Kafka的生产者
数据生产流程
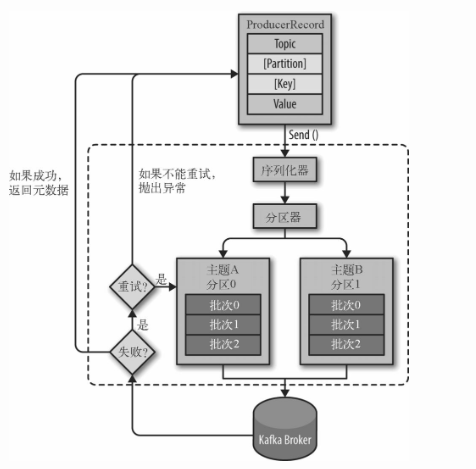
1、创建ProducerRecord对象,该对象出来包括要发送的数据,还必须指定topic,也可以指定key,value和分区,发送ProducerRecord的时候,生产者做的第一件事就是把key和value序列化成ByteArrays,以便他们可以通过网络发送。
2、接下来,数据会被发送到分区器,如果ProducerRecord中指定了分区,则分区器直接返回指定分区,否则,分区器通常会基于ProducerRecord的key值计算出一个分区,一旦分区被确认,生产者就知道数据会被发送到那个topic和分区,然后数据会被添加到同一批次发送到相同的topic和分区的数据里面,一个单独的线程会负责把那批数据发送到对应的broker上
3、当broker接收到数据之后,如果数据已被成功写入到kafka,会返回一个包含topic,分区和偏移量offset的recordMetdata对象,如果写入失败,会返回异常,当生产者接受到异常信息,会尝试重新发送,如果尝试失败则抛出异常
分区策略
1,分区的原因:
(1)方便在集群中扩展。每个分区可以通过调整来适应它所在的机器,而一个topic可以有多个分区组成,因此整个集群就可以适应任意大小的数据
(2)可以提高并发。因为可以以分区为单位读写。
2,分区的原则:
需要将producer发送的数据封装成一个ProducerRecord对象

(1)指明partition的情况下,直接将指明的值直接作为分区的值
(2)没有指明分区,但是指明key的情况下,将key的hash值与topic的 partition数进行取余得到partition值
(3)没有指明分区,也没有指明Key,第一次调用会随机生成一个整数(后面每次调用都在该整数上增加),将这个值与topic可用的partition综述取余得到分区值,也就是常说的round-robin(轮询算法)。
数据可靠性保证
为保证生产者发送数据,能可靠的发送到指定的topic,topic的每个分区收到数据之后,会给生产者返一个ack(ackonmledgement确认收到),生产者收到ack之后,就会进行下一轮的发送,否则会重新发送

1)副本数据同步策略

kafka选择第二种,原因:
(1)同样需要容忍n台几点出现故障,第一种需要2n+1个副本,第二种只需要n+1个副本,而且kafka每个分区有大量数据的话,第一种会造成大量数据的冗余
(2)第二种虽然延迟高,对kafka影响小
2)ISR(in-sync replace)已同步的副本
采用第二种,有一个问题:如果follower在同步数据的时候,有一个follower出现故障,迟迟不能与leader进行同步,那么leader就会一直等着,直到它完成,才能发送ack,这怎么半?
leader维护了一个动态的ISR,意为和leader保持同步的follower集合,当ISR中的follower完成数据同步之后,leader就会给follower发送ack,如果follower长时间未向leader同步数据,那么改follower会被ISR踢出去,这个时间限定通过replica.lag.time.max.ms参数设定,leader发生故障之后就会从ISR中选出了leader.
3)ack应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功,所以提供了三种可靠性级别
ack=0: 生产者不等待broker的ack,broker一接收还没有写入磁盘就已经返回,当broker故障可能造成数据丢失
ack=1:生产者等broker发送ack,分区的leader落盘成功后返回ack,如果在follower同步完成之前,leader出现故障,那么将会丢失数据
ack=-1:生产者等到borker发送ack,分区的leader和follower(ISR中的follower)全部落盘成功,才返回ack,但如果在follower全部落盘成功之后,broker发送ack之前,leader发生故障,会造成数据重复,还有一种极端情况,例如有三个副本,但ISR中只剩一个,就是其他两个同步特别慢的情况,就有可能造成数据丢失
4)故障细节处理
情况:leader写入了20条数据,两个follower分别写入13 和16条数据,此时leader挂掉,选择后两个任意一个做leader都有可能,这时数据就不一致了
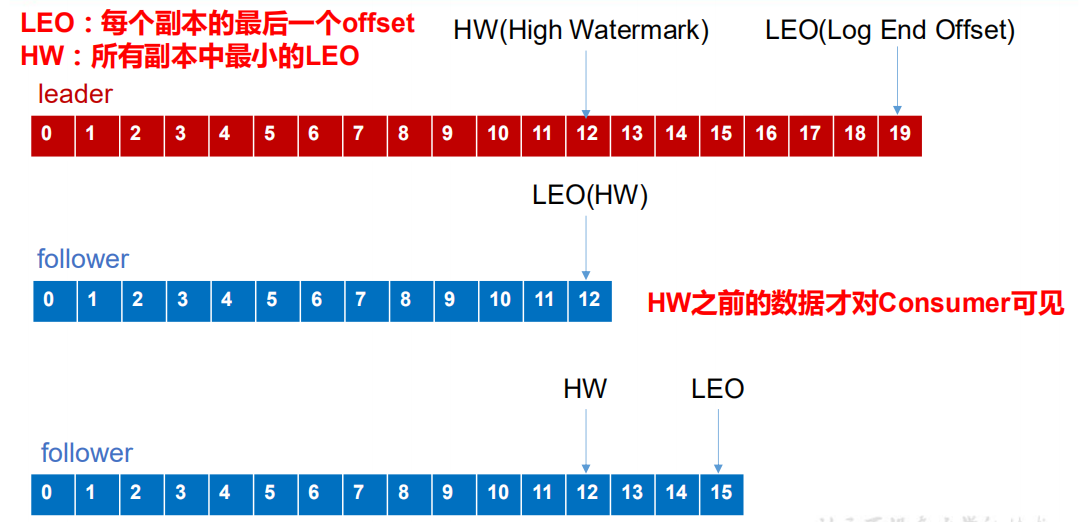
LEO:指的是每个副本的最大offset
HW:指的是消费者能见到的最大的offset,ISR中的最小的偏移量
(1)follower故障
follower发生故障之后会被临时剔除ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件中高于HW的部分截掉,从HW开始向leader同步,等该follower的LEO大于或等于该分区的HW,即follower重新追上leader之后,就可以重新加入ISR.
(2)leader故障
leader发生故障之后,会从 ISR 中选出一个新的 leader,之后,为保证多个副本之间的数据一致性,其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader同步数据。
Exactly Once 语义(精准一次性)
将服务器的ack设置为-1,可以保证生产者和server之间的数据不丢失,即At Least Once 语义
将ack设置成0,可以保证生产者每条数据只会被发送一次,保证数据不重复,即At Most Once语义
但是,对于一些非常重要的信息,要求即不重复也不丢失,即Exactly Once 语义
0.11版本之前无能为力,0.11版本的kafka,引入了一项重大特性:幂等性,所谓幂等性就是不论向server发送多少条重复数据,它都只持久化一条,幂等性结合At Least Once,就组成了Exactly Once语义;即:
At Least Once+ 幂等性=Exactly Once
要启用幂等性,只需要将producer的参数中enable.idompotence 设置为true即可,开启幂等性的生产者在初始化会被分配一个PID,发往同一分区的消息会被附带sequence Number ,而Broker 端会对<PID,partition,sequNumber>做缓存,当具有相同主键的消息提交时,broker会持久化一条,但是PId重启就会发生变化,幂等性无法保证跨分区跨会话的Exactly Once
创建生产者
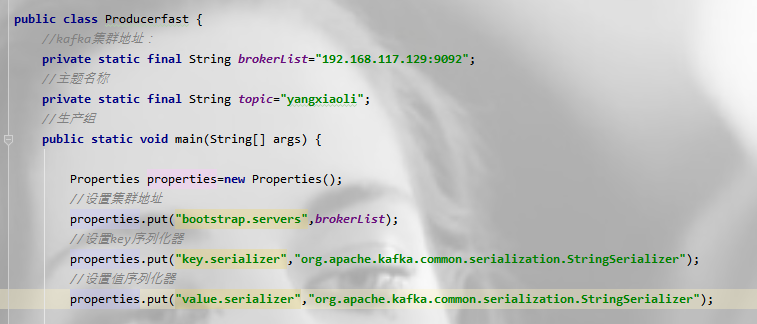
必须指定三个属性:
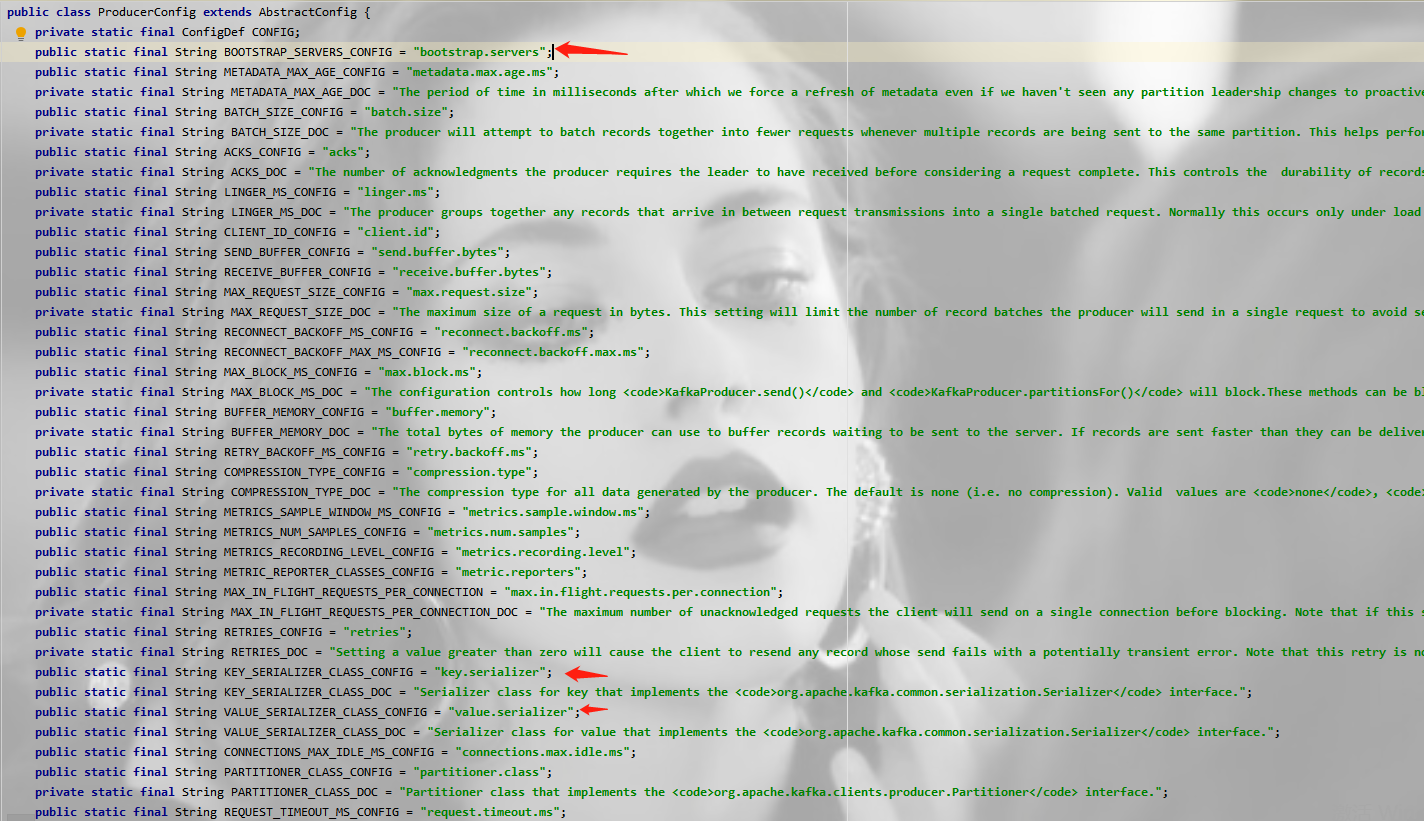
1.bootstarp.server:集群地址
2.key.serializer:用于序列化keys的类名,Kafka brokers期待key和value的类型为byte数组,但是也允许使用参数化的Java对象作为key和value。这使得代码非常易读,但也意味着生产者必须知道如何把这些对象转换为byte数组。key.serializer应设为实现了org.apache.kafka.common.serialization.Serializer接口的类名,生产者将会使用这个类来把key对象序列化为byte数组。Kafka内置实现了ByteArraySerializer、StringSerializer和IntegerSerializer。注意,即使生产者发送的数据没有指定key,也必须设置key.serializer这个属性。
3.value.serializer:用于序列化value的类名。类似于key.serializer,生产者将会使用指定的类来把value对象序列化为byte数组。
也可以通过ProducerConfig提取
点击ProducerConfig可以看看已经设置了相关配置
三、发送消息:
有两种类型,同步和异步
同步发送:通过send()发送完之后会返回一个Future对象,然后调用Future对象的get()方法等待kafka的响应,如果kafka正常响应,返回一个RecordMetadata对象,该对象存储消息的偏移量
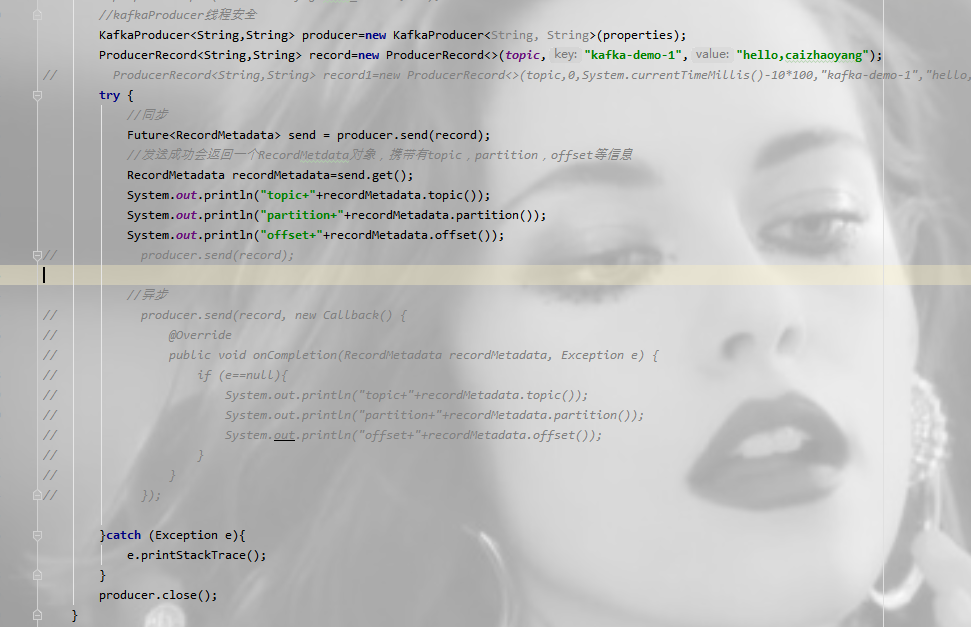

异步发送:异步相当于重新启动一个线程,不阻塞当前主流业务处理,异步发送,在调用send()方法的时候指定一个callback函数,当broker接收到返回的时候,该callback函数会被触发执行。

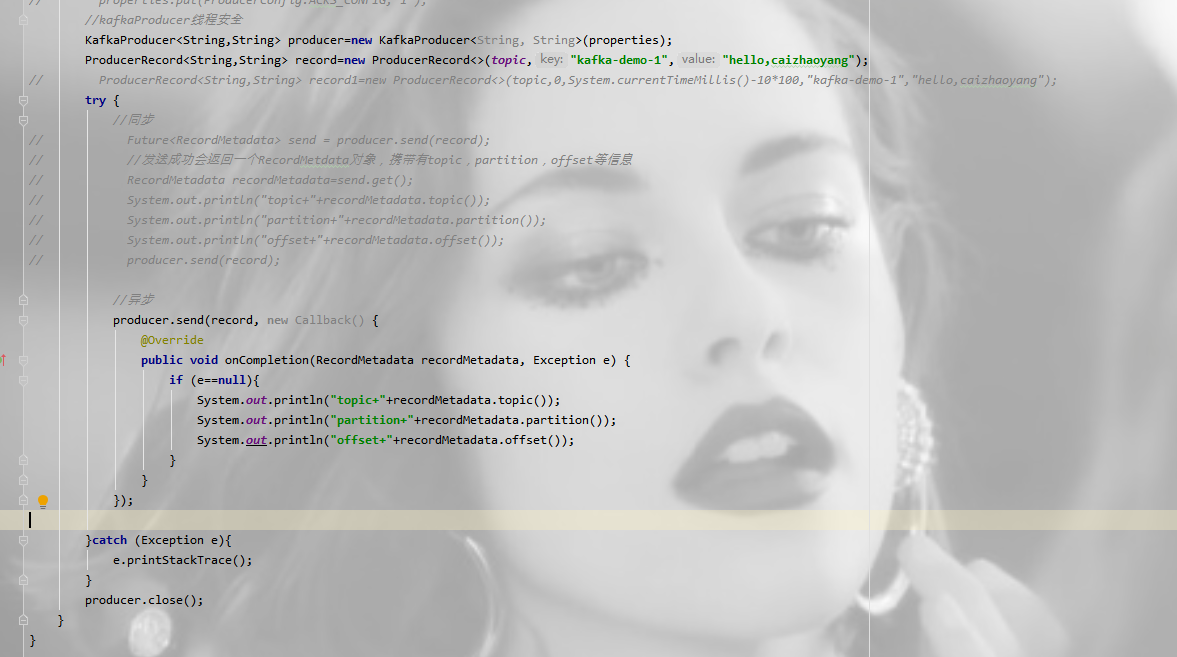
要使用callback函数,先要实现org.apache.kafka.clients.producer.Callback接口,该接口只有一个onCompletion方法。如果发送异常,onCompletion的参数Exception e会为非空。
四、生产者的其他配置属性
1、retries: 生产者从服务器收到的错误有可能是临时性的错误(例如:分区找不到首领)在这种情况下,如果达到了retries设置的次数,生产者会放弃重试,并返回错误,默认等行100ms,可以通过retry.backoff.ms参数来修改这个时间间隔
2、batch.size: 发送到同一个partition的消息会被先放在同一个批次中,该参数指定一个批次可以使用的内存大小,默认为16384=16KB,单位是byte。不一定需要等到batch被填满才能发送
3.max.request.size:用于控制生产者发送的请求大小,他可以指定能发送的单个消息的最大值,也可以指单个请求里所有的消息的总大小,broker对可接收的消息最大值也有自己的限制(message.max.size),所以两边的配置最好匹配,避免生产者发送的消息被broker拒绝
4、buffer.memory:设置生产者内缓存区域的大小,生产者用它缓冲要发送到服务器的消息。
5、linger.ms:生产者在发送消息前等待linger.ms,从而等待更多的消息加入到batch中。如果batch被填满或者linger.ms达到上限,就把batch中的消息发送出去
五、序列化器
1、作用:消息要到网络.上进行传输,必须进行序列化,而序列化器的作用就是如此。
Kafka提供了默认的字符串序列化器(org. apache.kafka.commonselalzation.StringSerillzer) .还有整型(IntegerSerializer)和字节数组(BytesSerializer) 序列化器,这些序列化器都实现了接口(org.apache.kafka.common.serialization.Serializer)基本上能够满足大部分场景的需求。
2、自定义序列化器
举例:kafka在消息传递的时候,消息主题是一个自定义的类
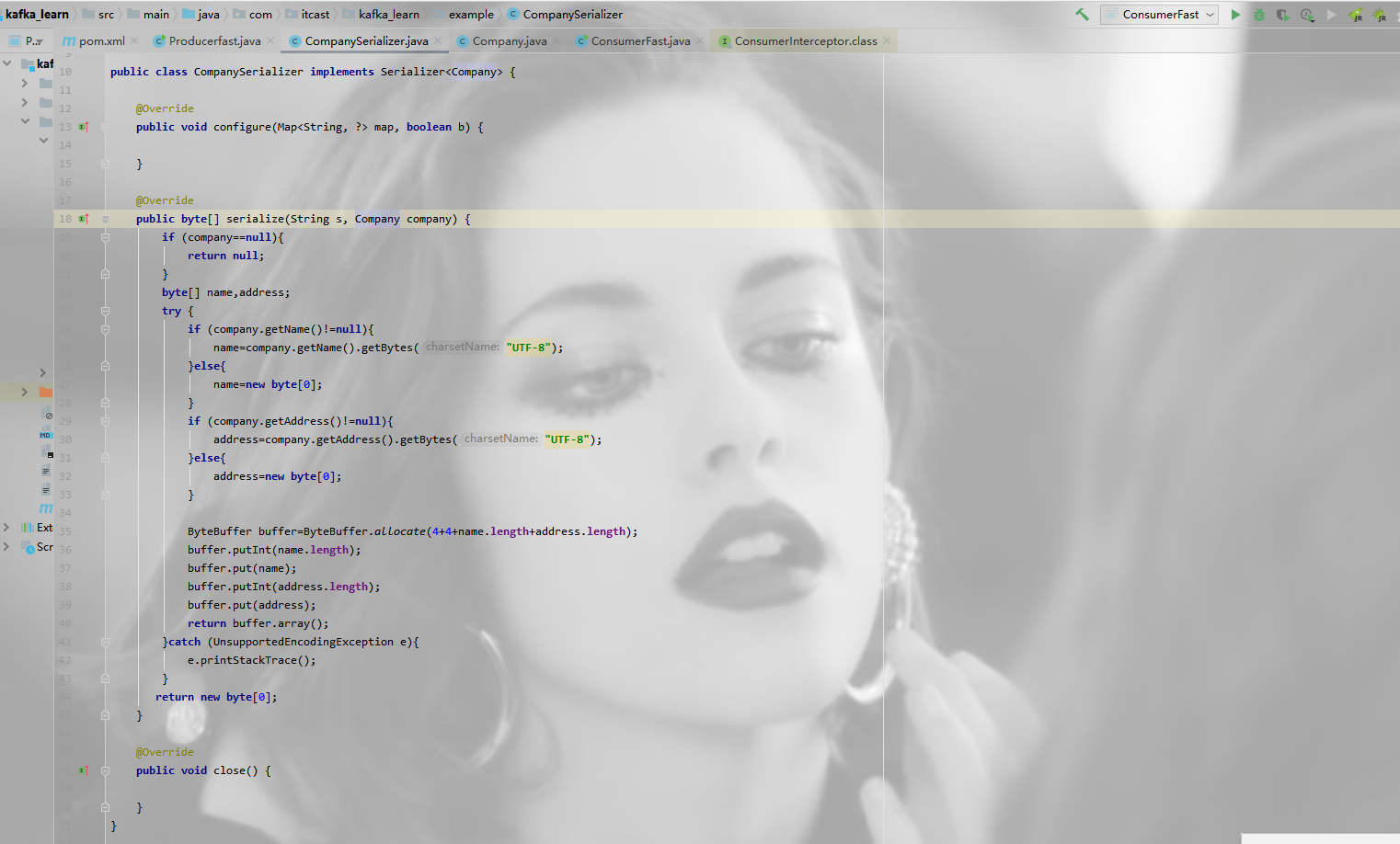
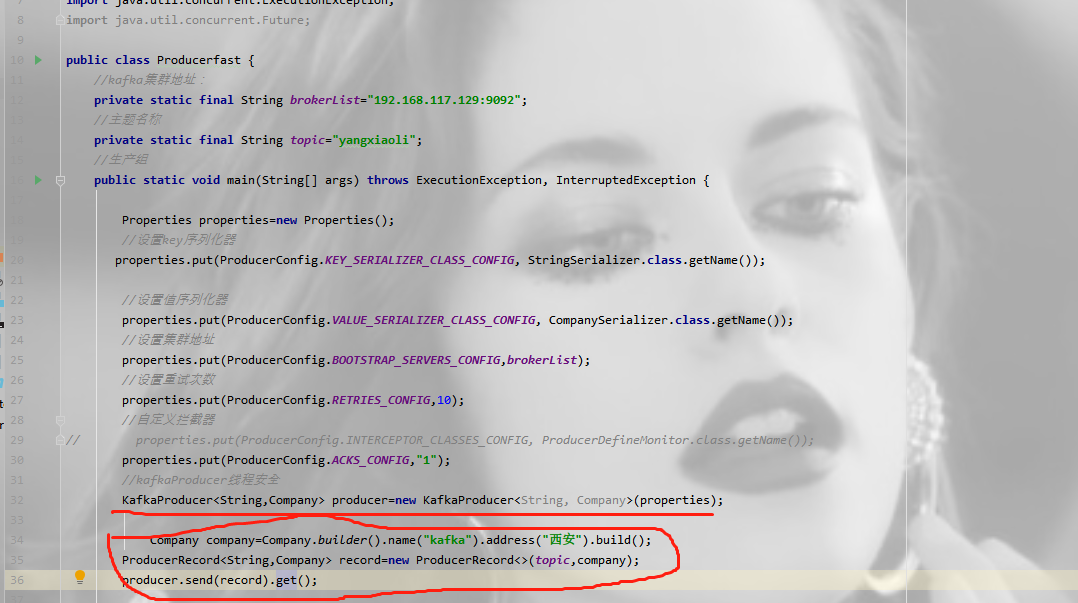
在创建ProducerRecord时,必须指定序列化器,推荐使用序列化框架Avro、Thrift、ProtoBuf等,不推荐自己创建序列化器。
在使用 Avro 之前,需要先定义模式(schema),模式通常使用 JSON 来编写。(该例子来自: https://www.cnblogs.com/sodawoods-blogs/p/8969513.html,方便学习)
举例2:
(1)创建一个类代表客户,作为消息的value

(2)定义schema

(3)生成Avro对象发送到Kafka

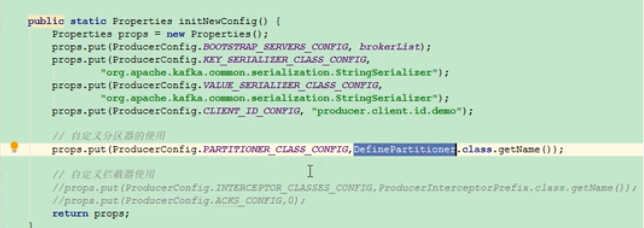
六、分区器
本身kafka有自己的分区策略的,如果未指定,就会使用默认的分区策略。
Kafka根据传递消息的key来进行分区的分配,即hash(key) % numPartitions.如果Key相同的话,那么就会分配到统一分区。一般情况采用默认

七、拦截器
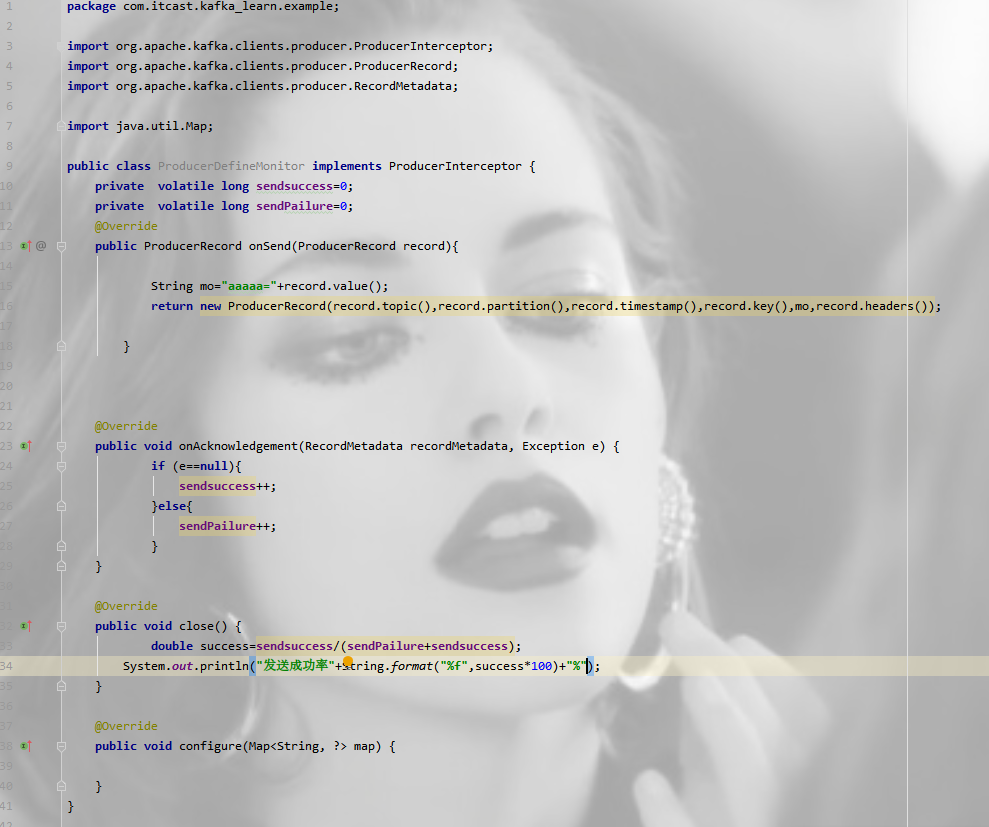
Producer拦截器(interceptor)是个相当新的功能,它和consumer端interceptor是 在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。
生产者拦截器可以用在消息发送前做一些准备工作。
使用场景:
1.按照某个规则过滤掉不符合要求的消息
2.修改消息的内容
3.统计类需求
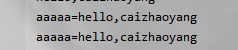
举例:发送所有的消息加前缀:

发送方:
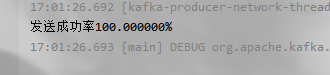
消费方结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号