最近在看沐神《pytorch动手学深度学习》视频,本文记录一下自己跟着写的一个小实战。#
第一步:下载数据集#
提取码:l859#
我数据也是从别人那下的,自己没有去官网下。#
第二步:导入所需要的包#
numpy和pandas版本要和d2l的版本要正确对应,要不使用jupyter编写可能会出现内核中断问题。#
Copy
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
第三步:读取数据集#
读取数据#
Copy
train_data = pd.read_csv("data/kaggle_house/train.csv")
test_data = pd.read_csv("data/kaggle_house/test.csv")
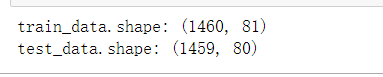
print("train_data.shape:",train_data.shape)
print("test_data.shape:",test_data.shape)
查看前四个和最后两个特征,以及相应标签(房价)#
Copy
print(test_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])
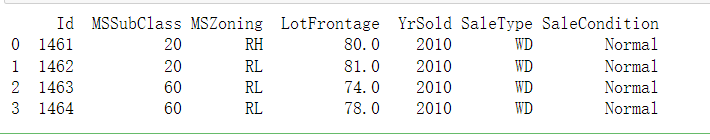
将第一个特征Id删除,并将训练集和测试集的特征数据结合起来(按行合并)。训练集不要最后的预测结果
Copy
all_features = pd.concat([train_data.iloc[:,1:-1], test_data.iloc[:,1:]],axis=0)
print(all_features.iloc[0:4,[0,1,2,3,-3,-2,-1]])

第四步:数据预处理#
数据中有连续型数据和离散型数据,并且存在缺失值。#
对应连续性数值,每列将所有缺失的值替换为相应特征的平均值。然后,为了将所有特征放在一个共同的尺度上, 我们通过将特征重新缩放到零均值和单位方差来标准化数据:#
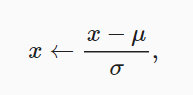
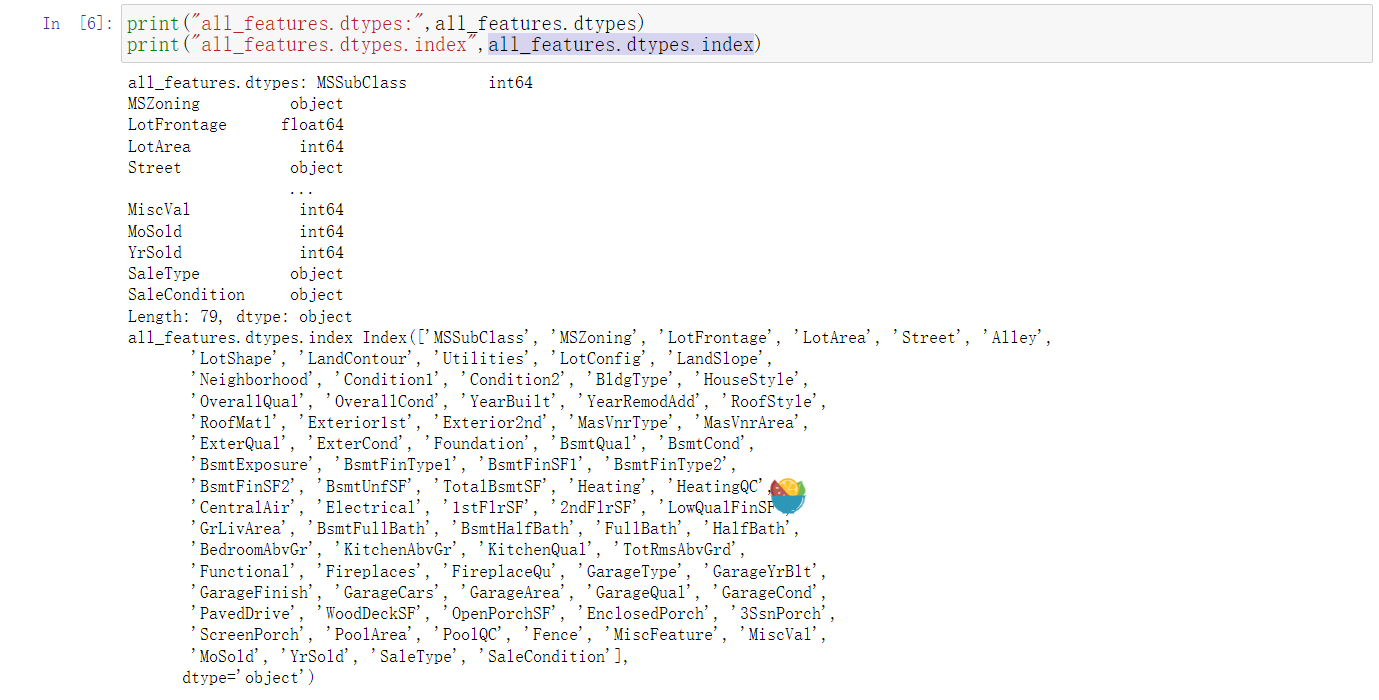
先看看all_features.dtypes和all_features.dtypes.index的输出#
Copy
"""
若无法获得测试数据,则可根据训练数据计算均值和标准差
"""
numeric_features = all_features.dtypes[all_features.dtypes != "object"].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / x.std()
)
all_features[numeric_features] = all_features[numeric_features].fillna(0)
而对于离散型数据,只需要把他转为one-hot格式。举个例子,比如地区一共有三个值[北京,上海,天津],此时地区特征就会变成三个特征,分别是北京,上海,天津。如果之前的值为北京,则北京列值为1,其他为0。相当于扩展了列个数。#
Copy
all_features = pd.get_dummies(all_features, dummy_na=True)
print("all_features.shape",all_features.shape)
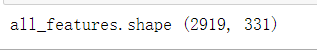
最后,通过values属性,提取numpy格式数据,并转换成tensor#
Copy
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1,1), dtype=torch.float32)
第五步:定义损失函数#
使用的是均方误差损失函数。但是视频说可能存在绝对数量的影响。比如一个房子值10.5W,但预测是0.5万,此时差出10W就是很不理想的。但是如果一个房子值1100W,但是最后预测是1090W,那个这个预测就还行。为了解决这个问题,将数值取对数,如下图。emmm,有一点没搞懂就是定义了这个函数,在模型训练时,并没有使用该函数,用的是MSELoss(),对于log_rmse()只是记录了使用对数损失函数的损失值。#
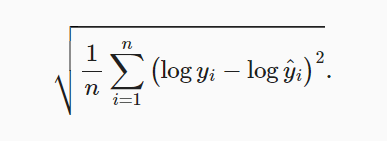
Copy
loss = nn.MSELoss()
def log_rmse(net, features, labels, return_item=True):
clipped_preds = torch.clamp(net(features),1,float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
if return_item:
return rmse.item()
else:
return rmse
第六步:定义模型#
模型使用的最简单的线性回归#
Copy
def get_net(in_features_num):
return nn.Sequential(nn.Linear(in_features_num, 1))
第七步:训练#
训练很简单,前向传播->计算损失->计算梯度->更新参数。之前看吴恩达老师的课是自己实现反向传播,沐神这个课是调用现有的API即可。#
Copy
def train(net, train_features, train_labels, test_features, test_labels, num_epochs, lr, wd, batch_size):
train_ls, test_ls = [], []
optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=wd)
train_iter = d2l.load_array((train_features, train_labels),batch_size)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
第八步:K折交叉验证(默认你知道K折交叉验证是什么意思)#
实现K折交叉验证,需要我们编写一个在折交叉验证过程中返回第i折的数据。#
Copy
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(i * fold_size, (i+1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid= X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], dim=0)
y_train = torch.cat([y_train, y_part], dim=0)
return X_train, y_train, X_valid, y_valid
K折交叉验证#
Copy
def k_fold(k, X_train, y_train, num_epochs, lr, wd, batch_size):
train_ls_sum, valid_ls_sum = 0, 0
for i in range(k):
data =get_k_fold_data(k, i, X_train, y_train)
net = get_net(X_train.shape[1])
train_ls, valid_ls = train(net, *data, num_epochs, lr, wd, batch_size)
train_ls_sum += train_ls[-1]
valid_ls_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
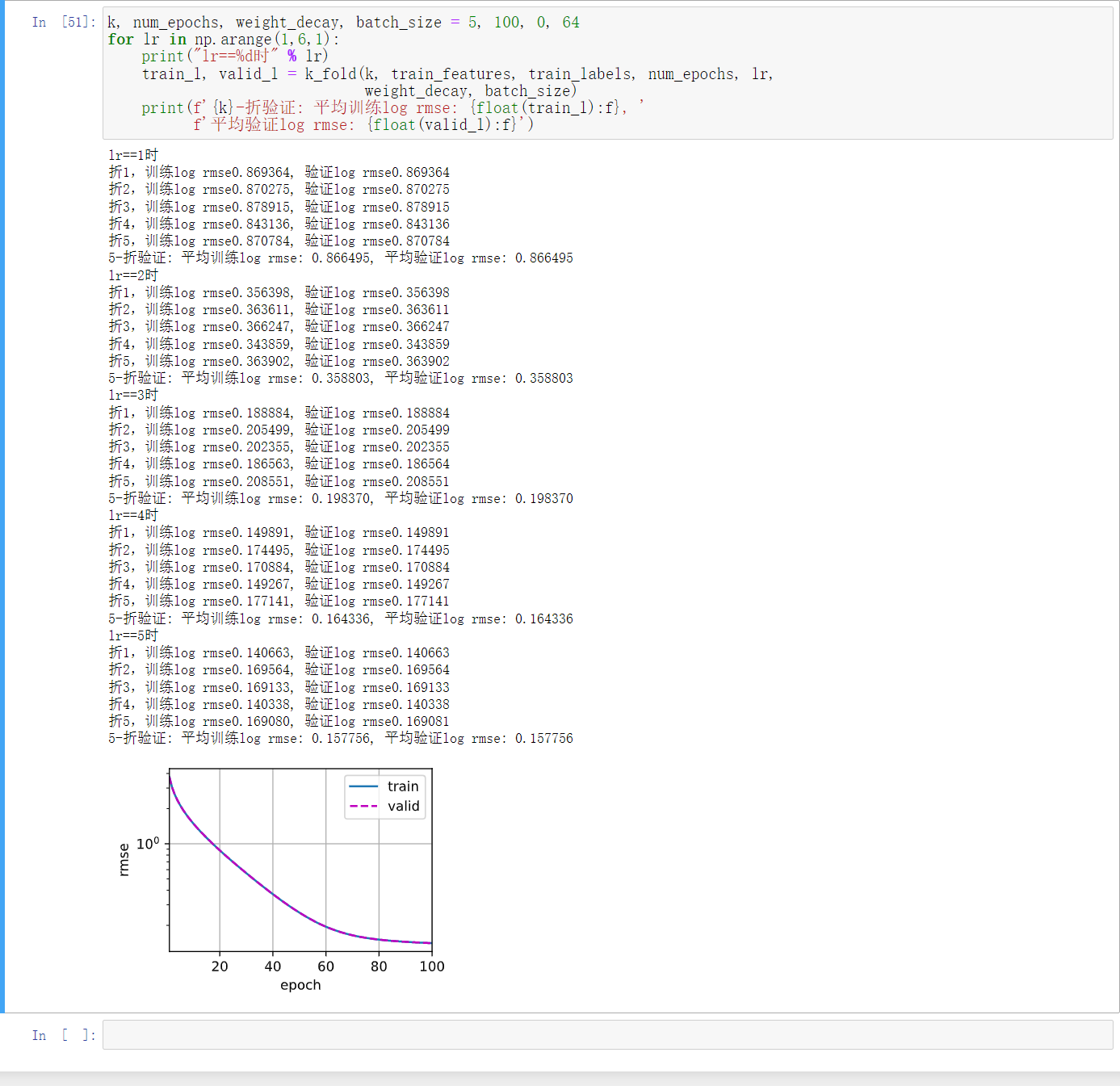
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_ls_sum / k, valid_ls_sum / k
最后:跑模型#
主要是调了一下学习率的参数。#
Copy
k, num_epochs, weight_decay, batch_size = 5, 100, 0, 64
for lr in np.arange(1,6,1):
print("lr==%d时" % lr)
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')


 实战Kaggle比赛:预测房价
实战Kaggle比赛:预测房价


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)