

情感分析
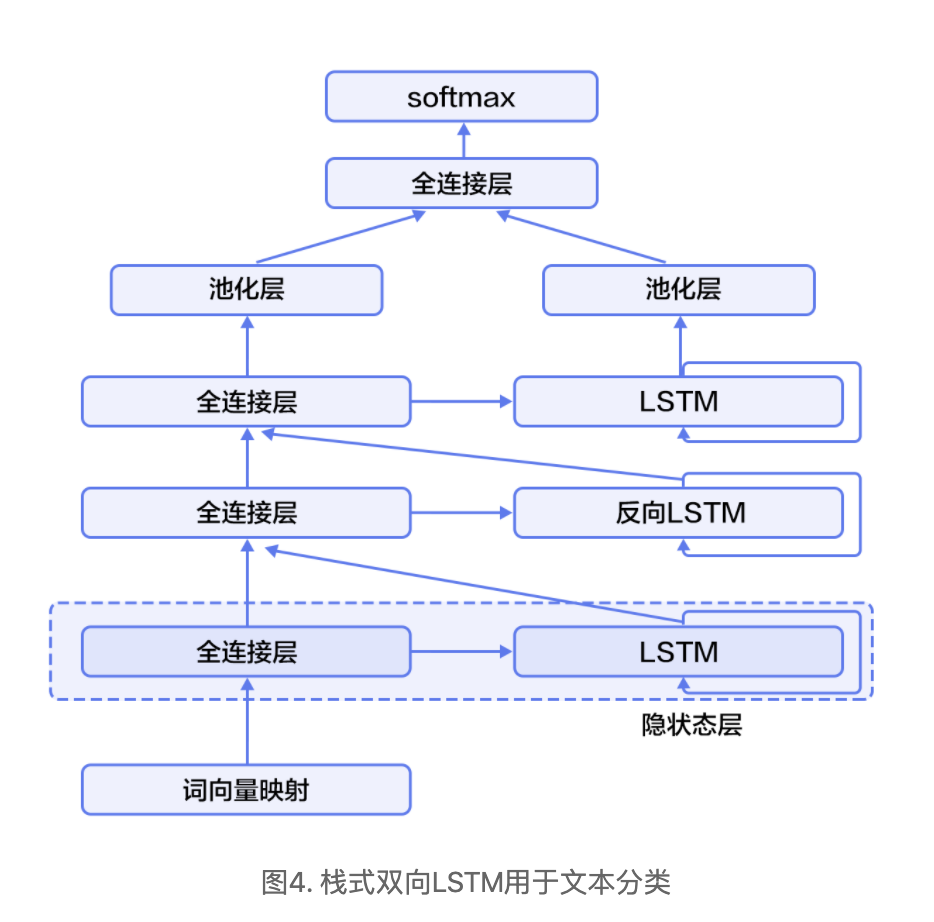
1.网络结构
2.数据源
数据集的训练集和测试集分别包含25000个已标注过的电影评论。其中,负面评论的得分小于等于4,正面评论的得分大于等于7,满分10分。
from __future__ import print_function import paddle import paddle.fluid as fluid import numpy as np import sys import math CLASS_DIM = 2 #情感分类的类别数 EMB_DIM = 128 #词向量的维度 HID_DIM = 512 #隐藏层的维度 STACKED_NUM = 3 #LSTM双向栈的层数 BATCH_SIZE = 128 #batch的大小 word_dict = paddle.dataset.imdb.word_dict() train_reader = paddle.batch( paddle.reader.shuffle( paddle.dataset.imdb.train(word_dict), buf_size=25000), batch_size=BATCH_SIZE) test_reader = paddle.batch( paddle.dataset.imdb.test(word_dict), batch_size=BATCH_SIZE)
word_dict是词和index的映射,paddle.dataset.imdb.train(word_dict)中获得的数据集格式为[([index1,index2……,indexn],a)]a是0或1
use_cuda = False place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() exe = fluid.Executor(place)
data = fluid.data(name="word", shape=[None,1], dtype="int64", lod_level=1)
创建程序,并定义数据源头
3.构建神经网络
emb = fluid.layers.embedding(input=data, size=[len(word_dict), 128], is_sparse=True) fc1 = fluid.layers.fc(input=emb, size=HID_DIM) lstm1, cell1 = fluid.layers.dynamic_lstm(input=fc1, size=HID_DIM) inputs = [fc1, lstm1] for i in range(2, STACKED_NUM + 1): fc = fluid.layers.fc(input=inputs, size=HID_DIM) lstm, cell = fluid.layers.dynamic_lstm(input=fc, size=HID_DIM, is_reverse=(i % 2) == 0) inputs = [fc, lstm] fc_last = fluid.layers.sequence_pool(input=inputs[0], pool_type='max') lstm_last = fluid.layers.sequence_pool(input=inputs[1], pool_type='max') prediction = fluid.layers.fc(input=[fc_last, lstm_last], size=CLASS_DIM, act='softmax')
4.构建损失函数和优化器
label = fluid.data(name="label", shape=[None, 1], dtype="int64") cost = fluid.layers.cross_entropy(input=prediction, label=label) avg_cost = fluid.layers.mean(cost) accuracy = fluid.layers.accuracy(input=prediction, label=label) sgd_optimizer = fluid.optimizer.Adagrad(learning_rate=0.002) sgd_optimizer.minimize(avg_cost)
5.初始化项目定义feeder
exe.run(fluid.default_startup_program()) feed_var_list_loop = [main_program.global_block().var(var_name) for var_name in ['word', 'label']] feeder = fluid.DataFeeder(feed_list=feed_var_list_loop, place=place) test_program = fluid.default_main_program().clone(for_test=True)
6.训练数据
_end = False for epoch_id in range(pass_num): if _end: break for step_id, data in enumerate(train_reader()): metrics = exe.run(main_program, feed=feeder.feed(data),fetch_list=[avg_cost, accuracy]) if step_id == 30: if params_dirname is not None: fluid.io.save_inference_model('o.model', ["words"], prediction, exe) _end = True break

