字符串常量池和基本数据类型的包装类常量池
一.字符串常量池存放的地方
字符串常量池:在jdk1.6时,它存在于永久代
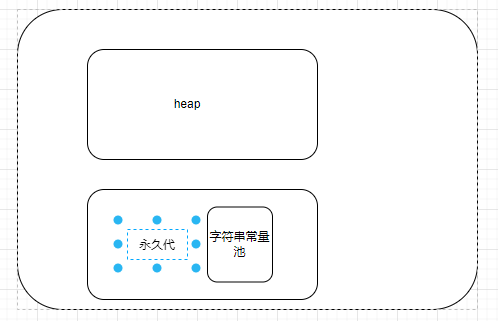
jdk1.7之后:
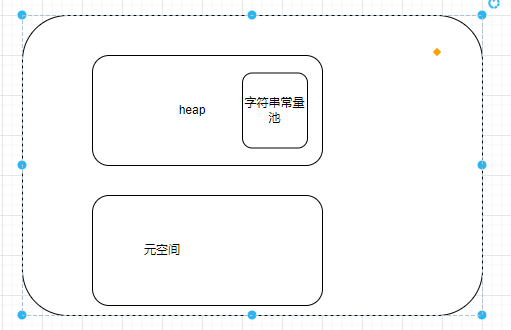
怎么验证:思路,我们只要不断的创建字符串对象,让其内存溢出,看看报错是在哪一块内存中即可
/** * jdk6:‐Xms6M ‐Xmx6M ‐XX:PermSize=6M ‐XX:MaxPermSize=6M * jdk8:‐Xms6M ‐Xmx6M ‐XX:MetaspaceSize=6M ‐XX:MaxMetaspaceSize=6M */ public class RuntimeConstantPoolOOM{ public static void main(String[] args) { ArrayList<String> list = new ArrayList<String>(); for (int i = 0; i < 10000000; i++) { String str = String.valueOf(i).intern(); list.add(str); } }

二. intern() 方法:
String s1 = new String("he") + new String("llo"); String s2 = s1.intern(); System.out.println(s1 == s2);
在 JDK 1.6 下输出是 false,创建了 6 个对象
在 JDK 1.7 及以上的版本输出是 true,创建了 5 个对象
当然我们这里没有考虑GC,但这些对象确实存在或存在过
首先上面的所示会创建多少个对象:
在jdk中: 字面量”he“ 和”llo“ 会在字符串常量池中分别创建一个对象,而 new String("he")和new String("llo") 分别会在堆中创建一个对象,字符串相加,底层是通过StringBuilder的toString()方法实现的,因此也会在堆中创建一个对象
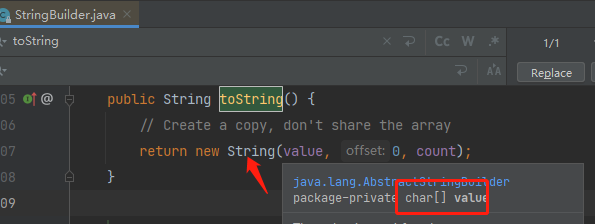
因此, String s1 = new String("he") + new String("llo"); 这行代码就创建了5个对象
现在不同的地方在于intern()方法:在jdk1.6时,s1.intern()方法会判断字符串常量池中有没“hello”这个字面量,如果没有,就会拷贝一份字面量到常量池中,而在jdk1.7以后,如果发现常量池中没有hello,它会将堆中的hello字符串的地址拷贝到
常量池中,因此在jdk1.6中会在常量池中创建多一个对象,而jdk1.7后则不会:

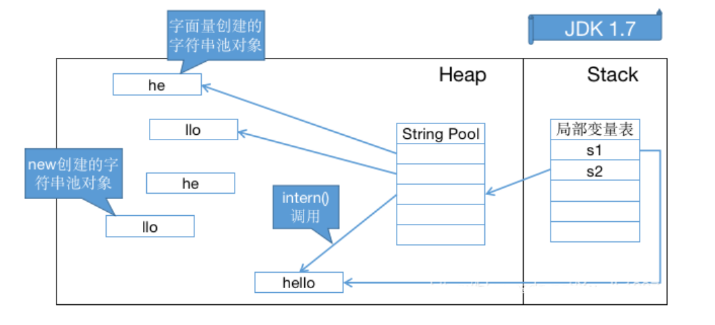
上面标红的地方要注意:下面举个例子(jdK1.8):
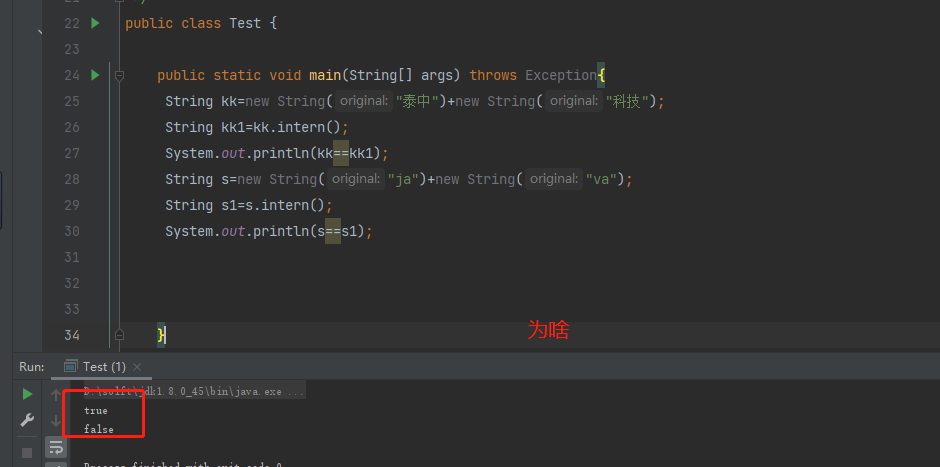
原因:在jdk1.8后,s1.intern()方法会判断字符串常量池存不存在s1的字面量,不存在就将s1在堆中的地址放到常量池,存在就不会放,很明显,“泰中科技”这个字符串在常量池中是不存在的,因此常量池会存它的在堆中的地址引用,
而“java”这个字符串,作为关键字,肯定已经存在字符串常量池中了,因此我们再次去调用intern()放法返回的地址是别人放到堆中的java字符串,因此结果是false
三:字符串常用的试题:
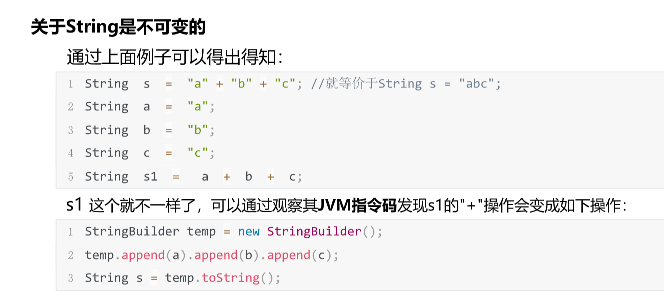
编译优化:字符串字面量相加,在编译期就会优化了,如下面的s2
String s0="zhuge"; //会在常量池中创建该对象 String s1="zhuge"; //常量池中已有该对象了 String s2="zhu" + "ge"; //编译其就会优化成”zhuge“ System.out.println( s0==s1 ); //true System.out.println( s0==s2 ); //true

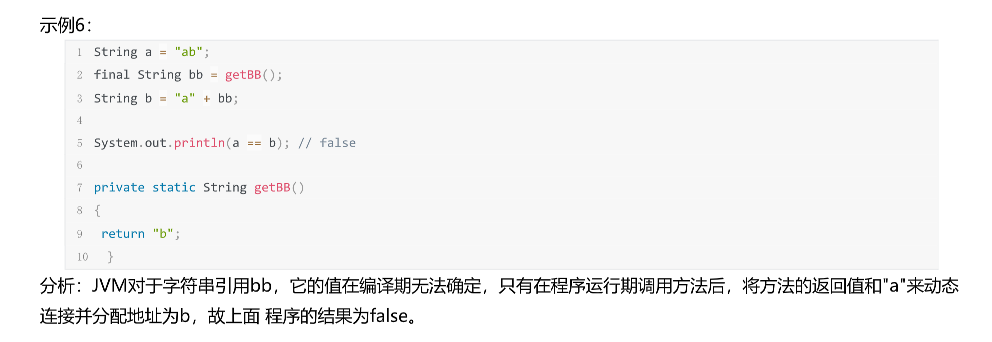
s2没法在编译期优化,因此在堆中创建一个新对象


引用是没法在编译期优化的 如上面的b

final修饰就是常量了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号