias_attr=fluid.ParamAttr(name=tag + 'm_prev0_fc_b')) m_prev1 = layers.sequence_expand(x=m_prev0, y=ctx) Fk = ctx + m_prev1 Fk = layers.tanh(Fk) logits = layers.fc( input=Fk, size=1, act=None, param_attr=fluid.ParamAttr(name=tag + 'logits_fc_w'), bias_attr=fluid.ParamAttr(name=tag + 'logits_fc_b')) scores = layers.sequence_softmax(input=logits) attn_ctx = layers.elementwise_mul(x=p_vec, y=scores, axis=0) attn_ctx = layers.sequence_pool(input=attn_ctx, pool_type='sum') hidden_t, cell_t = lstm_step( attn_ctx, hidden_t_prev=m_prev, cell_t_prev=c_prev, size=hidden_size, para_name=tag, args=args) m_prev = hidden_t c_prev = cell_t beta.append(scores) return beta return static_rnn( 2, p_vec=p_vec, init_state=init_state, para_name=para_name) fw_outputs = custom_dynamic_rnn(p_vec, init_state, hidden_size, tag + "fw_", args) bw_outputs = custom_dynamic_rnn(p_vec, init_state, hidden_size, tag + "bw_", args) start_prob = layers.elementwise_add( x=fw_outputs[0], y=bw_outputs[1], axis=0) / 2 end_prob = layers.elementwise_add( x=fw_outputs[1], y=bw_outputs[0], axis=0) / 2 return start_prob, end_prob
输入是G\rm GG(即context中单词的 query-aware representation结果),
再经过一个双层的 Bi-LSTM 得到$ M\in R^{2d \times T},捕捉的是在给定query下contexwords之间的关系。注意和contextualembeddinglayer区分开,contextualembeddinglayer捕获的contexwords之间关系并不依赖于query。由于每个方向的输出结果尺寸为,捕捉的是在给定query下contex words之间的关系。注意和contextual embedding layer区分开,contextual embedding layer捕获的contex words之间关系并不依赖于query。由于每个方向的输出结果尺寸为,捕捉的是在给定query下contexwords之间的关系。注意和contextualembeddinglayer区分开,contextualembeddinglayer捕获的contexwords之间关系并不依赖于query。由于每个方向的输出结果尺寸为d,所以,所以,所以M$的尺寸为2d×T2d 。MMM的每一个列向量都包含了对应单词关于整个 context 和 query 的上下文信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号