引言
接上一篇博客
正文
sample
-
函数签名:def sample(withReplacement: Boolean,fraction: Double,seed: Long = Utils.random.nextLong): RDD[T]
-
函数说明:根据指定的规则从数据集中抽取数据
案例:随机抽取数字
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Sample {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
/**
* 第一个参数表示:抽取后是否放回
* 第二个参数表示:如果不放回,则表示每个数抽取的概率 伯努利
* 如果返回,则表示每个数被抽取的可能次数 泊松算法
* 第三个参数表示:随机数种子,一旦随机数种子确定,抽取的数也就确定了
*/
println(rdd.sample(true, 0.4, 1).collect().mkString(","))
// TODO 关闭环境
sc.stop()
}
}
运行截图:

distinct
-
函数签名:
- def distinct()(implicit ord: Ordering[T] = null): RDD[T]
- def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
-
函数说明:将数据集中重复的数据去重
和scala里的list的distinct区别。spark看代码解释
- scala底层调用了HashSet
- spark:map(x => (x, null)).reduceByKey((x, ) => x, numPartitions).map(._1)
案例:去重
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Distinct {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 3, 4))
/**
* 数据去重
* 底层原理:
* map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
* 1、 1, 2, 3, 4, 1, 2, 3, 4
* 2、(1,null),(2,null),(3,null),(4,null),(1,null),(2,null),(3,null),(4,null)
* 3、(1,null),(2,null),(3,null),(4,null)
* 4、1, 2, 3, 4
*/
rdd.distinct().collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}
运行截图:

coalesce
-
函数签名:def coalesce(numPartitions: Int, shuffle: Boolean = false,partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T]
-
函数说明:根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少分区的个数,减小任务调度成本
案例:减少分区个数。代码有注释解释
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Coalesce {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4,5,6),numSlices = 3)
/**
* 减少分区个数
* 第一个参数表示:分区的个数
* 第二个参数表示:是否均衡分配
* false:不均衡,那么之前的分区数据不会分开 (1,2) (3,4) (5,6)三个分区变成两个分区--->(1,2) (3,4,5,6)
* true:调用shuffle打乱数据重新分配 (1,2) (3,4) (5,6)三个分区变成两个分区,数据会打乱,重新改分配 ---->(1,4,5) (2,3,6)
*/
val coalesceRDD: RDD[Int] = rdd.coalesce(2)
coalesceRDD.saveAsTextFile("output")
// TODO 关闭环境
sc.stop()
}
}
运行截图:
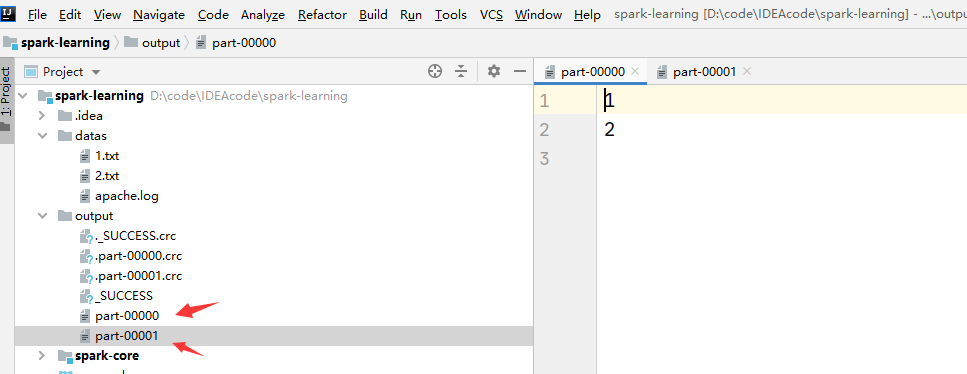
repartition
-
函数签名:def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
-
函数说明:该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。无论是将分区数多的RDD 转换为分区数少的 RDD,还是将分区数少的 RDD 转换为分区数多的 RDD,repartition操作都可以完成,因为无论如何都会经 shuffle 过程
案例:
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_Repartition {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4,5,6),numSlices = 2)
/**
* coalesce(分区个数,true),可以实现扩大分区个数。必须采用shuffle,否则没有意义。
* 因为coalesce方法中同一个分区的数据不会分开,只有采用shuffle将数据打乱,才可以实现增加分区个数
*/
/**
* 扩大分区个数
* 第一个参数表示:分区的个数
* 底层采用的是:coalesce(分区个数,是否采用shuffle)
*/
val repartitionRDD: RDD[Int] = rdd.repartition(3)
repartitionRDD.saveAsTextFile("output")
// TODO 关闭环境
sc.stop()
}
}
运行截图:
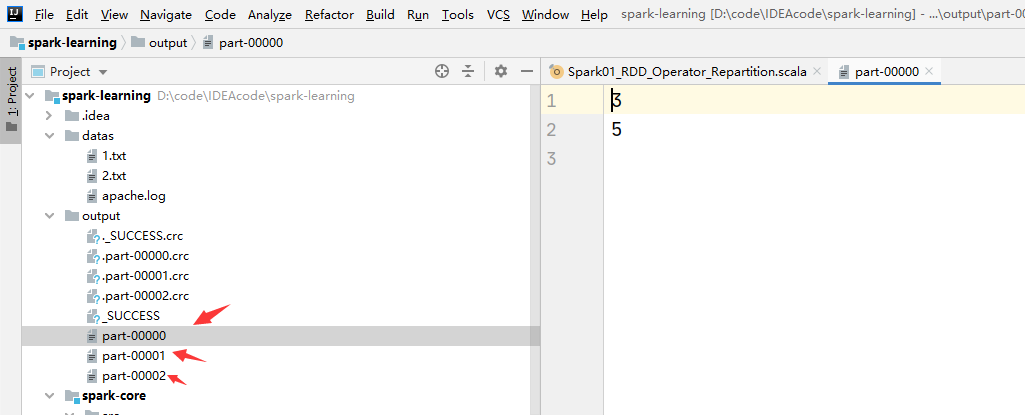
sortBy
-
函数签名:def sortBy[K](f: (T) => K,ascending: Boolean = true,numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
-
函数说明:该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原 RDD 的分区数一致。中间存在 shuffle 的过程
案例:
package com.xiao.spark.core.rdd.operator.tranform
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Operator_SortBy {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val sc = new SparkContext(sparkConf)
// Int类型排序
//val rdd: RDD[Int] = sc.makeRDD(List(1, 4,3,6,7,2,5))
// 元组进行排序
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("1", 20), ("4", 15), ("24", 2)))
/**
* 对数据进行排序,第一个参数为排序数据,第二个参数是否为升序,默认是升序
*/
//按key值排序
//rdd.sortBy(t=>t._1).collect().foreach(println)
//按value值排序
rdd.sortBy(t=>t._2,false).collect().foreach(println)
// TODO 关闭环境
sc.stop()
}
}
运行截图:
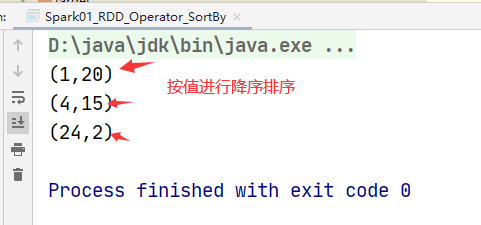

 浙公网安备 33010602011771号
浙公网安备 33010602011771号