
决策树和随机森林
决策树是一种非参数监督学习预测模型。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
1.举例:
举个校园相亲的例子,今天校园的小猫(女)和小狗(男)准备配对,小猫如何才能在众多的优质🐶的心仪的狗呢?于是呢?有一只特乖巧的小猫找到了你,你正在学习机器学习,刚好学习了决策树,准备给这只猫猫挑选优质狗,当然,你不仅仅是直接告诉猫哪些狗是合适你的?你更应该详细的给猫讲解决策树是如何根据它提出的标准选出的符合要求的狗呢?
猫给出如下信息:
年龄<0.5 不心仪;年龄大于>=0.5 6.5<=体重<=8.5;心仪; 年龄>=0.5 体重>8.5 长相好 心仪;其余情况不心仪; 根据上述条件可以构造一颗树:
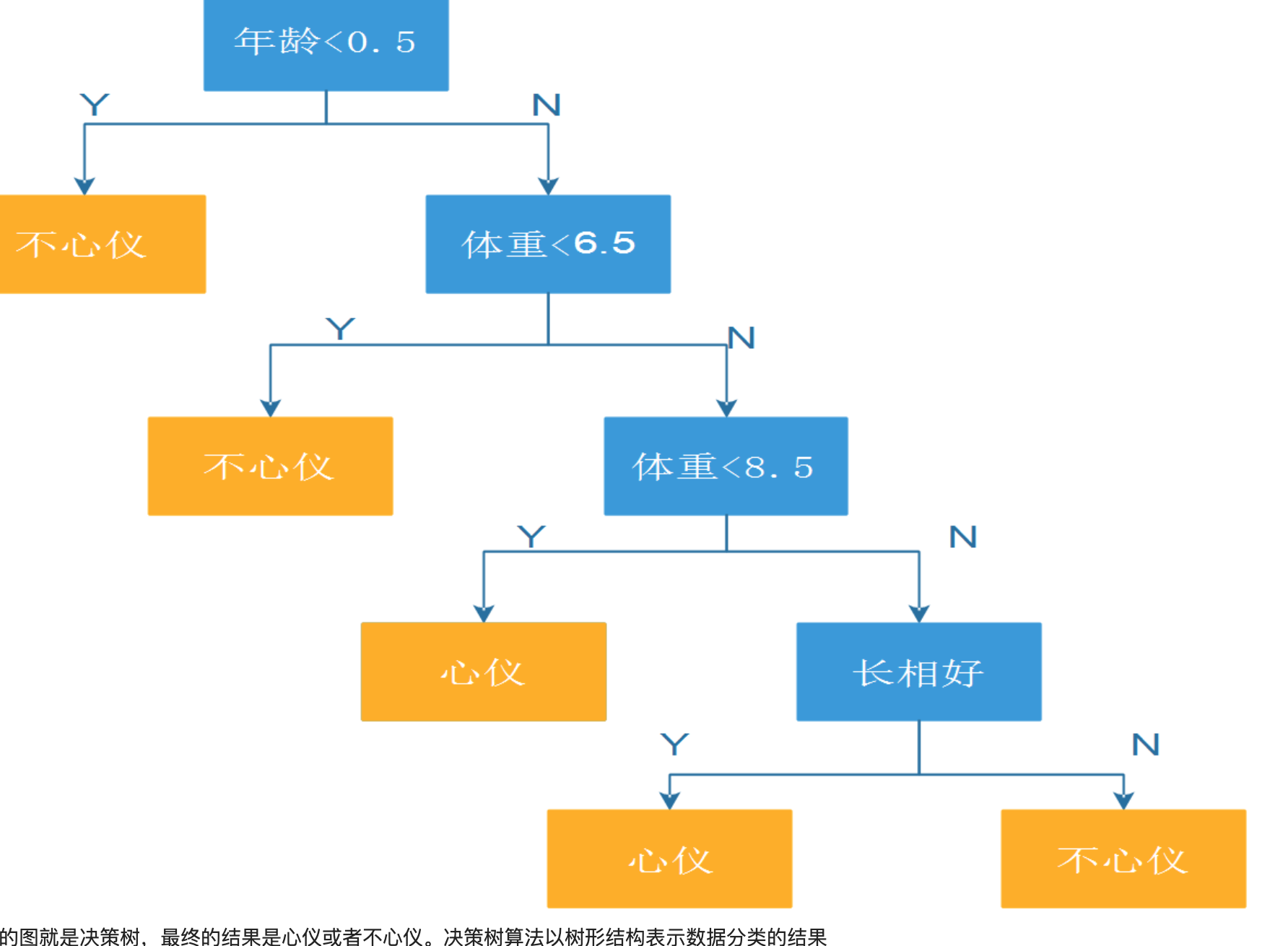
2.概念解释:
根节点:决策树具有数据结构里面的二叉树、树的全部属性
非叶子节点 :(决策点) 代表测试的条件,数据的属性的测试
叶子节点 :分类后获得分类标记
信息熵:熵是一种信息不确定度的度量,H(X)=Px*logPx 也就是说概率越大熵越小。
3.决策树构建构成,计算特征向量每个特征的信息熵,选择熵最下的特征为根节点,
以此递归,直至所有节点确定,对于离散属性,直接计算信息熵,连续属性,就需要划分区间,按区间计算信息熵。
𝐻(𝑥)=−𝑝𝑖(𝑥)𝑙𝑜𝑔𝑝𝑖(𝑥)=−𝑛𝑗𝑆𝑙𝑜𝑔𝑛𝑗𝑆
4.存在的问题,容易过拟合,如果不加以限制,算法最终会为每个特征构建一个叶子节点从而造成过拟合,
解决办法设置树的最大深度(预剪枝),相当于放弃信息熵过大点。
5.随机森林
随机森林很好的弥补了决策树的缺点,它是通过有限次的有放回随机采样,生成n个特征向量序列,然后每个特征序列构造决策树。
然后每个决策树的分类结果通过投票的方式决定哪一个正确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号