
kernel——内存管理
0. 背景知识
0.1. 硬件

sram : 硬件复杂,成本高,CPU通过A0-A18个地址线一次输入要访问的地址,就能获得数据,所以CPU能直接访问
ddr sdram: 硬件简单,成本低,但CPU需要通过a0-a10地址线多次输入地址,先输入行地址,再输入列地址,才获得数据,由于有时序问题,所以用sdram控制器实现,cpu不能直接访问。
0.2. 内存管理的目的

不仅是回收未使用内存,
是减少内存碎片,否则分配大片内存时会失败。
1. 对物理内存的管理
1.1 node zone page
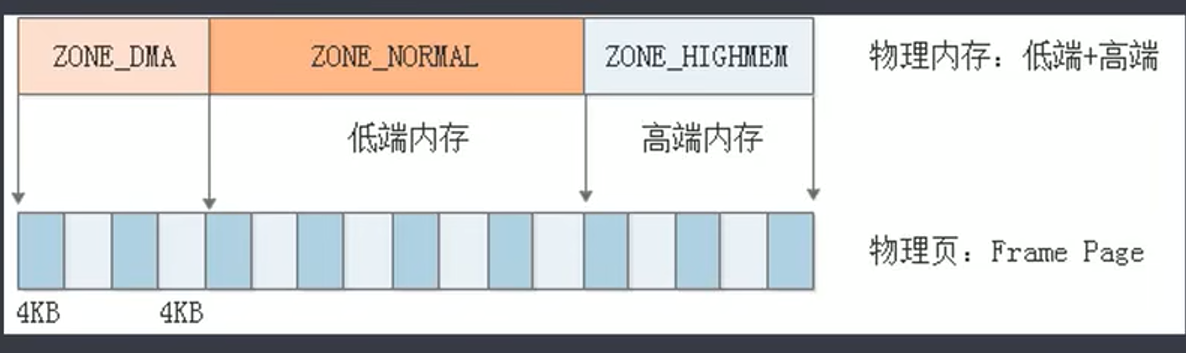
- struct node,内存节点,如服务器有多个CPU,每个CPU有自己的内存,将每个内存资源抽象为 struct node,如此CPU既方便访问自己的内存,也可以通过总线访问其他cpu的内存。
- struct zone,分区,根据使用目的进行分区,如 ZONE_DMA 由于DMA需要连续内存,单独分区,不参与内存分配,避免内存碎片。
- struct page,分页,按 frame page 大小对将内存分为多个内存块,比如4KB。
1.2 struct page
查看kernel代码对struct page的描述,会发现struct page使用了大量的union,因为 page 分很多类。且使用union有个好处,省内存。
每个struct page对应一块 frame page,可以想象有很多 struct page,他们构成一个数组,使用 mem_map 指向这个数组。将数组的索引值成为 pfn(page frame number)。
pfn 和 page 之间可以互相转换
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
ARCH_PFN_OFFSET)
物理地址和pfn的管理,PAGE_SHIFT为12,由于frame page大小为 4KB,即1012,将物理地址除以1012得到pfn
pfn = paddr >> PAGE_SHIFT
1.3 物理内存的管理结构
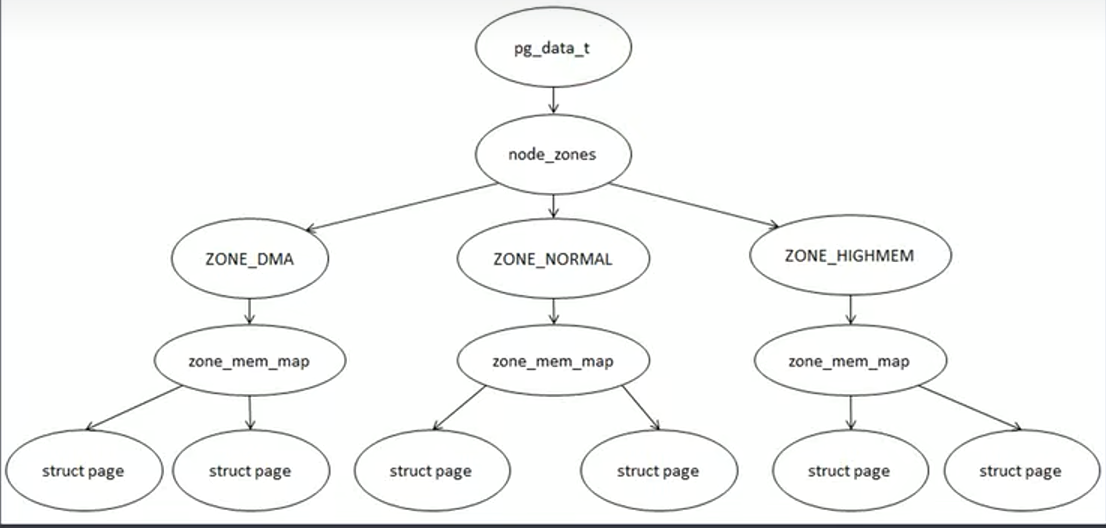
pg_data_t : 表示内存节点
node_zone : 按使用目的对内存进行分区
zone_mem_map : 存放struct page数组的首地址
struct page : 对每块 frame page的描述结构体
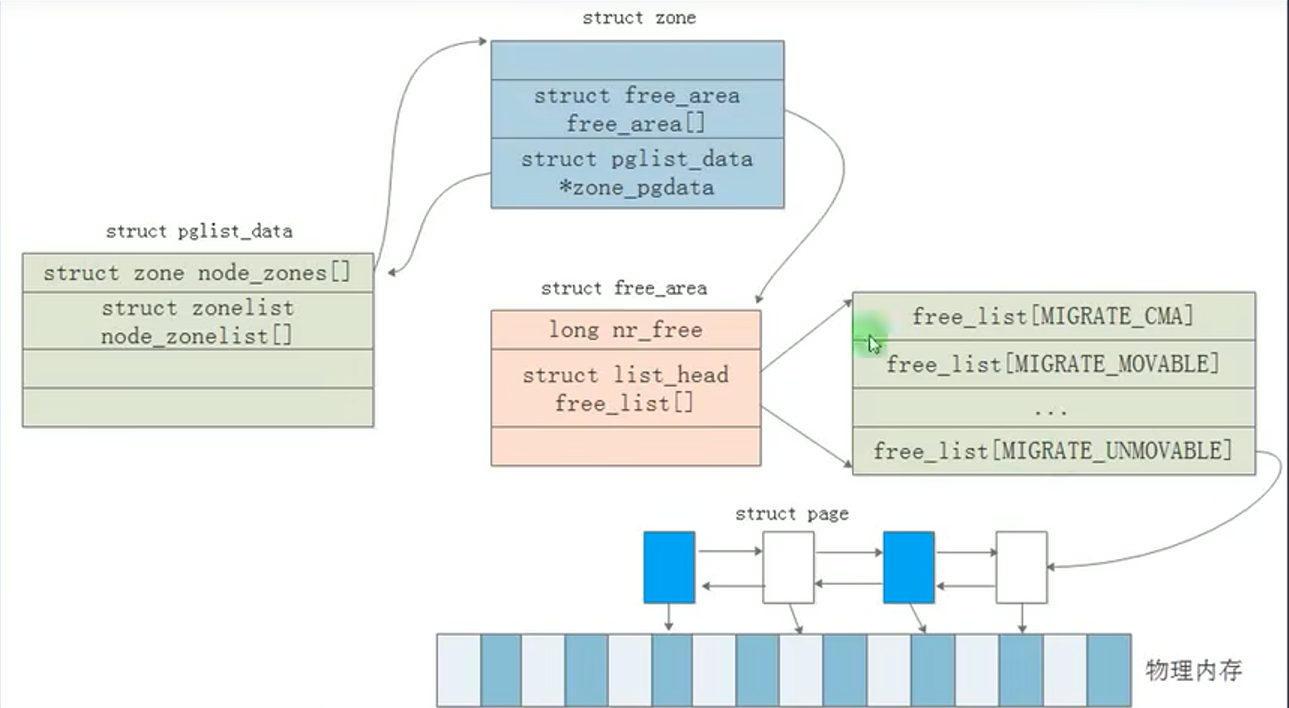
有了上述对象,kernel可以实现如上图,对内存进行简单的管理,先确定node,再确定zone,再找到struct page,找到对应的frame page
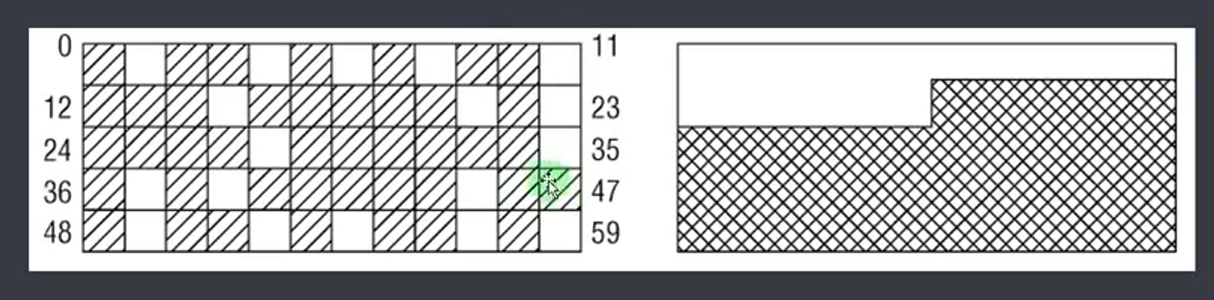
2. 伙伴系统(buddy system)
前面的假设太过粗糙,kernel对于内存管理,可能使用伙伴系统。

- 物理内存依旧按照frame page划分成固定大小的页,每个frame page都有一个page和其对应
- 为了减少内存碎片,将page按不同大小合并
- 最小的是 2^0 也就是一个page大小,然后是 2^1 * page 大小,最后是 2^(MAX_ORDER-1)*page大小
- 分配:分配内存时会尽可能使用小内存块,比如分配4KB内存,但发现2^2对应的链表依旧分配完了,就从2^3链表取一块进行拆分,加入2^2完成分配。
- 释放:用户释放内存后,根据内存大小加入对应的链表,然后尽可能进行合并,系统会检查是否有相邻物理地址内存块,有则进行合并,并移到上级链表。
具体实现
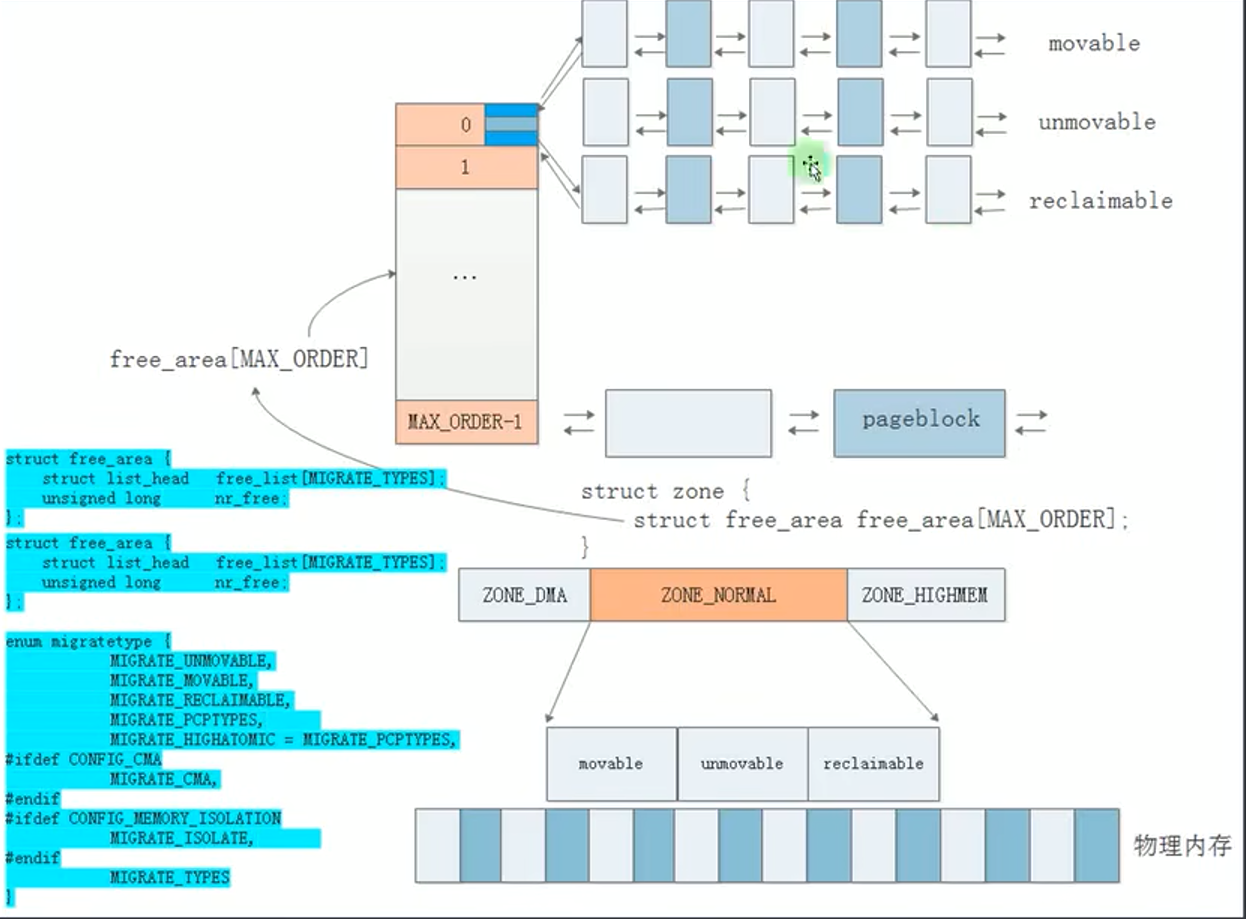
- 每个zone都维护一个buddy,具体是 zone.free_area[]
- 每个数组元素有一个元素为链表的数组,分为三种类型的链表 movable 可移动(如应用程序动态分配的内存),unmovable 不可移动(如内核的物理内存),reclaimable 可回收(如文件的页缓存)。比如.text对应的内存就应该从 unmovable中分配。
# 查看当前buddy system情况
cat /proc/buddyinfo
cat /proc/pagetypeinfo
相关结构体
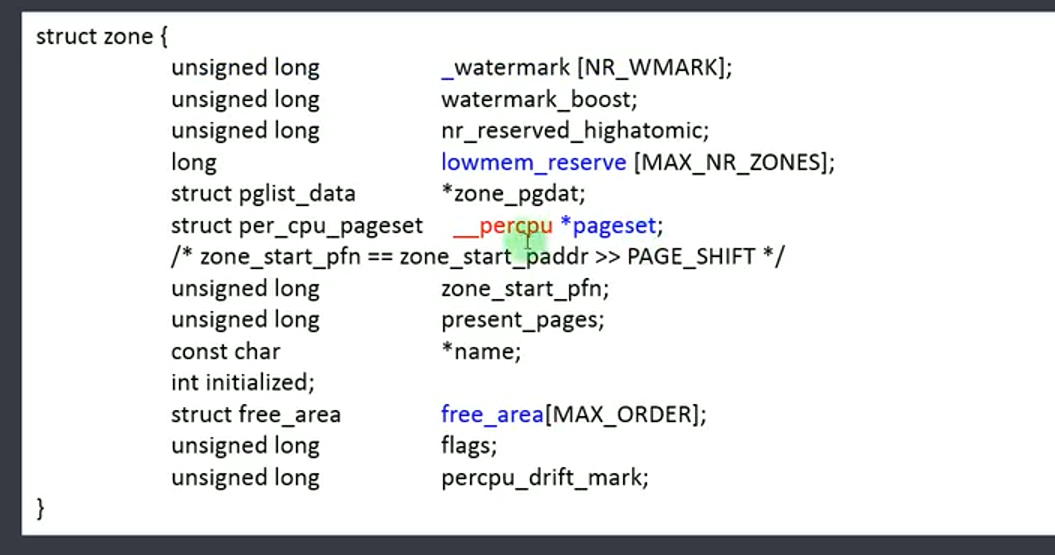
struct page {
unsigned long private; // page的大小,2^0, 2^1 之类,
// 由于buddy中一块内存可能又多个page合并构成,
// 返回给用户首个page,
// 使用private告诉用户此块内存的大小
atomic_t _mapcount; // 是否被虚拟地址映射
// 可用于判断此page是否被分配了
atomic_t _refcount;
};
迁移类型
页面迁移:包括复制物理页,改变虚拟地址映射。
由于buddy system中 page有可移动类型,所以即使用户一直不释放内存,buddy也可以迁移可移动内存,以获得大内存。
对于不可移动的page,会从特定的位置分配,避开页面迁移
什么时候会触发页面迁移?
- 当申请大内存失败
- 当kcompacted线程发现内存碎片超过阈值
per-cpu 页缓存
对于一个物理内存条,使用node描述,node分为多个zone分别管理,一个zone有三个变量存放page
- lowmem_reserve
- pageset : 实现 per-cpu 页缓存
- free_area : 使用 buddy system管理
具体看看 pageset,可见pageset管理的同等大小page组成的链表,实际上pageset管理大小为1 page的页。为什么要将这些页单独管理。

首先要理解per-cpu
多处理器系统中,不同的处理器核心共享同一组内存和总线。每个处理器核心都有自己的缓存,缓存中存放着处理器核心最近访问过的内存数据。当多个处理器核心同时访问同一组内存时,由于缓存一致性问题,可能会导致不同的处理器核心之间的缓存数据不一致,从而导致程序运行出现异常或错误结果。
缓存一致性问题的主要原因是缓存的存在。处理器核心会将经常使用的数据存放到缓存中,以提高访问速度。但当多个处理器核心同时访问同一组内存时,它们各自的缓存中可能存放着不同的数据,如果这些数据之间没有进行同步和协调,就可能导致数据不一致,进而影响系统的正确性和性能。
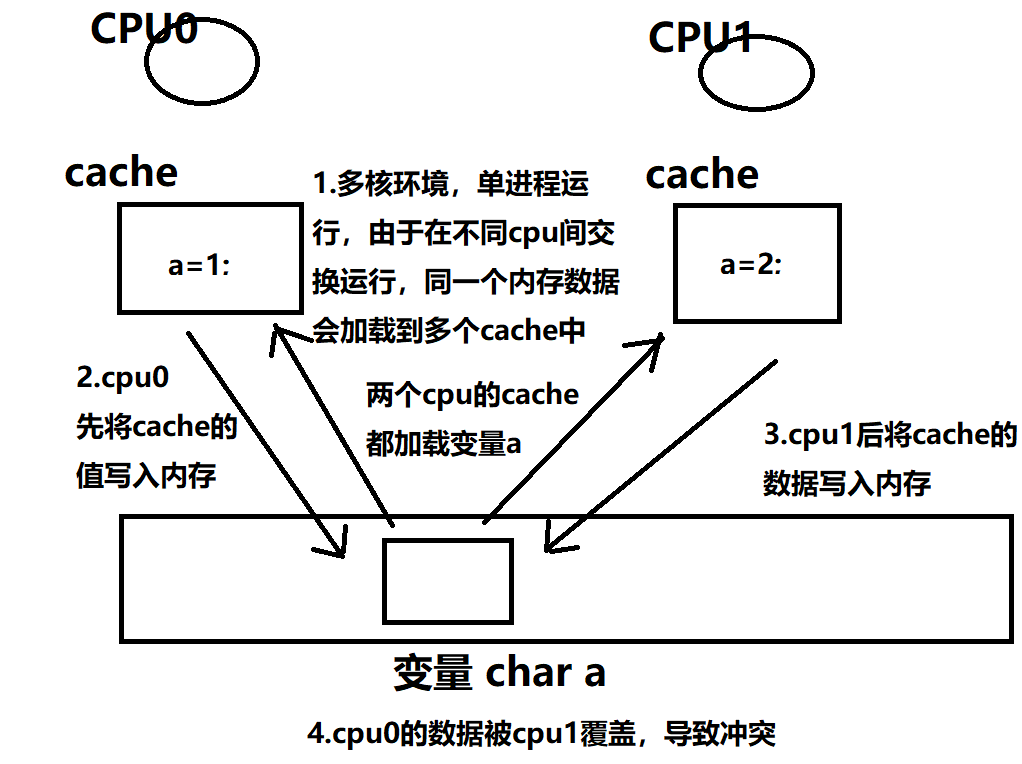
为了解决这个问题,可以使用锁,但是会降低性能。
使用per-cpu修饰变量后,该变量对每个cpu有独立的副本。
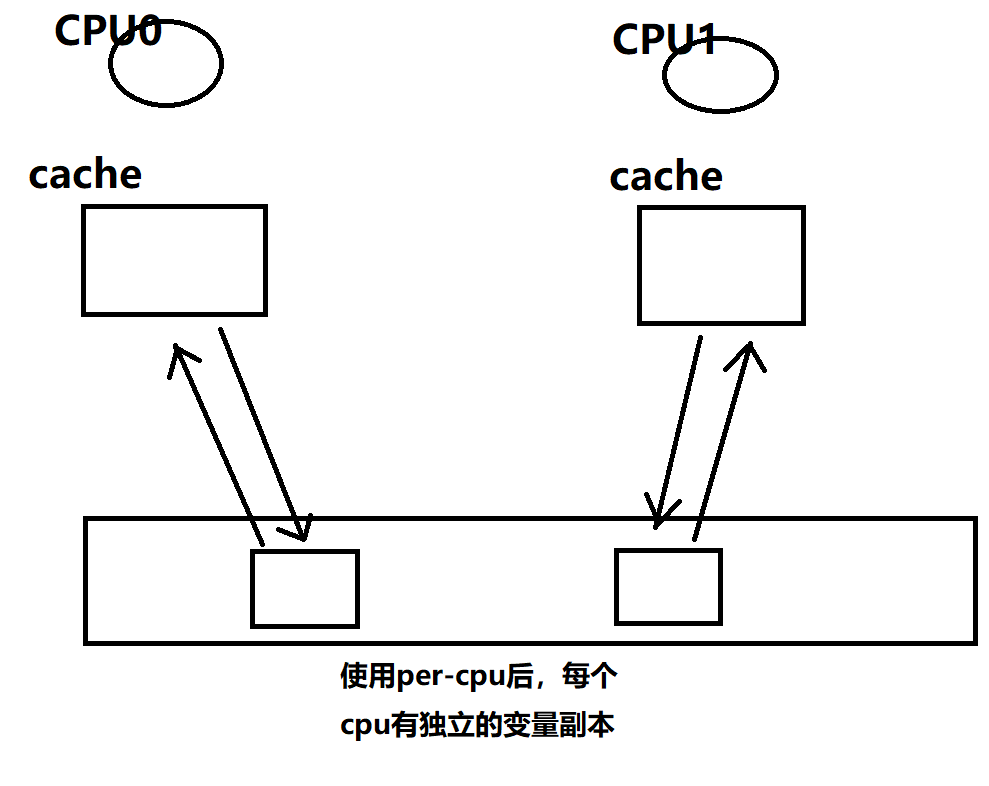
所以使用pageset不需要锁,效率高,且pageset管理的内存为1页大小的page,很常用,所以当分配内存时首先考虑从 pageset分配,不成功再从 free_area 分配。可以大大提高效率。
伙伴系统的接口
include/linux/gfp.h
struct page *alloc_pages(gfp_t gfp, unsigned int order);
用于申请一块2^order的连续物理内存块
内核内存环境良好,直接进行快速分配
当前内存环境恶劣时,进入慢分配流程,慢分配时可能会进行页内存的迁移,合并等以获得需求大小的struct page.
CMA
伙伴系统有个缺点,即最大分配的struct page有限,如 MAX_ORDER 为 11,则最大为 2^11 = 4MB.
如果希望申请大于4MB的内存,需要在初始化时保留一大块内存,等待驱动使用。但当驱动没有使用时,这大块内存被闲置。
为了解决上面问题,内核实现了CMA机制,当内存空闲时,空闲的内存加入伙伴系统,可用于小内存的分配。当驱动等使用CMA分配大块内存时,保证能分配大块连续内存(若已被分配用于小内存,则会进行内存迁移)。
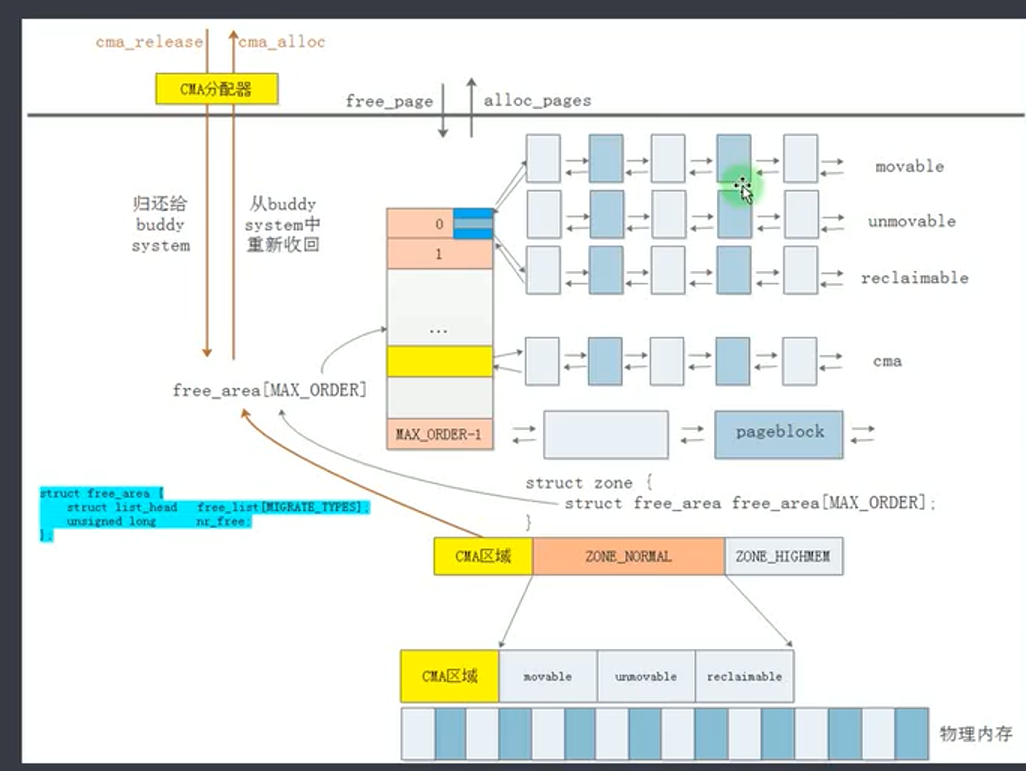
在内存初始化时,专门划分一大块区域用作CMA。
空闲时CMA调用cma_release将内存加入伙伴系统的特定链表,每个节点对应的内存大小为 2^MAX_ORDER。
伙伴系统可以将CMA链表的内存进行拆分加入小页链表,以给用户分配。但是有个限制,即用户分配的内存必须是 movable,因为当CMA需要大块内存分配时,可能需要内存迁移。
当CMA分配大块内存时,调用 cma_alloc从伙伴系统中回收内存。
在设备树或内存配置时指定保留多大空间做cma
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
/* Chipselect 3 is physically at 0x4c000000 */
vram: vram@4c000000 {
/* 8 MB of designated video RAM */
compatible = "shared-dma-pool";
reg = <0x4c000000 0x00800000>;
no-map;
};
};
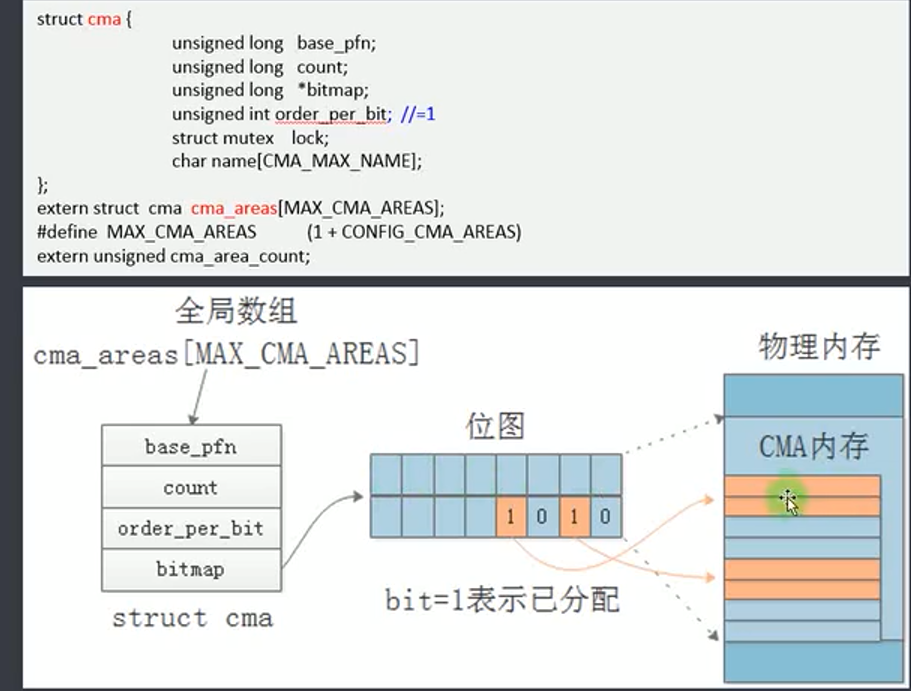
cma_area指向整个cma空间。
base_pfn可以找到对应物理地址
count 大小
bitmap 和 order_per_bit ,若order_per_bit为0,则占用20即一个bit位,若为2,则占用22即占用4个bit。每个bit位都对应一个页块(如4MB)
伙伴系统的初始化
memblock的初始化
物理内存有些会被保留,不参与伙伴系统内存分配,比如:内核镜像(.init段除外),dtb,u-boot(reboot时会被调用),页表,GPU,camera,音视频编解码,dtb设置为reserved的区域(CMA除外)
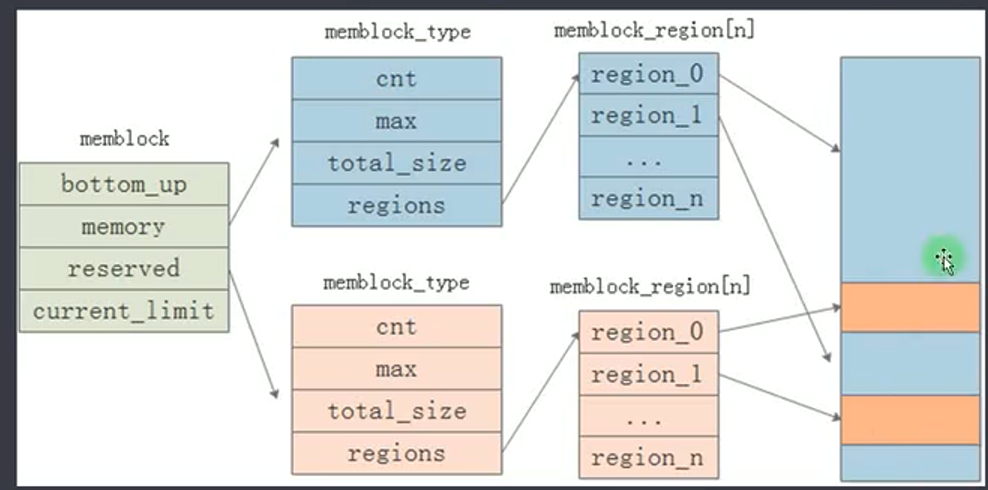
要初始化伙伴系统,首先需要区分哪些内存可用于伙伴系统,哪些内存被保留。
memblock是全局变量,其memory属性记录可用于伙伴系统的内存块,reserved属性记录被保留的内存块。
通过 memblock_add,memblock_remove给 memblock.memory添加删除内存块。
通过 memblock_reserve,memblock_free给 memblock.reserved添加删除保留块
int __init_memblock memblock_add(phys_addr_t base, phys_addr_t size)
int __init_memblock memblock_remove(phys_addr_t base, phys_addr_t size)
int __init_memblock memblock_reserve(phys_addr_t base, phys_addr_t size)
void __init_memblock memblock_free(void *ptr, size_t size)
在用户空间可以参考这些属性
/sys/kernel/debug/memblock/memory
/sys/kernel/debug/memblock/reserved
setup_arch
setup_machine_fdt
early_init_dt_scan
early_init_dt_scan_memory
遍历设备树memory节点,从reg属性获得base,size
early_init_dt_add_memory_arch(base, size)
memblock_add_node(base, size, 0, MEMBLOCK_NONE)
memblock_add_range(&memblock.memory, base, size, nid, flags) // 将可分配的内存信息加入 memblock.memory
arm_memblock_init
early_init_fdt_scan_reserved_mem // 将保留内存信息加入 memblock.reserved
相关设备树
memory@80000000 {
device_type = "memory";
reg = <0 0x80000000 0 0x40000000>;
};
reserved-memory {
#address-cells = <2>;
#size-cells = <2>;
ranges;
/* Chipselect 2 is physically at 0x18000000 */
vram: vram@18000000 {
/* 8 MB of designated video RAM */
compatible = "shared-dma-pool";
reg = <0 0x18000000 0 0x00800000>;
no-map;
};
};
最后,memblock_memory_init_regions 和 memblock_reserved_init_regions 分别保留可分配和保留信息

memblock释放内存给伙伴系统
从memblock.memory获得可用的内存信息,使用 free_page 添加到伙伴系统
mm_init
mem_init
memblock_free_all // 将memblock.memory 记录的内存释放到伙伴系统
free_low_memory_core_early
for_each_free_mem_range(i, NUMA_NO_NODE, MEMBLOCK_NONE, &start, &end,
NULL) // memblock.memory 数组获得每个节点的 start, end
__free_memory_core(start, end);
__free_pages_memory(start_pfn, end_pfn); // 将地址转换位页号
memblock_free_pages(pfn_to_page(start), start, order); // 由页号得到 page
__free_pages_core(page, order);
__free_pages_ok(page, order, FPI_TO_TAIL | FPI_SKIP_KASAN_POISON);
migratetype = get_pfnblock_migratetype(page, pfn); // 获得可移动属性
__free_one_page(page, pfn, zone, order, migratetype, fpi_flags); //加入伙伴系统
CMA释放给伙伴系统
在dts中,如果reserved的内存节点有类似属性,则不会被释放给伙伴系统
removed-dma-pool "linux,dma-default";
no-map
如果有如下属性,则会被释放给伙伴系统
shared-cma-pool "linux,cma-default";
reuse
do_initcalls
for (i = 0; i < cma_area_count; i++) //遍历CMA数组,将每个CMA区域都释放给伙伴系统
cma_activate_area(&cma_areas[i]);
cma->bitmap = bitmap_zalloc(cma_bitmap_maxno(cma), GFP_KERNEL); // 准备bitmap表用于记录有哪些内存释放给了伙伴系统,方便CMA需要时会让伙伴系统归还
for (pfn = base_pfn; pfn < base_pfn + cma->count;
pfn += pageblock_nr_pages)
init_cma_reserved_pageblock(pfn_to_page(pfn)); // 以pageblock为单位释放内存
set_pageblock_migratetype(page, MIGRATE_CMA); // 将此页标记为CMA类型
__free_pages(page, pageblock_order); // 释放page,将page添加到pageblock_order的链表上
将.init段释放给伙伴系统
rest_init
kernel_init
free_initmem
free_initmem_default
extern char __init_begin[], __init_end[];
free_reserved_area(&__init_begin, &__init_end,
poison, "unused kernel image (initmem)");
start = (void *)PAGE_ALIGN((unsigned long)start);
for (pos = start; pos < end; pos += PAGE_SIZE, pages++) { // 以page为单位释放到伙伴系统
struct page *page = virt_to_page(pos);
free_reserved_page(page);
__free_page(page);
}
pr_info("Freeing %s memory: %ldK\n", s, K(pages));
slab
伙伴系统有个缺点:最小分配内存大小为一个页。
为了适合小内存的申请释放,实现了 slab缓存。
slab是从伙伴系统申请一页(一个page或多个page大小),将一页内存分成相同大小的内存块,如32B的slab每个内存块为32B,64Bslab每个内存块大小为64B。
当用户申请小内存时,按照申请的大小到对应的slab缓存中获得内存块,
当用户释放内存时,按照内存大小释放到对应的slab。
比如task_struct是常用的类型,那么可以对task_struct构造一个slab,slab块的大小为64B。
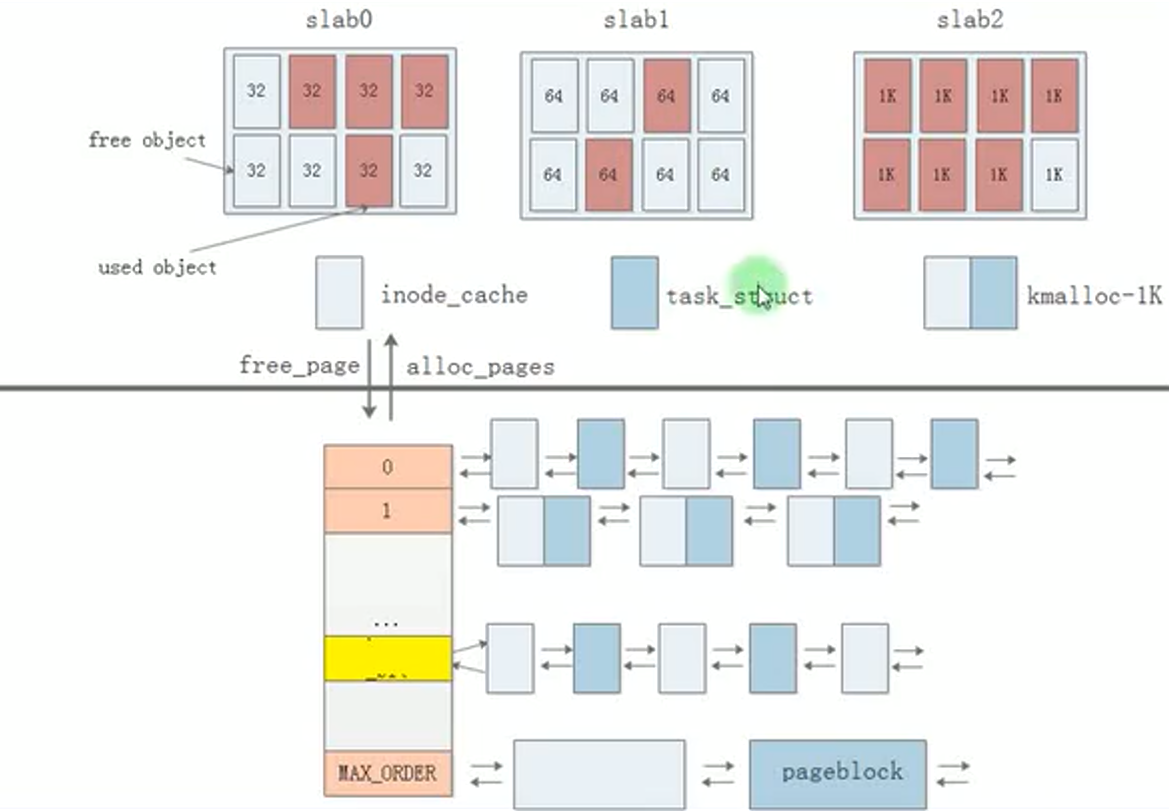
slab:老版本实现
slob:轻量级slab
slub:对slab的重新实现
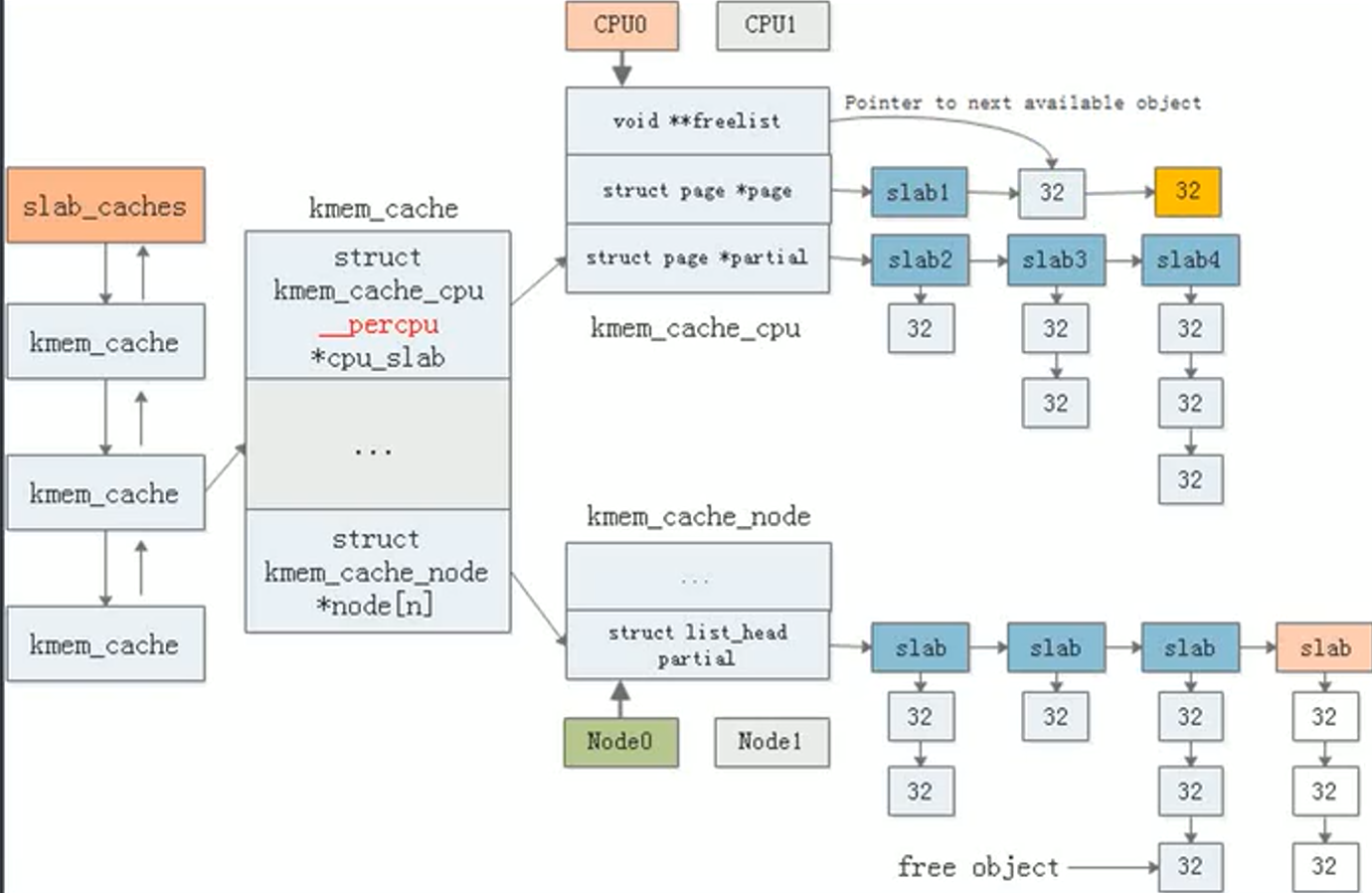
slab的实现原理
核心三个类型:
kmem_cache, kmem_cache_node, kmem_cache_cpu
kmem_cache,相同大小的slab由同个kmem_cache管理
kmem_cache_node,这时一个元素为指针的数组,除了服务器外通常只有一个元素
kmem_cache_cpu,使用__percpu修饰,每个cpu有单独的一份拷贝。
当用户申请slab时,根据申请大小到对应的kmem_cache,如果希望多cpu访问则从 kmem_cache_node分配,否则从kmem_cache_cpu分配。
空闲的slab由free_list管理,分配时,将首个节点返回给用户,并将free_list指向下一个节点即可。一个slab的申请完了,就移动free_list到下一个slab,如果所有slab都用完了,就从伙伴系统分配一个page构造成 slab。
slab的编程接口
创建和销毁 kmem_cache
kmem_cache_create
kmem_cache_destory
从 kmem_cache 分配一个obj
kmem_cache_alloc
释放 obj到 kmem_cache
kmem_cache_free
kmalloc
kmalloc是基于伙伴系统和slab实现的,当申请的内存大则从伙伴系统,小则走slab。
2. 虚拟内存
虚拟地址和MMU
当cpu开启MMU后,虚拟地址被转换成物理地址,发给SDRAM
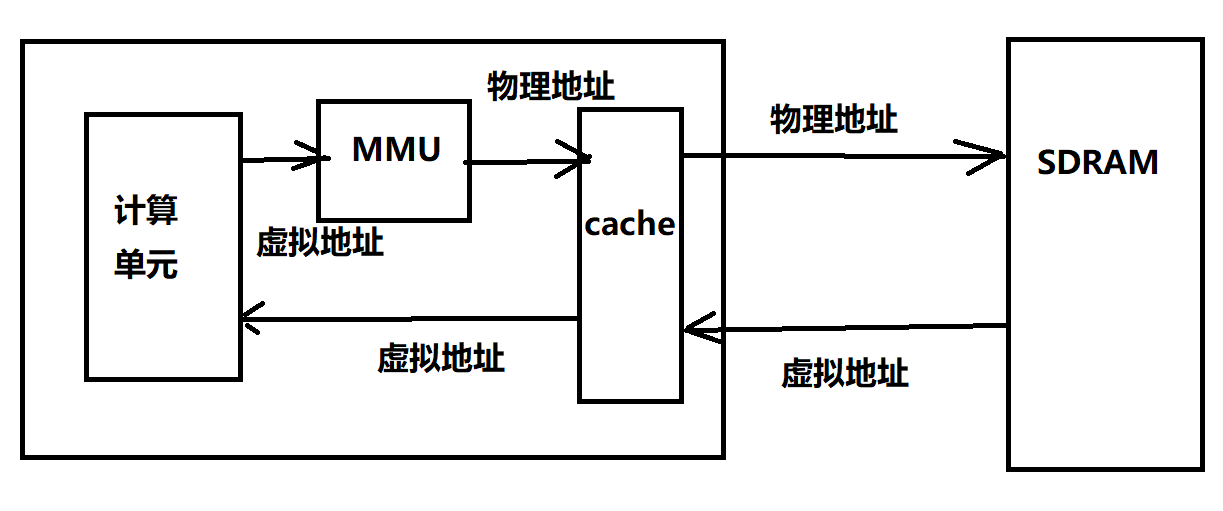
为什么一定要虚拟地址:
因为多进程环境太复杂,连接器无法在链接节点知道程序的加载地址,所以假定程序都从0地址开始。那么不同进程的地址就重叠了,所以需要运行将链接的地址映射到不同的物理地址。
MMU的工作原理
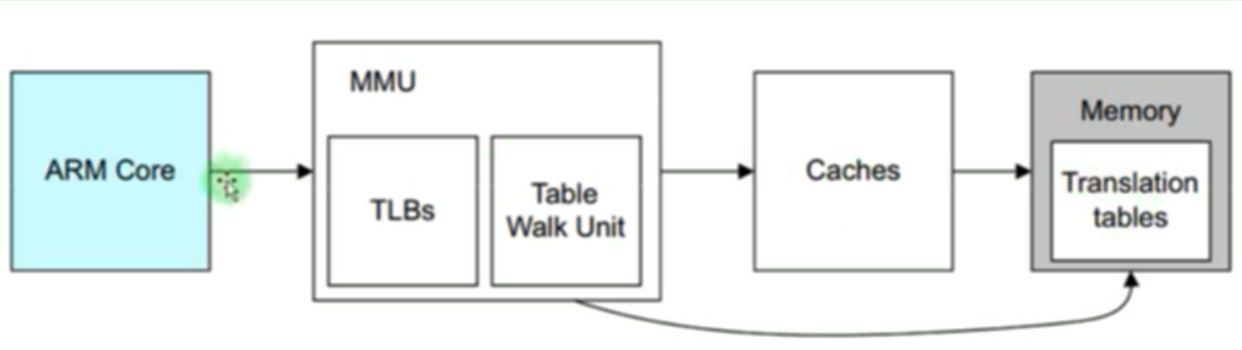
MMU的映射是以页为单位
页表:虚拟地址和物理地址的映射关系表,保存在内存中。
Table Walk Unit:读取页表的硬件,当转换虚拟地址时,他会读取对应的页表
TLBs:页表缓存,由于读取内存太非时间,当转换一个地址时会将附件地址的页表也加载在MMU的TLBs
一级页表
一级页表实际不存在,只是为了理解页表机制。
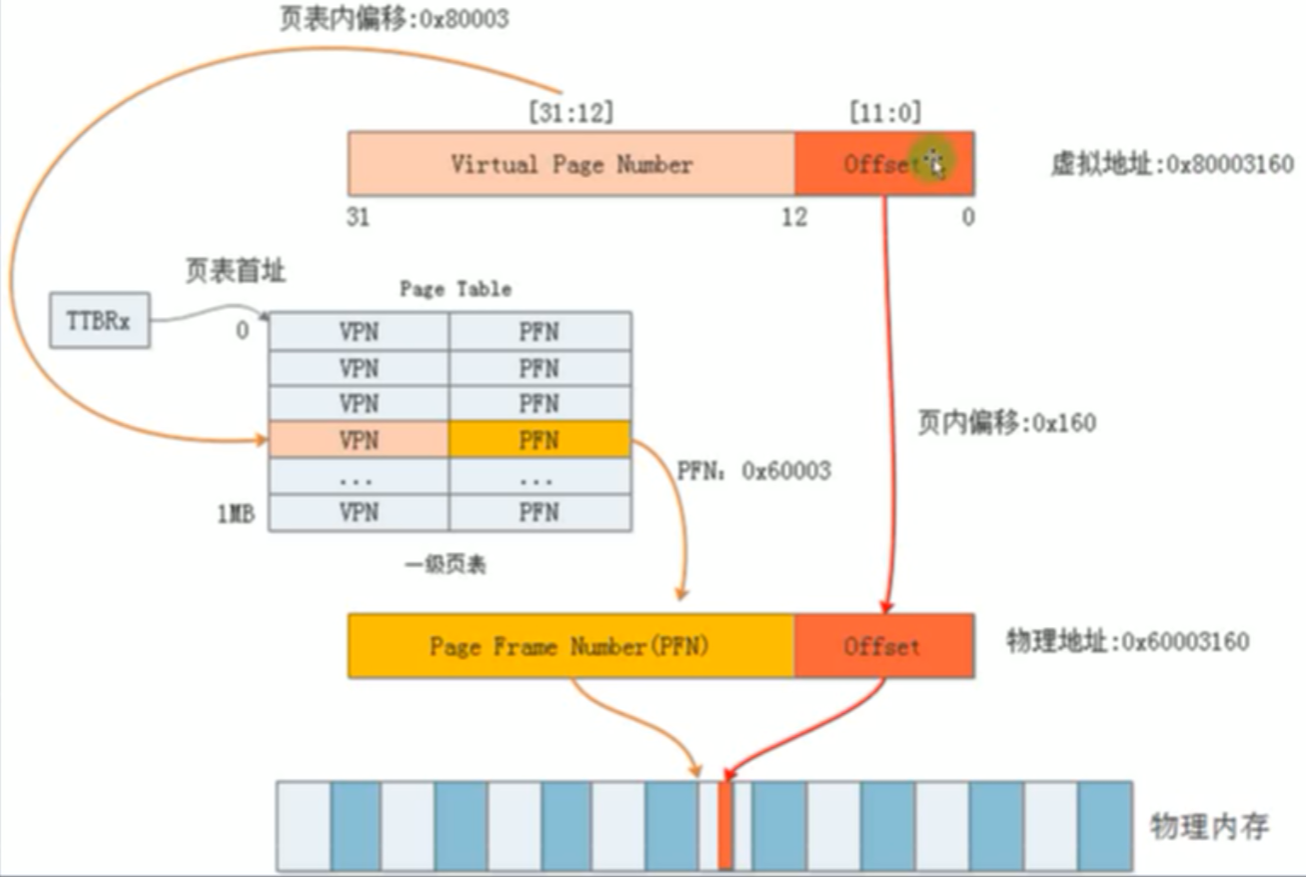
虚拟地址分为 [31:12] 20 位 虚拟页表号,所以能表示2^20 = 1M个页表,每个页表对应4KB大小的物理页,所以能映射4GB的物理地址。
虚拟地址的第二段位 [11:0] 12位的页内偏移。
首先根据 虚拟地址第一段 虚拟页表号作为索引,寄存器TIBRx存储了页表的首地址,有索引和首地址就得到物理页号,从而找到了物理页,再加上虚拟地址第二段页内偏移做物理页页内偏移。就得到物理地址。
一级页表有个致命问题:页表太大,如上为 1M个页表项,一个页表项如果为4B,则为4MB,每个进程都有自己的页表,1K个进程则需要4GB的物理内存存储页表。
二级页表
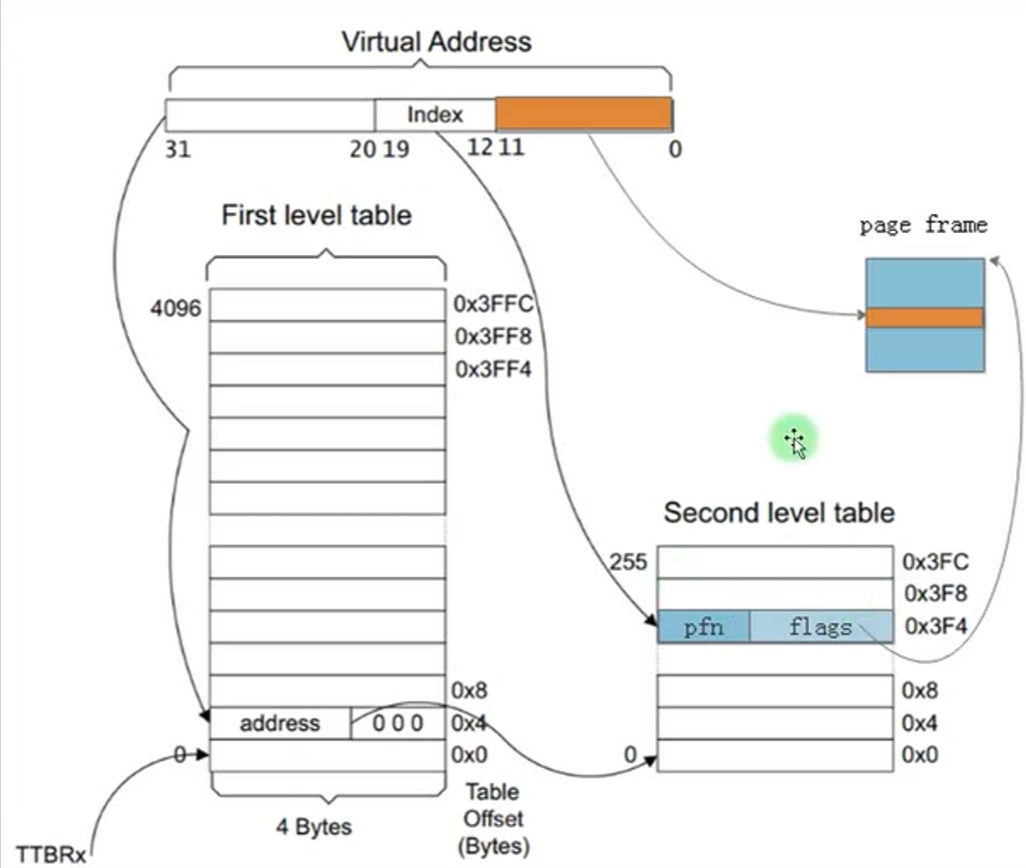
二级页表的虚拟地址分为三段:
一级页表号[20-31]: 12位,4K个一级页表项
二级页表号[12-19]: 8位,256个二级页表项
页内偏移[0-12]:12位,最大偏移4K,也就是一个物理页的大小。
4K * 256 * 4K = 4GB ,所以二级页表也能表示4GB虚拟地址,映射4GB物理地址。
由于二级页表只有一级表需要预先分配,二级表用时才分配,所以一个进程的页表占用内存为 16KB 多点。
而且二级页表中二级表可以分散到物理内存,所以不需要占用连续的物理内存。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?