

通过python自动获取小说并下载
最近在学习Python,为了学以致用,就用python来写一个小程序,用来获取静态网页中的小说,代码见下:

1 import urllib.request 2 import os 3 4 headers = { 5 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 " 6 "Safari/535.1", 7 } 8 9 10 # 主程序,获取每个章节的名称及链接 11 def main(): 12 print('开始下载') 13 url_list = [] 14 url = 'http://www.eywedu.com/honglou/01/index.htm' 15 res = urllib.request.Request(url, data=None, headers=headers) 16 html = urllib.request.urlopen(res).read().decode('gb18030') 17 lists = html.split('<A HREF="') 18 for i in lists: 19 if '第' in i: 20 s = i.split(r'</A><BR>') # 以/a br作字符分割 21 s1 = ' '.join(s[0].split()) # 取消多余空格 22 url_list.append(s1) 23 handle_url(url_list) 24 25 26 # 处理获取的链接,得到每章名称和准确链接 27 def handle_url(urls): 28 if not os.path.exists('红楼梦'): 29 os.makedirs('红楼梦') 30 net = 'http://www.eywedu.com/honglou/01/' 31 page = 1 32 for i in urls: 33 cut = i.split('" >') 34 get_content(net+cut[0], cut[1]) 35 print('第', page, '章已下完') 36 page = page+1 37 38 39 # 根据每章链接获得内容 40 def get_content(url, name): 41 paragraphs = [] 42 res = urllib.request.Request(url, data=None, headers=headers) 43 html = urllib.request.urlopen(res).read().decode('gb18030') 44 lists = html.split('<BR>') 45 t = 0 46 while t < len(lists): 47 if t == 0: 48 p = lists[t].split(r'2014newad.js"></script></DIV>')[1] 49 p = p.replace('\r\n', '') 50 paragraphs.append(p) 51 elif t == len(lists) - 1: 52 p = lists[t].split(r'<!--/HTMLBUILERPART0-->')[0] 53 p = p.replace('\r\n', '') 54 paragraphs.append(p) 55 else: 56 p = lists[t].replace('\r\n', '') 57 paragraphs.append(p) 58 t = t + 1 59 save_txt(paragraphs, name) 60 61 62 # 将得到的信息保存 63 def save_txt(content, name): 64 f = open('红楼梦\\'+name+'.txt', "a", encoding='utf-8') 65 for i in content: 66 f.write(i) 67 f.close() 68 69 70 if __name__ == '__main__': 71 main()
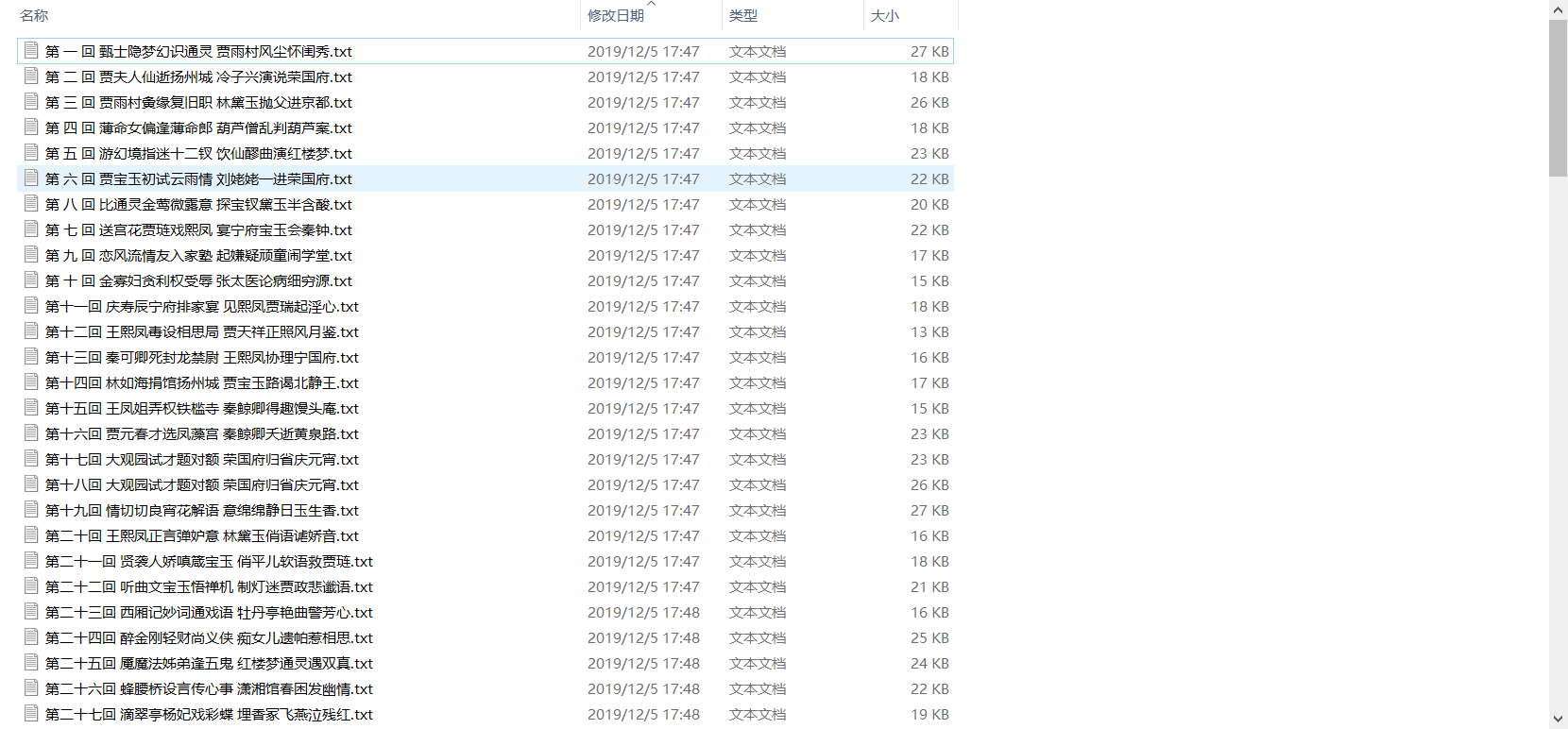
能够成功运行下载:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具