浅谈redis分布式锁的实现过程
说到分布式锁,我们都会想到setNx命令,存在就不更新,不存在就更新成功,根据这个命令,看如下代码有啥问题?

1.上面的分布式锁实现会出现的问题: 如果代码执行到减库存的操作,此时服务挂了,如断电了,那么就会导致死锁,其他线程永远都进不来了
解决方案:加个过期时间,如加了10s

2. 上面加了过期时间后,会有啥问题?如果代码刚执行到添加过期时间那里,就挂了,那么此时还是会死锁,所以需要加锁和设置过期时间是原子操作,因此改进:

3.上面这样实现后,会有啥问题?
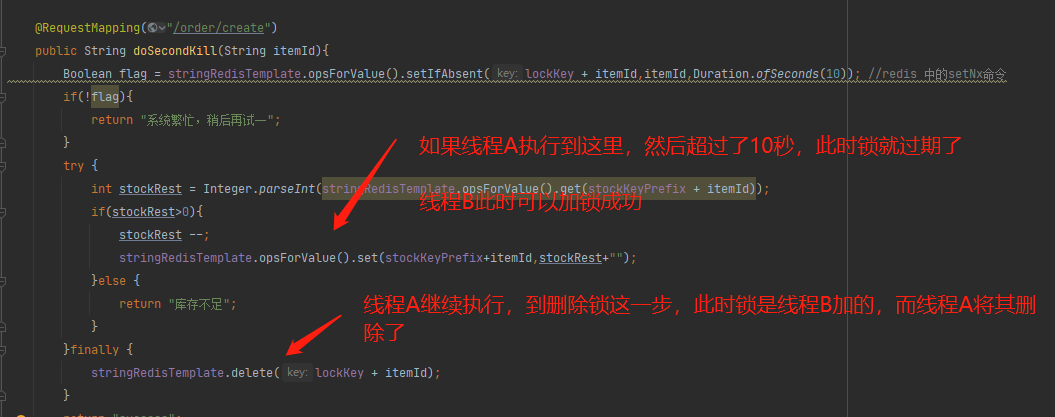
4.上面的问题就是因为线程A因为超时,然后删除了线程B的锁,解决方案,删除锁之前先判断是不是自己加的锁
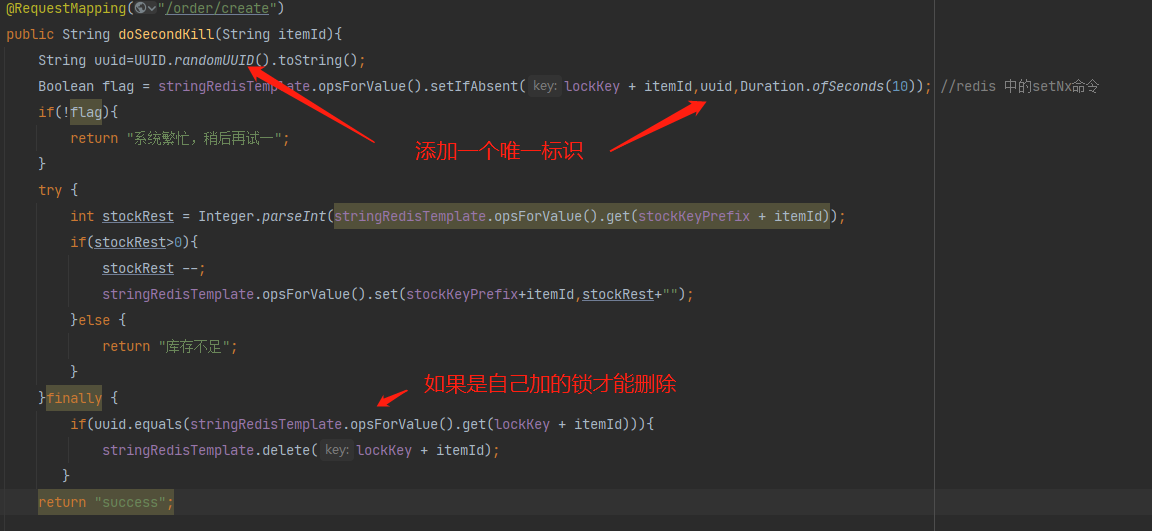
5.上面这样写能解决问题了吗?
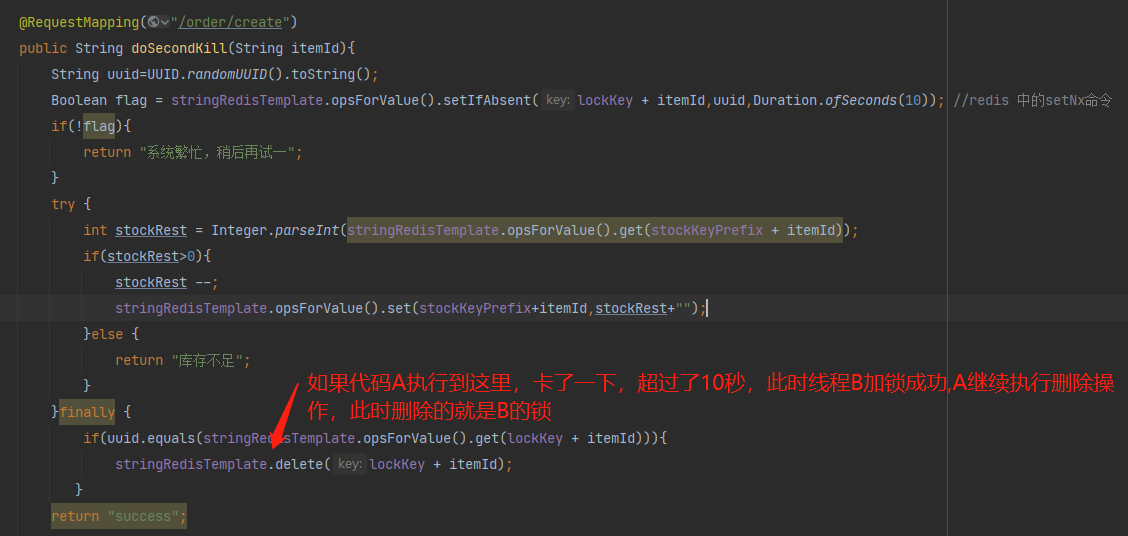
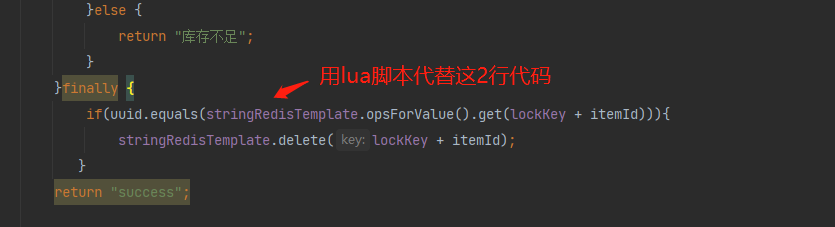
6. 如何解决上面问题?方案是要保证判断锁是否自己的和删除锁的操作是原子操作,此时可以使用lua脚本
7. 这些问题都解决后,还是会有问题,也就是最大的问题,key超时了
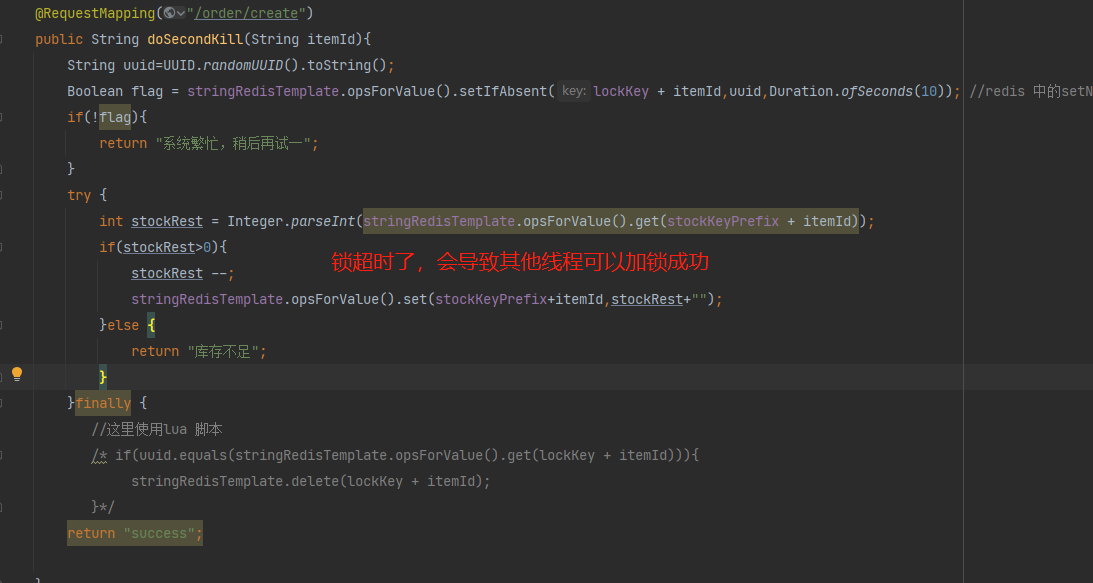
8. 如何解决:需要开一个线程,每隔一段时间就给锁进行续命
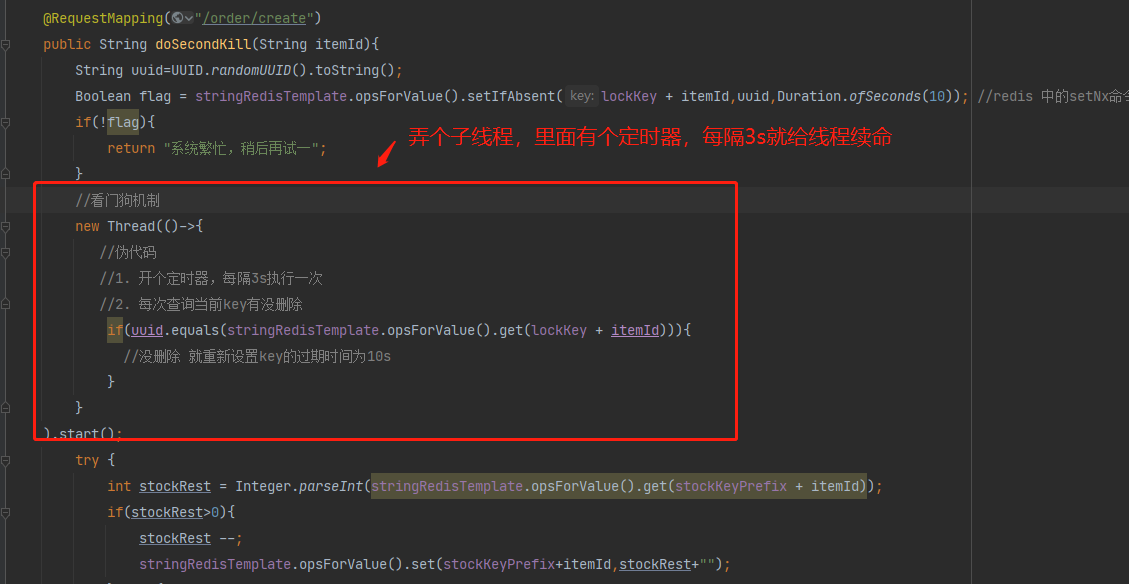
至此,redis分布式锁基本解决,但代码会非常复杂,还好,很多框架都实现了该逻辑,redis官网对这种实现方式定义了一种规范和一种称为redlock的算法,对应的java实现是redisson

我们改成redisson:
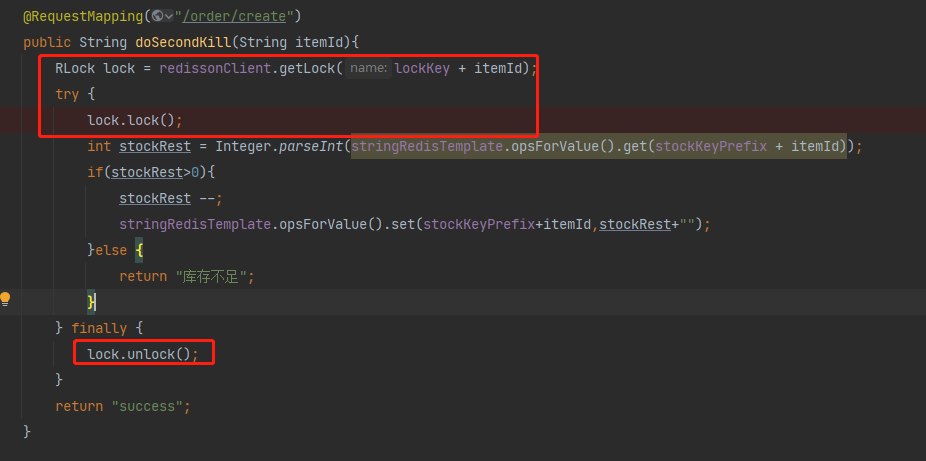
我们分析一下它的锁原理:
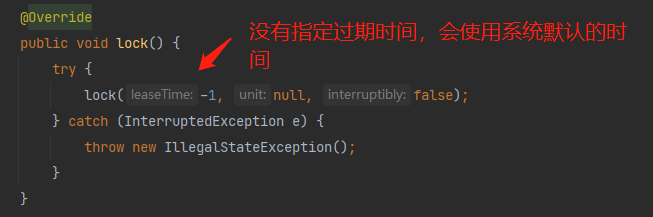

我们看看加锁过程:
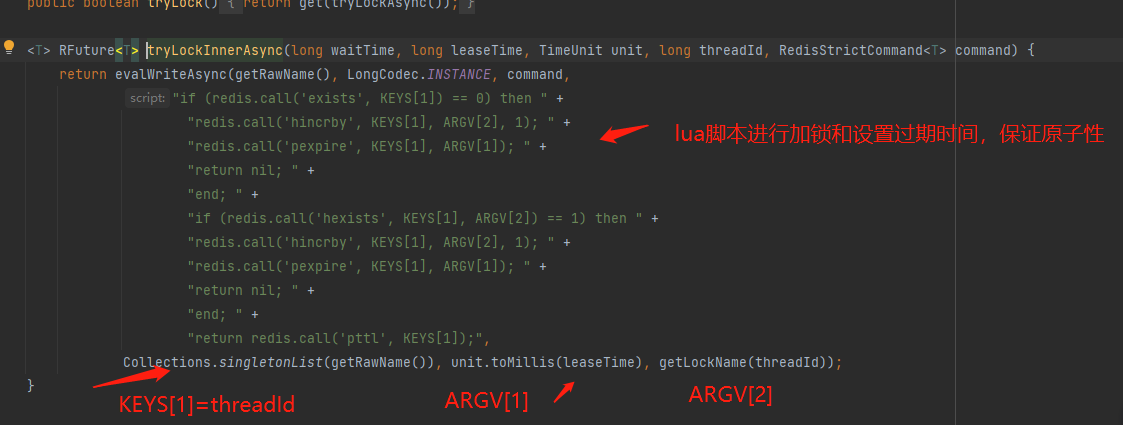
接着我们看看续约的逻辑: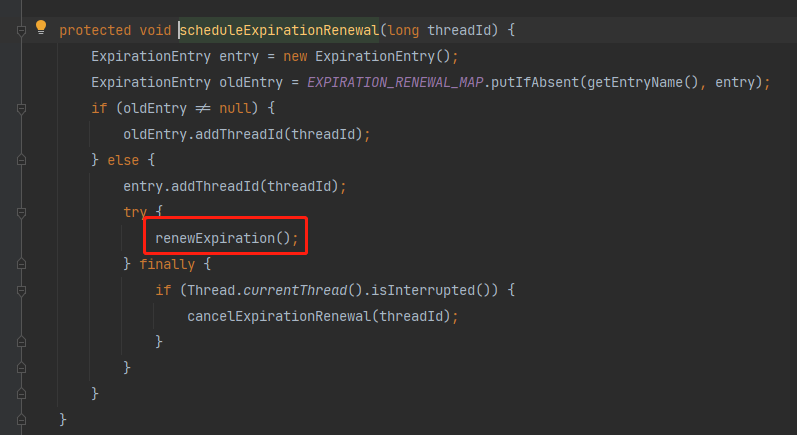
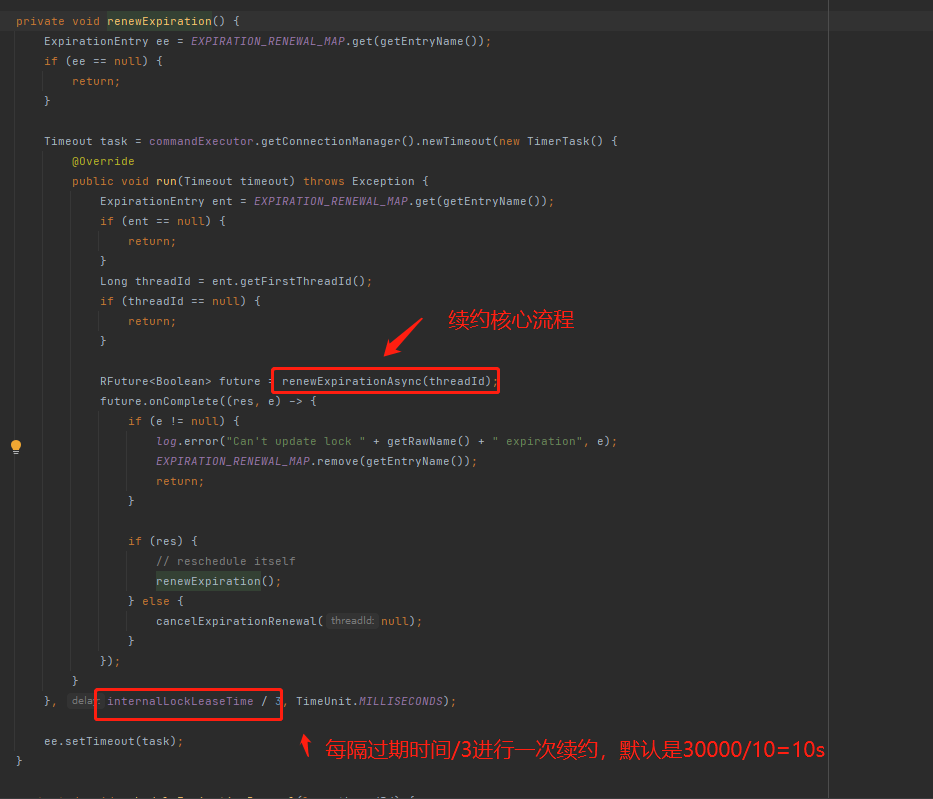
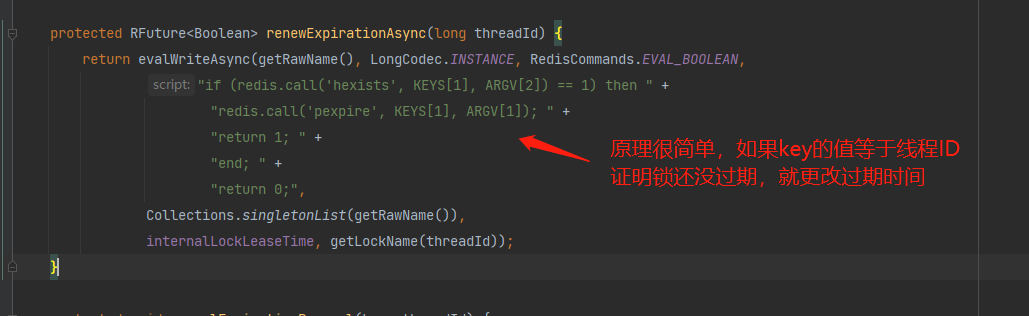
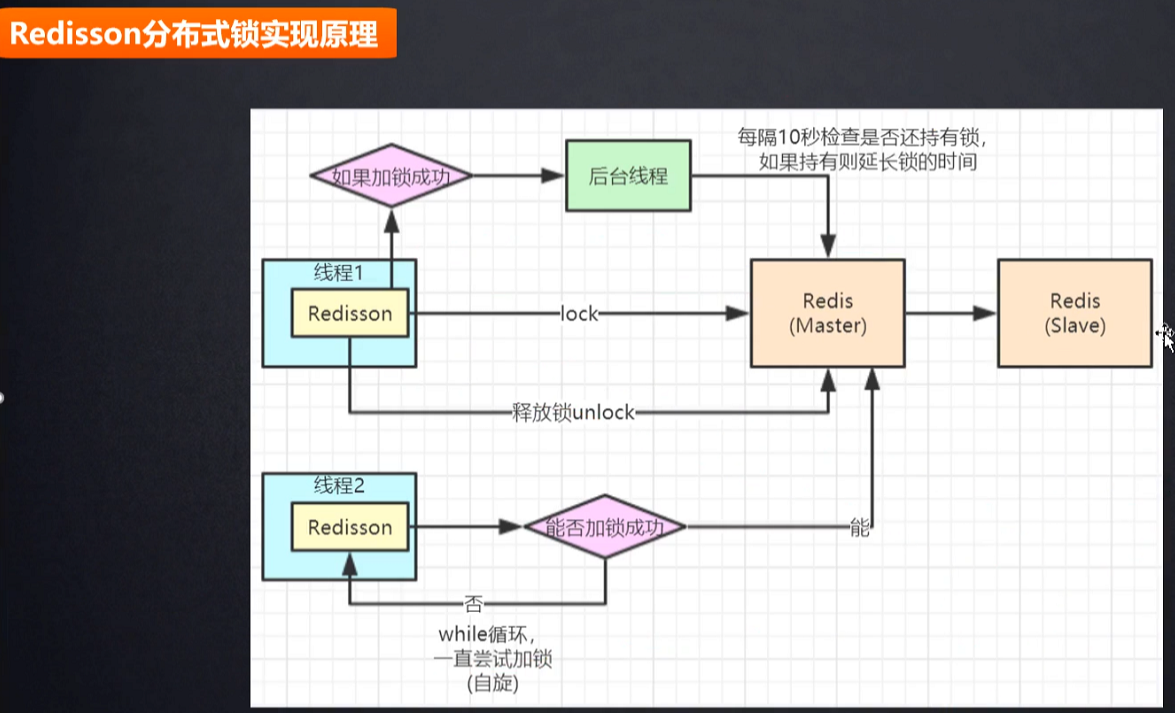
经过上面的分析,发现,加锁的原理和我们之前分析分布式锁的加锁原理基本一样;
之后我们看看解锁逻辑:
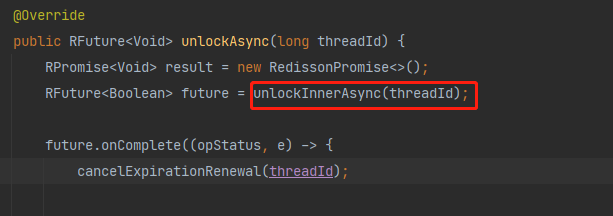
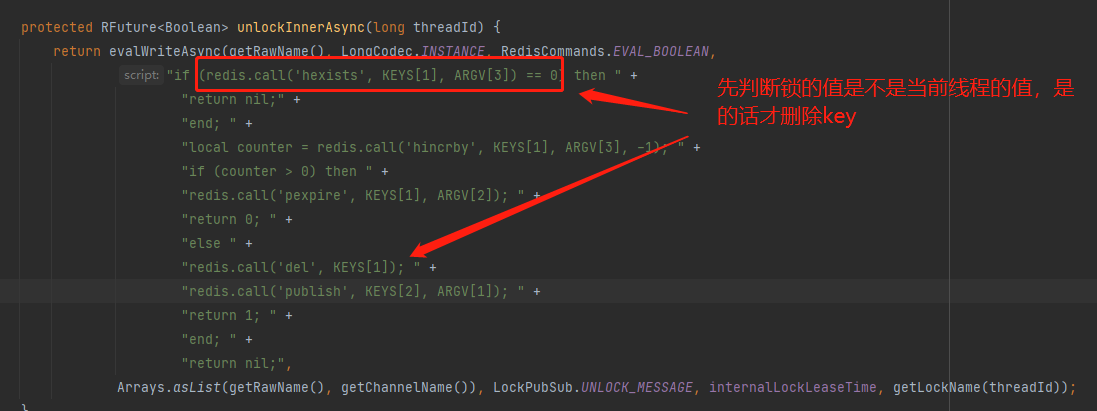
至此,我们分析完redis分布式锁的实现原理
锁丢失问题?
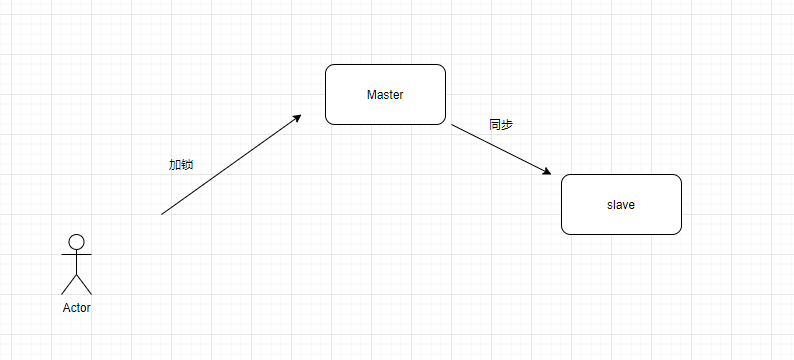
在redis主从或者哨兵模式下,加锁的逻辑是,只要主节点加锁成功,就是成功,那么,如果主节点挂了,数据还没同步到从节点的话,这样就会导致锁丢失,如何解决,有人提出了一种叫RedLock的算法:
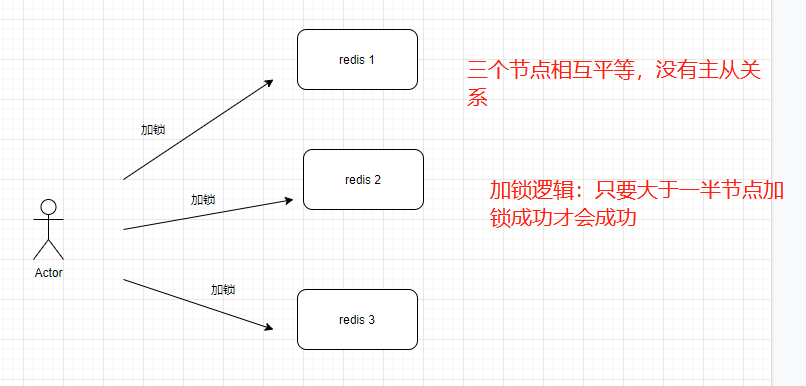
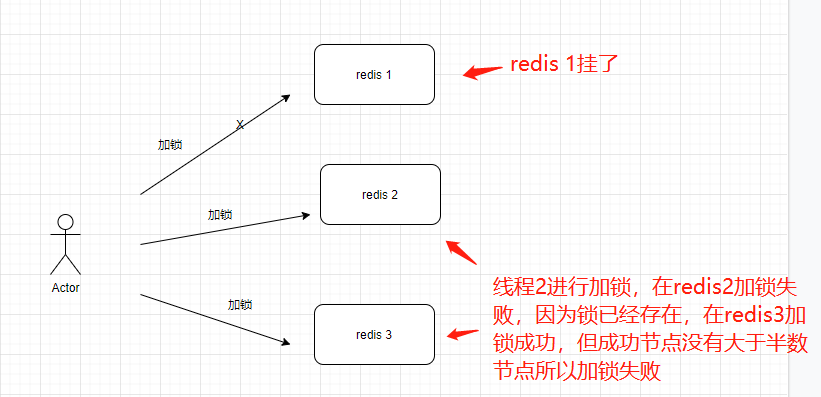
假如 redis1节点挂了,看看线程2能否加锁成功?
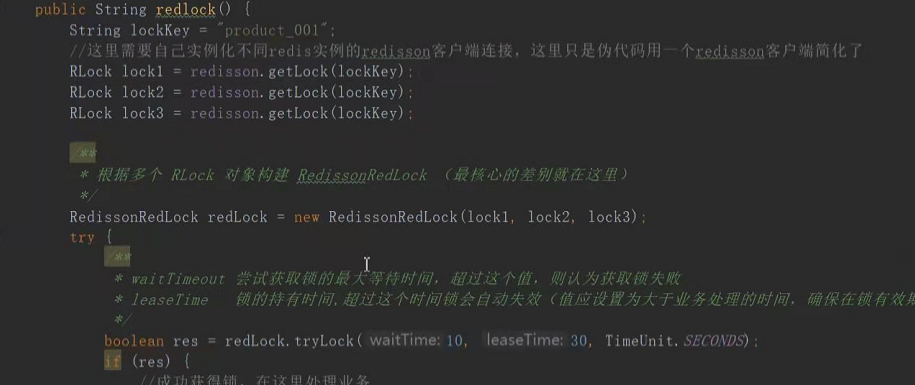
性能问题:加了分布式锁,性能肯定会慢,如何解决:可以参考ConcurrentHashMap分段加锁原理,如讲商品库存设置为多个分段,Item0-10 Item 10-20 ... ... 这样做后,只要锁其中的一个段就可以大大提升并发性了
缓存双写不一致问题?
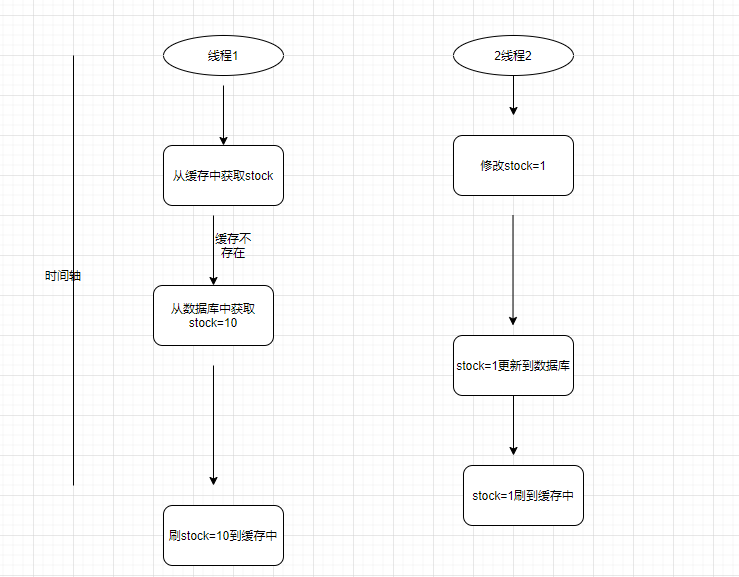
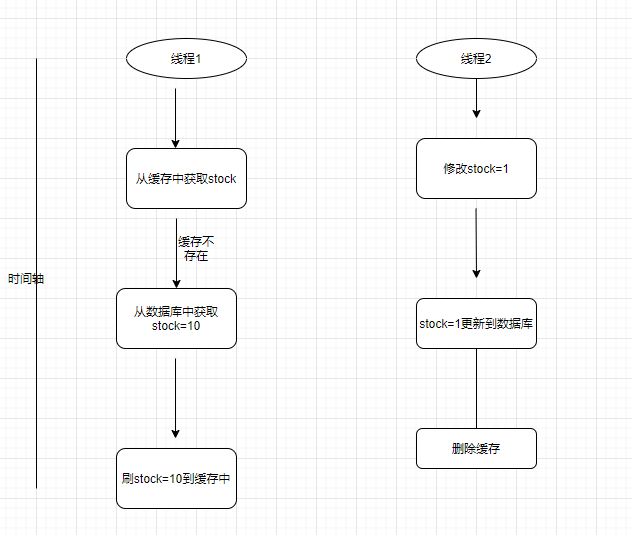
如上2种模式都会导致缓存不一致,如何解决,那就要用到我们说的分布式锁了
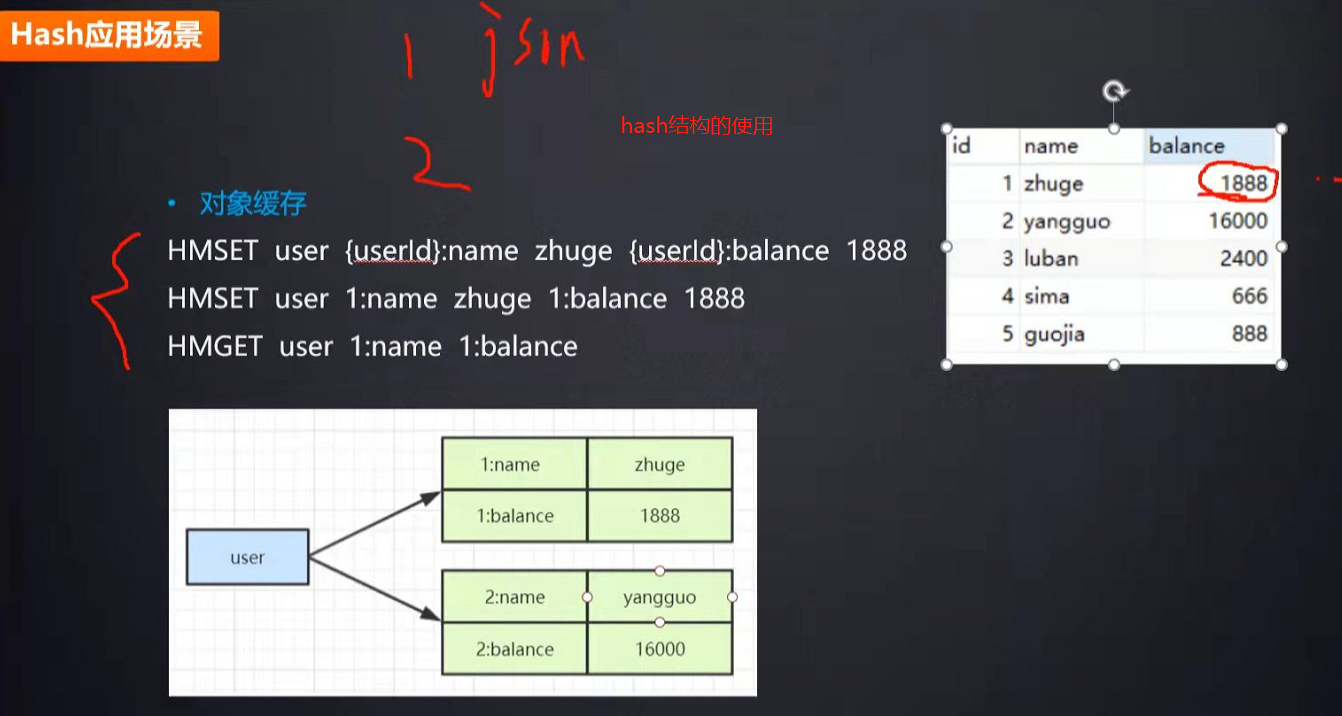
附加:redis hash结构和String结构存对象的区别,如果对象只更新某个属性,用hash比较方便,另外redis可以简单实现某些数据结构


 浙公网安备 33010602011771号
浙公网安备 33010602011771号