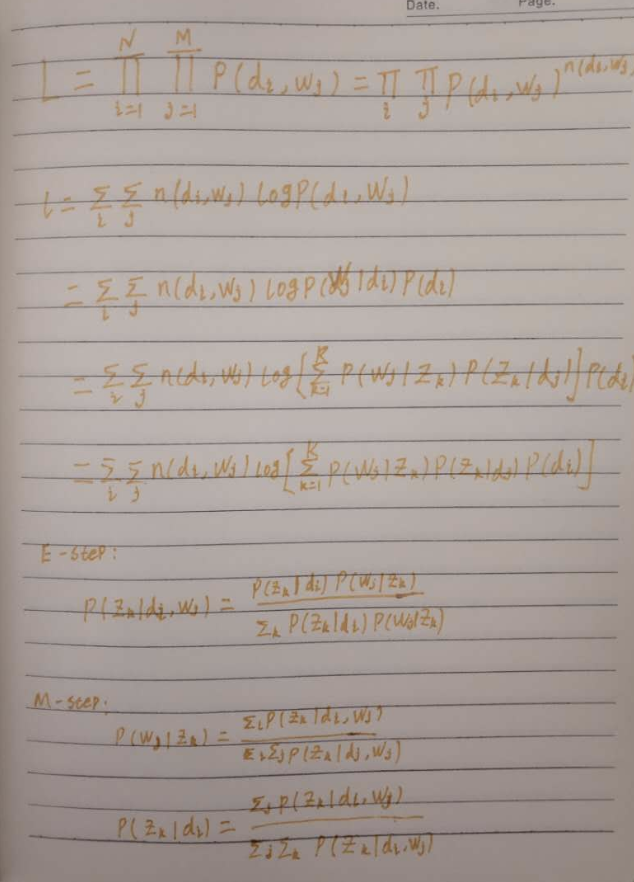主题模型
1.概述
一篇文章的每个词都是以一定的概率选择了某个主题,并从这个主题中以一定的概率选择某个词而组成的。
P(单词|文档) = P(单词|主题)*P(主题|文档)
生成过程
对于语料中每篇文档,主题模型定义如下生成过程:
(1).对每一篇文档,从主题分布中抽取一个主题;
(2).从上述被抽到的主题所对应的单词分布中抽取一个单词;
(3).重复上述过程直至遍历文档中的每一个单词。
学习过程
算法开始时,先随机地给theta(d)和phi(t)赋值。然后:
1.针对一个特定的文档ds中的第i单词wi,如果令该单词对应的topic为tj,可以把上述公式改写为:Pj(wi|ds) = P(wi|tj)*P(tj|ds)
2.现在我们可以枚举T中topic,得到所有的pj(wi|ds).然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic。最简单的想法是取令pj(wi|ds)最大的tj(注意,这个式子里只有j是变量)
3.然后,如果ds中的第i个单词wi在这里选择了一个与原先不同的topic,就会对theta(d)和phi(t)有影响了,它们的影响又会反过来影响对上面提到的(w|d)的计算。对D中所有的d中的所有w进行一次
p(w|d)的计算并重新选择topic看作一次迭代。这样进行n次循环迭代之后,就会收敛。