hadoop安装部署
以最低配置1台master,3台slave为例
1、所有机器修改主机名
修改文件 /etc/sysconfig/network
HOSTNAME=Master,Slave1,Slave2,Slave3
2、所有机器创建hadoop账号运行
groupadd -g 1000 hadoop
useradd -u 2000 -g hadoop hadoop
passwd hadoop
3、所有机器关闭selinux
vim /etc/selinux/config
SELINUX=enforcing改为SELINUX=disabled
4、所有机器设置linux最大打开文件数以及最大进程数
配置文件/etc/security/limits.conf增加
soft noproc 65535
hard noproc 65535
soft nofile 65535
hard nofile 65535
配置文件/etc/security/limits.d/90-nproc.conf增加
* soft nproc 65535
5、所有机器Sudo权限赋予
打开文件visudo,最后输入
hadoop ALL=(ALL) NOPASSWD: ALL
6、所有机器关闭防火墙
service iptables stop
chkconfig iptables off
7、所有机器配置Hosts主机IP映射
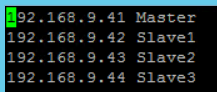
8、所有机器重启电脑
reboot
9、master配置免密钥登录
详情参加本人另一篇文章,配置免密钥登录
10、master配置ntp服务,保证所有机器时间一致
详情参加本人另一篇文章,配置ntp服务
11、所有机器安装jdk
下载jdk-8u151-linux-x64.rpm
rpm -ivh jdk-8u151-linux-x64.rpm
12、所有安装hadoop
解压 tar -xvf hadoop-2.7.2.tar.gz -C /data
提高权限 chown -R hadoop:hadoop hadoop-2.7.2/
13、所有机器修改配置vim /etc/profile
#set JDK
export JAVA_HOME=/usr/java/jdk1.8.0_151
export JRE_HOME=/usr/java/jdk1.8.0_151/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
#set HADOOP
export HADOOP_HOME=/data/hadoop272
export HADOOP_CONF_DIR=/data/hadoop272/etc/hadoop
export YARN_CONF_DIR=/data/hadoop272/etc/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${HADOOP_HOME}/lib:$PATH
配置完重启电脑,或者source /etc/profile使配置生效
进入hadoop配置目录,cd /data/hadoop272/etc/hadoop/
13、修改hadoop-env.sh export JAVA_HOME= /usr/java/jdk1.8.0_151/
14、修改yarn-env.sh export JAVA_HOME= /usr/java/jdk1.8.0_151/
修改集群配置,下面推荐部分配置,更多配置参考官方说明文档,根据实际情况配置调整
15、配置 cor-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop272/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>65536</value>
</property>
<property>
<name>security.job.submission.protocol.acl</name>
<value>jian,akon,administrator,hadoop</value>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
</configuration>
16、配置hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop272/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop272/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
17、配置 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>Slave1:2181,Slave2:2181,Master:2181</value>
</property>
</configuration>
18、配置 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>Master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>mapred.job.shuffle.input.buffer.percent</name>
<value>0.5</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
</configuration>
19、配置slaves文件
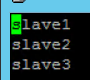
20、通过scp命令复制hadoop文件夹到各子平台
scp -r hadoop272 root@slave1:/data
scp -r hadoop272 root@slave2:/data
scp -r hadoop272 root@slave3:/data
21、修改所有目录权限,赋予hadoop账号权限
chown -R hadoop:hadoop hadoop272
22、格式化
切换到master机器,切换到hadoop账号
hdfs namenode –format
23、启动
./start-all.sh
24、打开页面
浏览器输入master机器IP:端口50070打开管理页面
25、运行历史Mapreduce管理页面
mr-jobhistory-daemon.sh start historyserver
浏览器输入master机器IP:端口19888打开管理页面


 浙公网安备 33010602011771号
浙公网安备 33010602011771号