【论文阅读】DeepWalk Online Learning of Social Representations
DeepWalk: Online Learning of Social Representations
论文信息
- PDF:文献PDF
- 作者:来源于纽约州立大学石溪分校,一个很有名的学校。
辅助资料
笔记
核心思想
- 使用RandomWalk提取节点共现信息
- 类比Word2Vec对提取的节点序列进行图嵌入
- 使用分层Softmax进行加速计算(并行化)
使用RandomWalk提取节点共现信息
生成随机游走序列
对于连通图 \(\mathcal{G=\{V,E\}}\),确定一个起始节点 \(\mathcal{v_0 \in V}\)开始随机游走,每一次随机游走,从当前节点,随机走到该节点的一个邻节点(等概率),数学表示如下:
随机游走生成一系列节点序列 \(\mathcal{W}\),使用RW()表示随机游走生成器,则 \(\mathcal{W}=\mathrm{RW}\left(\mathcal{G}, v^{(0)}, T\right)\),其中 \(\mathcal{W}=\left(v^{(0)}, \ldots, v^{(T-1)}\right)\) 表示随机游走序列,\(\mathcal{v_0 \in V}\) 表示起始节点,\(T\) 表示随机游走的长度。
为了捕获整个图的信息,以图中每个节点作为起始节点进行随机游走,每个起始节点生成 \(\gamma\) 个随机游走序列,总共获取 \(|\mathcal{V}|\cdot \gamma\) 条随机游走序列。
生成共现列表 \(\mathcal{I}\)
注:这一部分是马耀老师《图深度学习》上的内容,原文献并没有直接写这一部分,而是将其放在了Skip-Gram算法中。
共现信息
共现信息一开始用于语言模型,字面上看,就是“一起出现”的意思,如果两个单词同时出现在一个句子中,就能构成共现。
在实际任务(比如完形填空)中,我们把句子中的一个词作为“中心词”,记作 \(v_{cen}\),中心词前后 \(w\) 个词内的范围叫做上下文,中心词和上下文的每个词(记作 \(v_{con}\))形成一个一个共现,使用二元组的形式表示 \((v_{con}, v_{cen})\)。
节点共现的提取(生成共现列表)
我们之前已经生成了 \(|\mathcal{V}|\cdot \gamma\) 条随机游走序列,每个随机游走序列可以看成一个句子,对所有序列中每一个节点 \(v^{(i)}\),将其作为中心节点,其前后 \(w\) 个节点作为上下文节点,将二元组 \((v^{(i-j)},v^{(i)})\) 和 \((v^{(i+-j)},v^{(i)})\) 加入共现列表 \(\mathcal{I}\)。
使用Skip-Gram生成节点的嵌入表示
幂律分布:语言模型和随机游走之间的联系
词库与节点集:在语言模型中,所有需要研究的词构成的集合叫做词库,在图深度学习中,图中的所有节点构成的节点集合和词库类似。
词的概率分布:若干词构成一个句子,如果我们有大量的句子,我们可以认为词出现在句子中的概率服从某种分布,经过统计,我们发现词出现在句子中的概率服从幂律分布 (Power Law)。
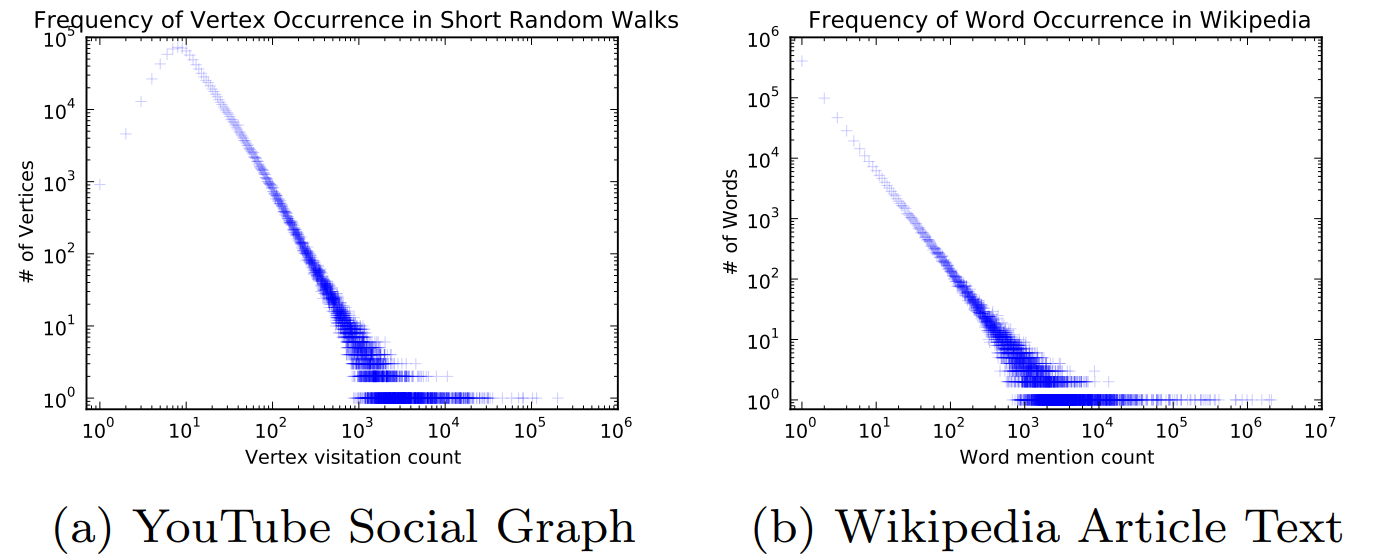
节点的概率分布:如上图所示,对于Youtube网络中节点在随机游走出现的次数进行统计,发现其概率分布和词的概率分布极其相似,所以我们可以使用语言模型来处理图的问题。
独立同分布假设
Skip-Gram模型假设上下文词的分布和其到中心词的距离无关,也就是说,所有上下文词都是独立同分布的,中心词的上下文可以看成独立重复试验,由于随机游走算法是随机的,上下文节点的位置没有实际的含义,只体现了其与中心词之间的关联,所以Skip-Gram非常适合图的问题。由于每个位置的上下文节点都是独立同分布的,所以我们只要计算一个分布就能代表所有上下文的概率分布。
Skip-Gram模型
Skip-Gram模型使用中心词预测上下文词,上面说过了,所有上下文词独立同分布,所以我们的输出是一个概率分布,也就是一个上下文词是词库中某一个词的概率,显然,这是一个多分类问题,其输入是中心词,输出是一个概率分布,如下图所示:
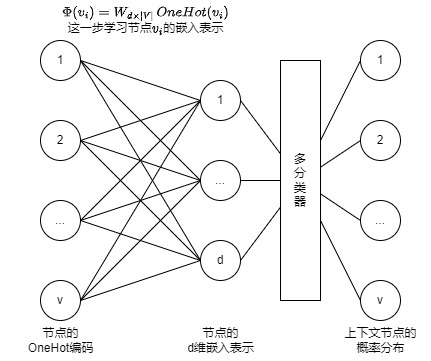
Skip-Gram算法如下:

Skip-Gram模型优化目标如下:
分层Softmax
分层Softmax其实就是二分法,上面的Skip-Gram算法的最后一部分是多分类,一般多分类使用Softmax和交叉熵损失,需要计算所有类别的规律并求和,在类别数量巨大的时候计算量很大,在图表示中,一个节点代表一个类,计算量会非常大,让模型效率很低。
事实上,我们的优化目标不需要我们计算所有类别的概率,所以文献中提出使用分层Softmax来加速计算。
分层Softmax其实很好理解,要判断一个样本的类别,我们可以一一计算每个类的概率,也可以使用二分法:我们把所有类分为两堆,分别计算样本属于第一堆和第二堆的概率,然后继续二分,这样,我们就能O(n)的复杂度降到O(log n),这样的二分能够构成一个树,文献中的分层Softmax图示如下:
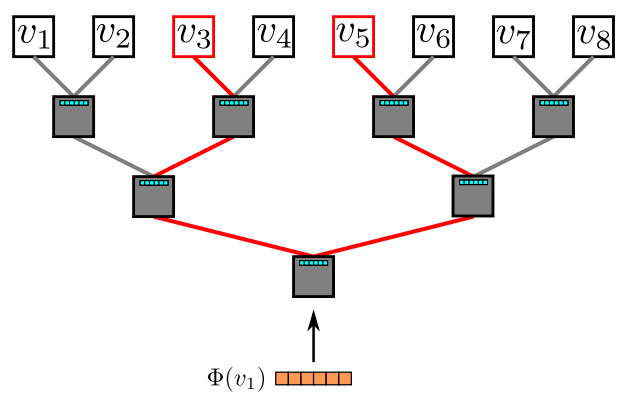
由于进行了二分,所以每一层都可以看成是一个二分类,对每个二分类参数进行学习即可。
算法变体
Streaming
Streaming其实就是不知道整个图的结构,我们只知道一部分的图或者干脆只有游走序列,但是由于不知道整个图,所以除非我们事先知道总共有多少节点或者知道节点数量的上界,我们计算分类(Softmax和分层Softmax)会比较困难。
Non-random walks
非随机游走,其实就是人工设计的游走规则,或者,更多的是实际问题产生的游走序列,比如交通图中的游走序列可能是现实中人们出行的路径。
疑问
- DeepWalk似乎只是提取了图结构(也就是节点之间的关系),而没有对节点本身的特征做处理,如果原来的节点就有特征,如何与DeepWalk结合?
知识树
- DeepWalk
- 节点共现信息
- 图嵌入
- 图信号处理
- 图
- 图信号处理
- 词共现
- 图嵌入
- RandomWalk生成随机游走序列
- 随机游走序列中包含的节点共现信息
- 使用Skip-Gram生成节点的嵌入表示
- 分层Softmax加速计算
- 节点共现信息
展示树
- 为什么需要图嵌入?(类比词嵌入,图结构让节点间不是相互独立的)
- DeepWalk的输入输出(也就是图嵌入的输入输出,图结构输入,嵌入表示输出)
- 什么是节点共现?(类比词共现)
- 如何使用RandomWalk提取节点共现信息?
- 生成随机游走序列
- 生成共现列表
- Skip-Gram算法
- 分层Softmax加速计算
- 算法变体
- Streaming
- 非随机游走
