



词向量
1.网络结构
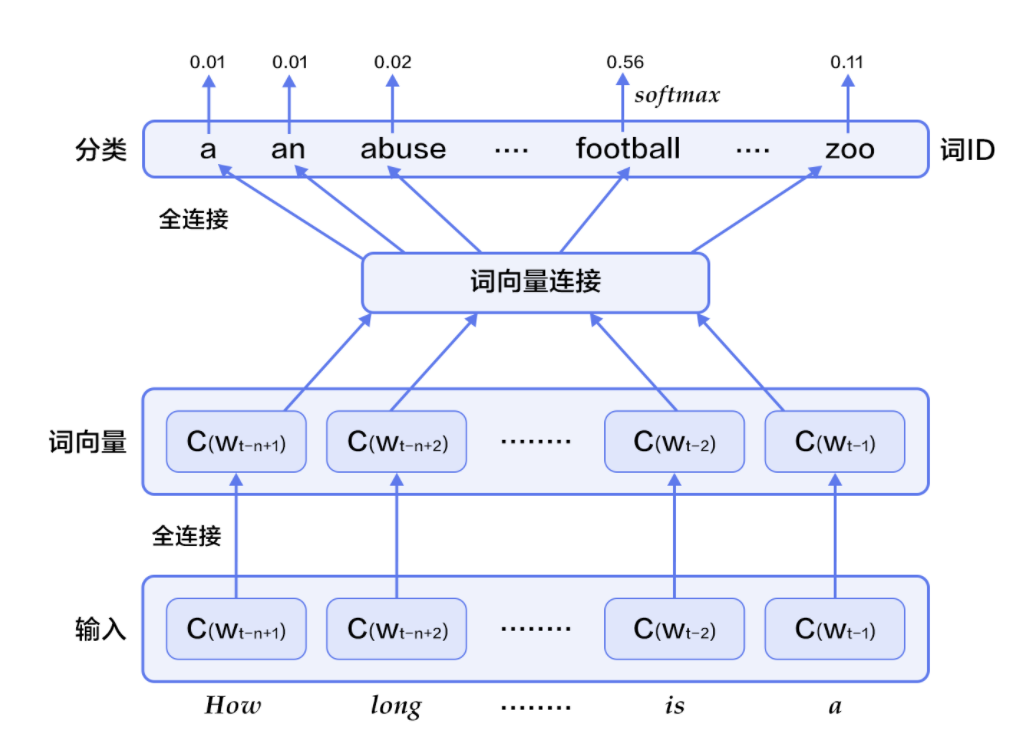
样本为一个词 和一个词的前k个词和后k个词,目标是推算样本词
2.代码实现
引入环境
from __future__ import print_function import paddle import paddle.fluid as fluid import six import numpy import math EMBED_SIZE = 32 # embedding维度 HIDDEN_SIZE = 256 # 隐层大小 N = 5 # ngram大小,这里固定取5 BATCH_SIZE = 100 # batch大小 PASS_NUM = 100 # 训练轮数 use_cuda = False # 如果用GPU训练,则设置为True word_dict = paddle.dataset.imikolov.build_dict() dict_size = len(word_dict)
定义网络,首先映射词到词向量,然后做连接,结果若干个隐层后映射为一个word_dict的向量,然后用softmax来计算结果的概率,最后优化此结果
def inference_program(words, is_sparse): embed_first = fluid.embedding( input=words[0], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_second = fluid.embedding( input=words[1], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_third = fluid.embedding( input=words[2], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') embed_fourth = fluid.embedding( input=words[3], size=[dict_size, EMBED_SIZE], dtype='float32', is_sparse=is_sparse, param_attr='shared_w') concat_embed = fluid.layers.concat( input=[embed_first, embed_second, embed_third, embed_fourth], axis=1) hidden1 = fluid.layers.fc(input=concat_embed, size=HIDDEN_SIZE, act='sigmoid') predict_word = fluid.layers.fc(input=hidden1, size=dict_size, act='softmax') return predict_word def train_program(predict_word): # 'next_word'的定义必须要在inference_program的声明之后, # 否则train program输入数据的顺序就变成了[next_word, firstw, secondw, # thirdw, fourthw], 这是不正确的. next_word = fluid.data(name='nextw', shape=[None, 1], dtype='int64') cost = fluid.layers.cross_entropy(input=predict_word, label=next_word) avg_cost = fluid.layers.mean(cost) return avg_cost def optimizer_func(): return fluid.optimizer.AdagradOptimizer( learning_rate=3e-3, regularization=fluid.regularizer.L2DecayRegularizer(8e-4))
训练数据
def train(if_use_cuda, params_dirname, is_sparse=True): place = fluid.CUDAPlace(0) if if_use_cuda else fluid.CPUPlace() train_reader = paddle.batch( paddle.dataset.imikolov.train(word_dict, N), BATCH_SIZE) test_reader = paddle.batch( paddle.dataset.imikolov.test(word_dict, N), BATCH_SIZE) first_word = fluid.data(name='firstw', shape=[None, 1], dtype='int64') second_word = fluid.data(name='secondw', shape=[None, 1], dtype='int64') third_word = fluid.data(name='thirdw', shape=[None, 1], dtype='int64') forth_word = fluid.data(name='fourthw', shape=[None, 1], dtype='int64') next_word = fluid.data(name='nextw', shape=[None, 1], dtype='int64') word_list = [first_word, second_word, third_word, forth_word, next_word] feed_order = ['firstw', 'secondw', 'thirdw', 'fourthw', 'nextw'] main_program = fluid.default_main_program() star_program = fluid.default_startup_program() predict_word = inference_program(word_list, is_sparse) avg_cost = train_program(predict_word) test_program = main_program.clone(for_test=True) optimizer = optimizer_func() optimizer.minimize(avg_cost) exe = fluid.Executor(place) def train_test(program, reader): count = 0 feed_var_list = [ program.global_block().var(var_name) for var_name in feed_order ] feeder_test = fluid.DataFeeder(feed_list=feed_var_list, place=place) test_exe = fluid.Executor(place) accumulated = len([avg_cost]) * [0] for test_data in reader(): avg_cost_np = test_exe.run( program=program, feed=feeder_test.feed(test_data), fetch_list=[avg_cost]) accumulated = [ x[0] + x[1][0] for x in zip(accumulated, avg_cost_np) ] count += 1 return [x / count for x in accumulated] def train_loop(): step = 0 feed_var_list_loop = [ main_program.global_block().var(var_name) for var_name in feed_order ] feeder = fluid.DataFeeder(feed_list=feed_var_list_loop, place=place) exe.run(star_program) for pass_id in range(PASS_NUM): for data in train_reader(): avg_cost_np = exe.run( main_program, feed=feeder.feed(data), fetch_list=[avg_cost]) if step % 10 == 0: outs = train_test(test_program, test_reader) print("Step %d: Average Cost %f" % (step, outs[0])) # 整个训练过程要花费几个小时,如果平均损失低于5.8, # 我们就认为模型已经达到很好的效果可以停止训练了。 # 注意5.8是一个相对较高的值,为了获取更好的模型,可以将 # 这里的阈值设为3.5,但训练时间也会更长。 if outs[0] < 5.8: if params_dirname is not None: fluid.io.save_inference_model(params_dirname, [ 'firstw', 'secondw', 'thirdw', 'fourthw' ], [predict_word], exe) return step += 1 if math.isnan(float(avg_cost_np[0])): sys.exit("got NaN loss, training failed.") raise AssertionError("Cost is too large {0:2.2}".format(avg_cost_np[0])) train_loop()

